 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Test-Taking to Test-Making: Examining LLM Authoring of Commonsense Assessment Items
Oct 18, 2024LLMs can now perform a variety of complex writing tasks. They also excel in answering questions pertaining to natural language inference and commonsense reasoning. Composing these questions is itself a skilled writing task, so in this paper we consider LLMs as authors of commonsense assessment items. We prompt LLMs to generate items in the style of a prominent benchmark for commonsense reasoning, the Choice of Plausible Alternatives (COPA). We examine the outcome according to analyses facilitated by the LLMs and human annotation. We find that LLMs that succeed in answering the original COPA benchmark are also more successful in authoring their own items.
An Adaptation of Topic Modeling to Sentences
Jul 20, 2016
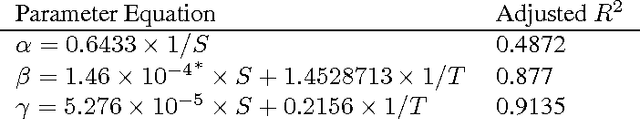
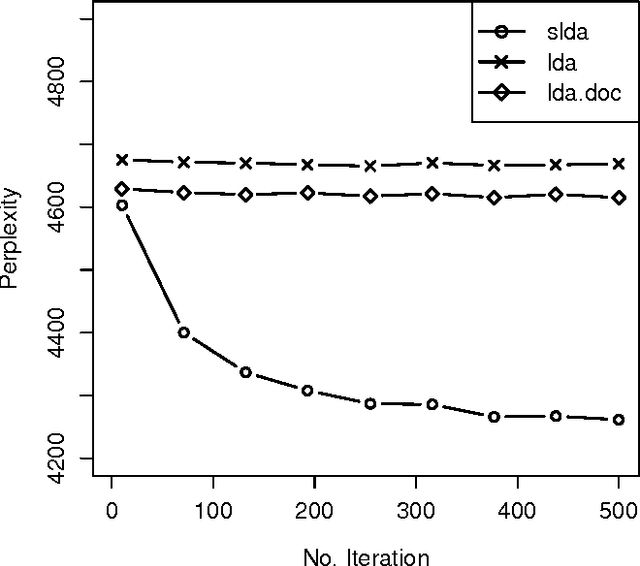
Advances in topic modeling have yielded effective methods for characterizing the latent semantics of textual data. However, applying standard topic modeling approaches to sentence-level tasks introduces a number of challenges. In this paper, we adapt the approach of latent-Dirichlet allocation to include an additional layer for incorporating information about the sentence boundaries in documents. We show that the addition of this minimal information of document structure improves the perplexity results of a trained model.