 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoToM: Automated Bayesian Inverse Planning and Model Discovery for Open-ended Theory of Mind
Feb 21, 2025



Theory of Mind (ToM), the ability to understand people's mental variables based on their behavior, is key to developing socially intelligent agents. Current approaches to Theory of Mind reasoning either rely on prompting Large Language Models (LLMs), which are prone to systematic errors, or use rigid, handcrafted Bayesian Theory of Mind (BToM) models, which are more robust but cannot generalize across different domains. In this work, we introduce AutoToM, an automated Bayesian Theory of Mind method for achieving open-ended machine Theory of Mind. AutoToM can operate in any domain, infer any mental variable, and conduct robust Theory of Mind reasoning of any order. Given a Theory of Mind inference problem, AutoToM first proposes an initial BToM model. It then conducts automated Bayesian inverse planning based on the proposed model, leveraging an LLM as the backend. Based on the uncertainty of the inference, it iteratively refines the model, by introducing additional mental variables and/or incorporating more timesteps in the context. Empirical evaluations across multiple Theory of Mind benchmarks demonstrate that AutoToM consistently achieves state-of-the-art performance, offering a scalable, robust, and interpretable approach to machine Theory of Mind.
OS-Genesis: Automating GUI Agent Trajectory Construction via Reverse Task Synthesis
Dec 27, 2024



Graphical User Interface (GUI) agents powered by Vision-Language Models (VLMs) have demonstrated human-like computer control capability. Despite their utility in advancing digital automation, a critical bottleneck persists: collecting high-quality trajectory data for training. Common practices for collecting such data rely on human supervision or synthetic data generation through executing pre-defined tasks, which are either resource-intensive or unable to guarantee data quality. Moreover, these methods suffer from limited data diversity and significant gaps between synthetic data and real-world environments. To address these challenges, we propose OS-Genesis, a novel GUI data synthesis pipeline that reverses the conventional trajectory collection process. Instead of relying on pre-defined tasks, OS-Genesis enables agents first to perceive environments and perform step-wise interactions, then retrospectively derive high-quality tasks to enable trajectory-level exploration. A trajectory reward model is then employed to ensure the quality of the generated trajectories. We demonstrate that training GUI agents with OS-Genesis significantly improves their performance on highly challenging online benchmarks. In-depth analysis further validates OS-Genesis's efficiency and its superior data quality and diversity compared to existing synthesis methods. Our codes, data, and checkpoints are available at \href{https://qiushisun.github.io/OS-Genesis-Home/}{OS-Genesis Homepage}.
Beyond the Binary: Capturing Diverse Preferences With Reward Regularization
Dec 05, 2024


Large language models (LLMs) are increasingly deployed via public-facing interfaces to interact with millions of users, each with diverse preferences. Despite this, preference tuning of LLMs predominantly relies on reward models trained using binary judgments where annotators select the preferred choice out of pairs of model outputs. In this work, we argue that this reliance on binary choices does not capture the broader, aggregate preferences of the target user in real-world tasks. We propose a taxonomy that identifies two dimensions of subjectivity where different users disagree on the preferred output-namely, the Plurality of Responses to Prompts, where prompts allow for multiple correct answers, and the Indistinguishability of Responses, where candidate outputs are paraphrases of each other. We show that reward models correlate weakly with user preferences in these cases. As a first step to address this issue, we introduce a simple yet effective method that augments existing binary preference datasets with synthetic preference judgments to estimate potential user disagreement. Incorporating these via a margin term as a form of regularization during model training yields predictions that better align with the aggregate user preferences.
MuMA-ToM: Multi-modal Multi-Agent Theory of Mind
Aug 22, 2024Understanding people's social interactions in complex real-world scenarios often relies on intricate mental reasoning. To truly understand how and why people interact with one another, we must infer the underlying mental states that give rise to the social interactions, i.e., Theory of Mind reasoning in multi-agent interactions. Additionally, social interactions are often multi-modal -- we can watch people's actions, hear their conversations, and/or read about their past behaviors. For AI systems to successfully and safely interact with people in real-world environments, they also need to understand people's mental states as well as their inferences about each other's mental states based on multi-modal information about their interactions. For this, we introduce MuMA-ToM, a Multi-modal Multi-Agent Theory of Mind benchmark. MuMA-ToM is the first multi-modal Theory of Mind benchmark that evaluates mental reasoning in embodied multi-agent interactions. In MuMA-ToM, we provide video and text descriptions of people's multi-modal behavior in realistic household environments. Based on the context, we then ask questions about people's goals, beliefs, and beliefs about others' goals. We validated MuMA-ToM in a human experiment and provided a human baseline. We also proposed a novel multi-modal, multi-agent ToM model, LIMP (Language model-based Inverse Multi-agent Planning). Our experimental results show that LIMP significantly outperforms state-of-the-art methods, including large multi-modal models (e.g., GPT-4o, Gemini-1.5 Pro) and a recent multi-modal ToM model, BIP-ALM.
How Far Are We From AGI
May 16, 2024



The evolution of artificial intelligence (AI) has profoundly impacted human society, driving significant advancements in multiple sectors. Yet, the escalating demands on AI have highlighted the limitations of AI's current offerings, catalyzing a movement towards Artificial General Intelligence (AGI). AGI, distinguished by its ability to execute diverse real-world tasks with efficiency and effectiveness comparable to human intelligence, reflects a paramount milestone in AI evolution. While existing works have summarized specific recent advancements of AI, they lack a comprehensive discussion of AGI's definitions, goals, and developmental trajectories. Different from existing survey papers, this paper delves into the pivotal questions of our proximity to AGI and the strategies necessary for its realization through extensive surveys, discussions, and original perspectives. We start by articulating the requisite capability frameworks for AGI, integrating the internal, interface, and system dimensions. As the realization of AGI requires more advanced capabilities and adherence to stringent constraints, we further discuss necessary AGI alignment technologies to harmonize these factors. Notably, we emphasize the importance of approaching AGI responsibly by first defining the key levels of AGI progression, followed by the evaluation framework that situates the status-quo, and finally giving our roadmap of how to reach the pinnacle of AGI. Moreover, to give tangible insights into the ubiquitous impact of the integration of AI, we outline existing challenges and potential pathways toward AGI in multiple domains. In sum, serving as a pioneering exploration into the current state and future trajectory of AGI, this paper aims to foster a collective comprehension and catalyze broader public discussions among researchers and practitioners on AGI.
MMToM-QA: Multimodal Theory of Mind Question Answering
Jan 16, 2024



Theory of Mind (ToM), the ability to understand people's minds, is an essential ingredient for developing machines with human-level social intelligence. Recent machine learning models, particularly large language models, seem to show some aspects of ToM understanding. However, existing ToM benchmarks use unimodal datasets - either video or text. Human ToM, on the other hand, is more than video or text understanding. People can flexibly reason about another person's mind based on conceptual representations (e.g., goals, beliefs, plans) extracted from any available data, which can include visual cues, linguistic narratives, or both. To address this, we introduce a multimodal Theory of Mind question answering (MMToM-QA) benchmark. MMToM-QA comprehensively evaluates machine ToM both on multimodal data and on different kinds of unimodal data about a person's activity in a household environment. To engineer multimodal ToM capacity, we propose a novel method, BIP-ALM (Bayesian Inverse Planning Accelerated by Language Models). BIP-ALM extracts unified representations from multimodal data and utilizes language models for scalable Bayesian inverse planning. We conducted a systematic comparison of human performance, BIP-ALM, and state-of-the-art models, including GPT-4. The experiments demonstrate that large language models and large multimodal models still lack robust ToM capacity. BIP-ALM, on the other hand, shows promising results, by leveraging the power of both model-based mental inference and language models.
The Cultural Psychology of Large Language Models: Is ChatGPT a Holistic or Analytic Thinker?
Aug 28, 2023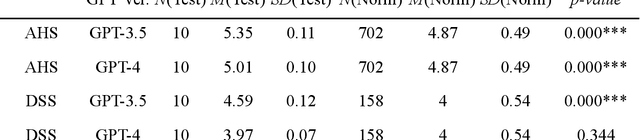
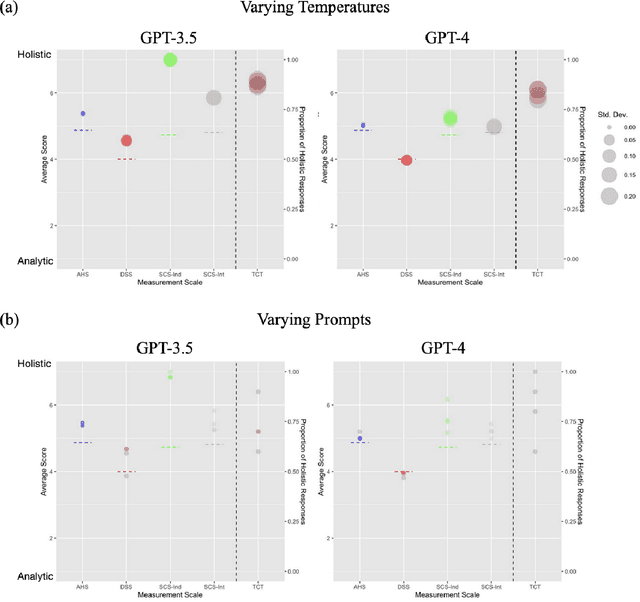
The prevalent use of Large Language Models (LLMs) has necessitated studying their mental models, yielding noteworthy theoretical and practical implications. Current research has demonstrated that state-of-the-art LLMs, such as ChatGPT, exhibit certain theory of mind capabilities and possess relatively stable Big Five and/or MBTI personality traits. In addition, cognitive process features form an essential component of these mental models. Research in cultural psychology indicated significant differences in the cognitive processes of Eastern and Western people when processing information and making judgments. While Westerners predominantly exhibit analytical thinking that isolates things from their environment to analyze their nature independently, Easterners often showcase holistic thinking, emphasizing relationships and adopting a global viewpoint. In our research, we probed the cultural cognitive traits of ChatGPT. We employed two scales that directly measure the cognitive process: the Analysis-Holism Scale (AHS) and the Triadic Categorization Task (TCT). Additionally, we used two scales that investigate the value differences shaped by cultural thinking: the Dialectical Self Scale (DSS) and the Self-construal Scale (SCS). In cognitive process tests (AHS/TCT), ChatGPT consistently tends towards Eastern holistic thinking, but regarding value judgments (DSS/SCS), ChatGPT does not significantly lean towards the East or the West. We suggest that the result could be attributed to both the training paradigm and the training data in LLM development. We discuss the potential value of this finding for AI research and directions for future research.
Neural Amortized Inference for Nested Multi-agent Reasoning
Aug 21, 2023



Multi-agent interactions, such as communication, teaching, and bluffing, often rely on higher-order social inference, i.e., understanding how others infer oneself. Such intricate reasoning can be effectively modeled through nested multi-agent reasoning. Nonetheless, the computational complexity escalates exponentially with each level of reasoning, posing a significant challenge. However, humans effortlessly perform complex social inferences as part of their daily lives. To bridge the gap between human-like inference capabilities and computational limitations, we propose a novel approach: leveraging neural networks to amortize high-order social inference, thereby expediting nested multi-agent reasoning. We evaluate our method in two challenging multi-agent interaction domains. The experimental results demonstrate that our method is computationally efficient while exhibiting minimal degradation in accuracy.
Semi-Supervised Image Captioning with CLIP
Jun 26, 2023



Image captioning, a fundamental task in vision-language understanding, seeks to generate accurate natural language descriptions for provided images. The CLIP model, with its rich semantic features learned from a large corpus of image-text pairs, is well-suited for this task. In this paper, we present a two-stage semi-supervised image captioning approach that exploits the potential of CLIP encoding. Our model comprises a CLIP visual encoder, a mapping network, and a language model for text generation. In the initial stage, we train the model using a small labeled dataset by contrasting the generated captions with the ground truth captions. In the subsequent stage, we continue the training using unlabeled images, aiming to maximize the image-caption similarity based on CLIP embeddings. Remarkably, despite utilizing less than 2% of the COCO-captions, our approach delivers a performance comparable to state-of-the-art models trained on the complete dataset. Furthermore, the captions generated by our approach are more distinctive, informative, and in line with human preference.