 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Rank when Grades Matter
Jun 20, 2023
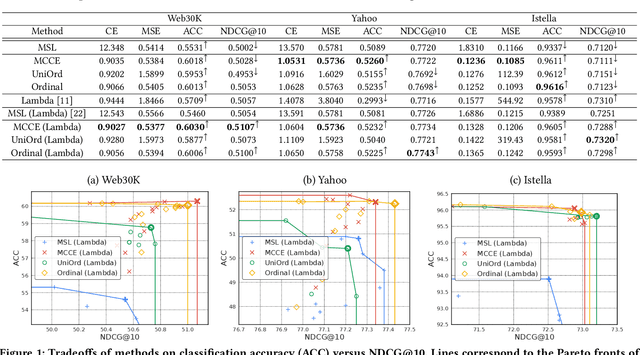
Graded labels are ubiquitous in real-world learning-to-rank applications, especially in human rated relevance data. Traditional learning-to-rank techniques aim to optimize the ranked order of documents. They typically, however, ignore predicting actual grades. This prevents them from being adopted in applications where grades matter, such as filtering out ``poor'' documents. Achieving both good ranking performance and good grade prediction performance is still an under-explored problem. Existing research either focuses only on ranking performance by not calibrating model outputs, or treats grades as numerical values, assuming labels are on a linear scale and failing to leverage the ordinal grade information. In this paper, we conduct a rigorous study of learning to rank with grades, where both ranking performance and grade prediction performance are important. We provide a formal discussion on how to perform ranking with non-scalar predictions for grades, and propose a multiobjective formulation to jointly optimize both ranking and grade predictions. In experiments, we verify on several public datasets that our methods are able to push the Pareto frontier of the tradeoff between ranking and grade prediction performance, showing the benefit of leveraging ordinal grade information.
Exploring the Viability of Synthetic Query Generation for Relevance Prediction
May 19, 2023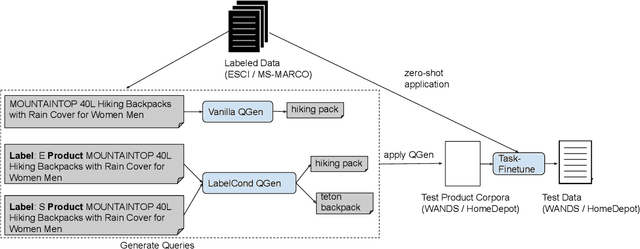
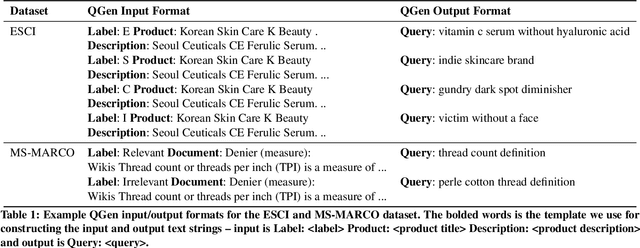

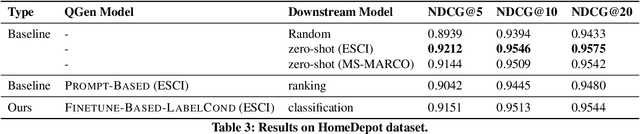
Query-document relevance prediction is a critical problem in Information Retrieval systems. This problem has increasingly been tackled using (pretrained) transformer-based models which are finetuned using large collections of labeled data. However, in specialized domains such as e-commerce and healthcare, the viability of this approach is limited by the dearth of large in-domain data. To address this paucity, recent methods leverage these powerful models to generate high-quality task and domain-specific synthetic data. Prior work has largely explored synthetic data generation or query generation (QGen) for Question-Answering (QA) and binary (yes/no) relevance prediction, where for instance, the QGen models are given a document, and trained to generate a query relevant to that document. However in many problems, we have a more fine-grained notion of relevance than a simple yes/no label. Thus, in this work, we conduct a detailed study into how QGen approaches can be leveraged for nuanced relevance prediction. We demonstrate that -- contrary to claims from prior works -- current QGen approaches fall short of the more conventional cross-domain transfer-learning approaches. Via empirical studies spanning 3 public e-commerce benchmarks, we identify new shortcomings of existing QGen approaches -- including their inability to distinguish between different grades of relevance. To address this, we introduce label-conditioned QGen models which incorporates knowledge about the different relevance. While our experiments demonstrate that these modifications help improve performance of QGen techniques, we also find that QGen approaches struggle to capture the full nuance of the relevance label space and as a result the generated queries are not faithful to the desired relevance label.
QUILL: Query Intent with Large Language Models using Retrieval Augmentation and Multi-stage Distillation
Oct 27, 2022Large Language Models (LLMs) have shown impressive results on a variety of text understanding tasks. Search queries though pose a unique challenge, given their short-length and lack of nuance or context. Complicated feature engineering efforts do not always lead to downstream improvements as their performance benefits may be offset by increased complexity of knowledge distillation. Thus, in this paper we make the following contributions: (1) We demonstrate that Retrieval Augmentation of queries provides LLMs with valuable additional context enabling improved understanding. While Retrieval Augmentation typically increases latency of LMs (thus hurting distillation efficacy), (2) we provide a practical and effective way of distilling Retrieval Augmentation LLMs. Specifically, we use a novel two-stage distillation approach that allows us to carry over the gains of retrieval augmentation, without suffering the increased compute typically associated with it. (3) We demonstrate the benefits of the proposed approach (QUILL) on a billion-scale, real-world query understanding system resulting in huge gains. Via extensive experiments, including on public benchmarks, we believe this work offers a recipe for practical use of retrieval-augmented query understanding.
Retrieval Augmentation for T5 Re-ranker using External Sources
Oct 11, 2022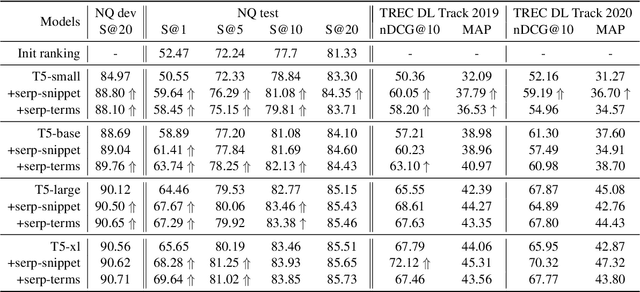
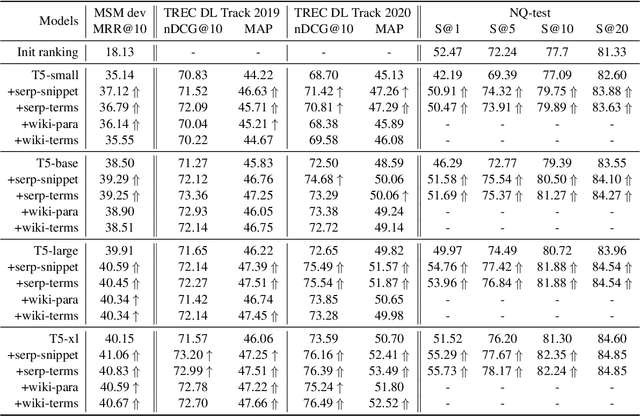
Retrieval augmentation has shown promising improvements in different tasks. However, whether such augmentation can assist a large language model based re-ranker remains unclear. We investigate how to augment T5-based re-rankers using high-quality information retrieved from two external corpora -- a commercial web search engine and Wikipedia. We empirically demonstrate how retrieval augmentation can substantially improve the effectiveness of T5-based re-rankers for both in-domain and zero-shot out-of-domain re-ranking tasks.