 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Rank when Grades Matter
Paper and Code

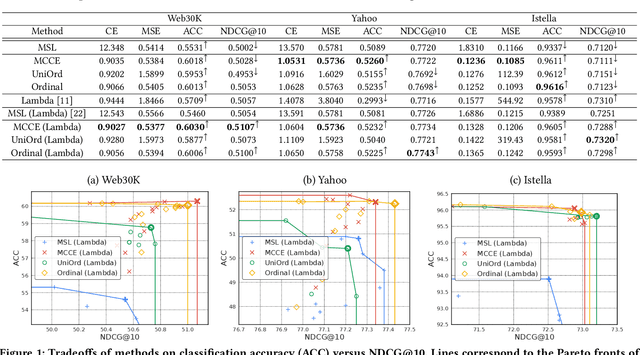
Graded labels are ubiquitous in real-world learning-to-rank applications, especially in human rated relevance data. Traditional learning-to-rank techniques aim to optimize the ranked order of documents. They typically, however, ignore predicting actual grades. This prevents them from being adopted in applications where grades matter, such as filtering out ``poor'' documents. Achieving both good ranking performance and good grade prediction performance is still an under-explored problem. Existing research either focuses only on ranking performance by not calibrating model outputs, or treats grades as numerical values, assuming labels are on a linear scale and failing to leverage the ordinal grade information. In this paper, we conduct a rigorous study of learning to rank with grades, where both ranking performance and grade prediction performance are important. We provide a formal discussion on how to perform ranking with non-scalar predictions for grades, and propose a multiobjective formulation to jointly optimize both ranking and grade predictions. In experiments, we verify on several public datasets that our methods are able to push the Pareto frontier of the tradeoff between ranking and grade prediction performance, showing the benefit of leveraging ordinal grade information.