 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHalluWorld: A Controlled Benchmark for Hallucination via Reference World Models
May 19, 2026Hallucination remains a central failure mode of large language models, but existing benchmarks operationalize it inconsistently across summarization, question answering, retrieval-augmented generation, and agentic interaction. This fragmentation makes it unclear whether a mitigation that works in one setting reduces hallucinations across contexts. Current benchmarks either require human annotation and fixed references that may be memorized, or rely on observations in settings that are difficult to reproduce. To study root causes, we introduce HalluWorld, an extensible benchmark grounded in an explicit reference-world formulation: a model hallucinates when it produces an observable claim that is false with respect to this world. Building on this view, we construct synthetic and semi-synthetic environments in which the reference world is fully specified, the model's view is controlled, and hallucination labels are generated automatically. HalluWorld spans gridworlds, chess, and realistic terminal tasks, enabling controlled variation of world complexity, observability, temporal change, and source-conflict policy, and disentangling hallucinations into fine-grained error categories. We evaluate frontier and open-weight language models across these settings and find consistent patterns: perceptual hallucination on directly observed information is near-solved for frontier models, while multi-step state tracking and causal forward simulation remain difficult and are not generally solved by extended thinking. In the terminal setting, models also struggle with when to abstain. The uneven profile of failures across probe types and domains suggests that hallucinations arise from distinct failure modes rather than a single capability. Our results suggest that controlled reference worlds offer a scalable and reproducible path toward measuring and reducing hallucinations in modern language models.
What do Language Models Learn and When? The Implicit Curriculum Hypothesis
Apr 09, 2026Large language models (LLMs) can perform remarkably complex tasks, yet the fine-grained details of how these capabilities emerge during pretraining remain poorly understood. Scaling laws on validation loss tell us how much a model improves with additional compute, but not what skills it acquires in which order. To remedy this, we propose the Implicit Curriculum Hypothesis: pretraining follows a compositional and predictable curriculum across models and data mixtures. We test this by designing a suite of simple, composable tasks spanning retrieval, morphological transformations, coreference, logical reasoning, and mathematics. Using these tasks, we track emergence points across four model families spanning sizes from 410M-13B parameters. We find that emergence orderings of when models reach fixed accuracy thresholds are strikingly consistent ($ρ= .81$ across 45 model pairs), and that composite tasks most often emerge after their component tasks. Furthermore, we find that this structure is encoded in model representations: tasks with similar function vector representations also tend to follow similar trajectories in training. By using the space of representations derived from our task set, we can effectively predict the training trajectories of simple held-out compositional tasks throughout the course of pretraining ($R^2 = .68$-$.84$ across models) without previously evaluating them. Together, these results suggest that pretraining is more structured than loss curves reveal: skills emerge in a compositional order that is consistent across models and readable from their internals.
To Memorize or to Retrieve: Scaling Laws for RAG-Considerate Pretraining
Apr 01, 2026Retrieval-augmented generation (RAG) improves language model (LM) performance by providing relevant context at test time for knowledge-intensive situations. However, the relationship between parametric knowledge acquired during pretraining and non-parametric knowledge accessed via retrieval remains poorly understood, especially under fixed data budgets. In this work, we systematically study the trade-off between pretraining corpus size and retrieval store size across a wide range of model and data scales. We train OLMo-2-based LMs ranging from 30M to 3B parameters on up to 100B tokens of DCLM data, while varying both pretraining data scale (1-150x the number of parameters) and retrieval store size (1-20x), and evaluate performance across a diverse suite of benchmarks spanning reasoning, scientific QA, and open-domain QA. We find that retrieval consistently improves performance over parametric-only baselines across model scales and introduce a three-dimensional scaling framework that models performance as a function of model size, pretraining tokens, and retrieval corpus size. This scaling manifold enables us to estimate optimal allocations of a fixed data budget between pretraining and retrieval, revealing that the marginal utility of retrieval depends strongly on model scale, task type, and the degree of pretraining saturation. Our results provide a quantitative foundation for understanding when and how retrieval should complement pretraining, offering practical guidance for allocating data resources in the design of scalable language modeling systems.
Hybrid-Gym: Training Coding Agents to Generalize Across Tasks
Feb 18, 2026When assessing the quality of coding agents, predominant benchmarks focus on solving single issues on GitHub, such as SWE-Bench. In contrast, in real use, these agents solve more various and complex tasks that involve other skills such as exploring codebases, testing software, and designing architecture. In this paper, we first characterize some transferable skills that are shared across diverse tasks by decomposing trajectories into fine-grained components, and derive a set of principles for designing auxiliary training tasks to teach language models these skills. Guided by these principles, we propose a training environment, Hybrid-Gym, consisting of a set of scalable synthetic tasks, such as function localization and dependency search. Experiments show that agents trained on our synthetic tasks effectively generalize to diverse real-world tasks that are not present in training, improving a base model by 25.4% absolute gain on SWE-Bench Verified, 7.9% on SWT-Bench Verified, and 5.1% on Commit-0 Lite. Hybrid-Gym also complements datasets built for the downstream tasks (e.g., improving SWE-Play by 4.9% on SWT-Bench Verified). Code available at: https://github.com/yiqingxyq/Hybrid-Gym.
A Unified Definition of Hallucination, Or: It's the World Model, Stupid
Dec 25, 2025Despite numerous attempts to solve the issue of hallucination since the inception of neural language models, it remains a problem in even frontier large language models today. Why is this the case? We walk through definitions of hallucination used in the literature from a historical perspective up to the current day, and fold them into a single definition of hallucination, wherein different prior definitions focus on different aspects of our definition. At its core, we argue that hallucination is simply inaccurate (internal) world modeling, in a form where it is observable to the user (e.g., stating a fact which contradicts a knowledge base, or producing a summary which contradicts a known source). By varying the reference world model as well as the knowledge conflict policy (e.g., knowledge base vs. in-context), we arrive at the different existing definitions of hallucination present in the literature. We argue that this unified view is useful because it forces evaluations to make clear their assumed "world" or source of truth, clarifies what should and should not be called hallucination (as opposed to planning or reward/incentive-related errors), and provides a common language to compare benchmarks and mitigation techniques. Building on this definition, we outline plans for a family of benchmarks in which hallucinations are defined as mismatches with synthetic but fully specified world models in different environments, and sketch out how these benchmarks can use such settings to stress-test and improve the world modeling components of language models.
Not-Just-Scaling Laws: Towards a Better Understanding of the Downstream Impact of Language Model Design Decisions
Mar 05, 2025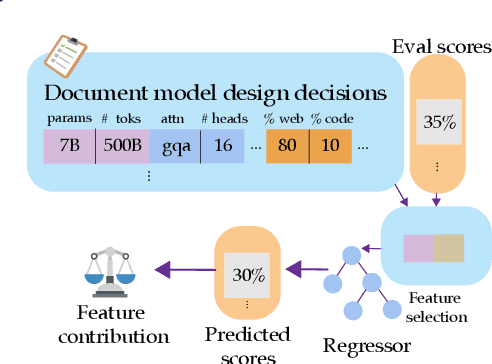
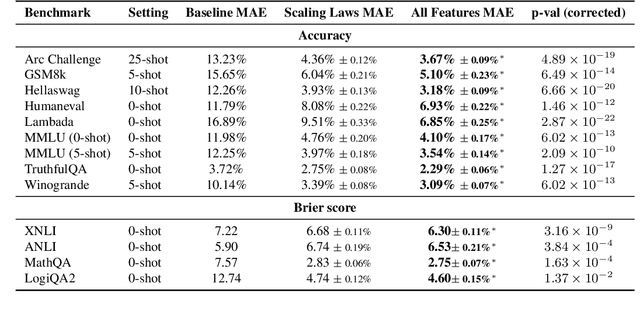
Improvements in language model capabilities are often attributed to increasing model size or training data, but in some cases smaller models trained on curated data or with different architectural decisions can outperform larger ones trained on more tokens. What accounts for this? To quantify the impact of these design choices, we meta-analyze 92 open-source pretrained models across a wide array of scales, including state-of-the-art open-weights models as well as less performant models and those with less conventional design decisions. We find that by incorporating features besides model size and number of training tokens, we can achieve a relative 3-28% increase in ability to predict downstream performance compared with using scale alone. Analysis of model design decisions reveal insights into data composition, such as the trade-off between language and code tasks at 15-25\% code, as well as the better performance of some architectural decisions such as choosing rotary over learned embeddings. Broadly, our framework lays a foundation for more systematic investigation of how model development choices shape final capabilities.
Language Modeling with Editable External Knowledge
Jun 17, 2024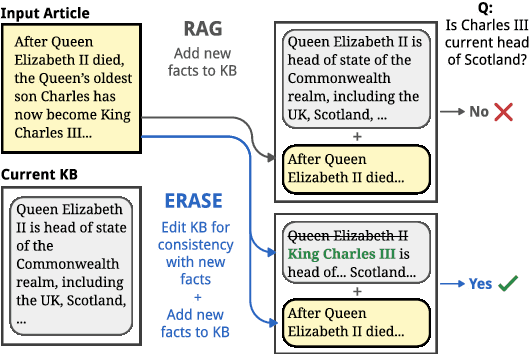
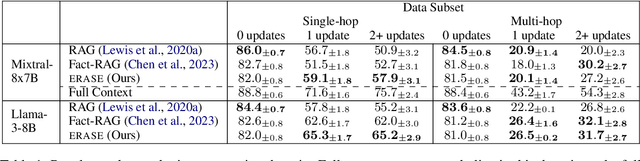
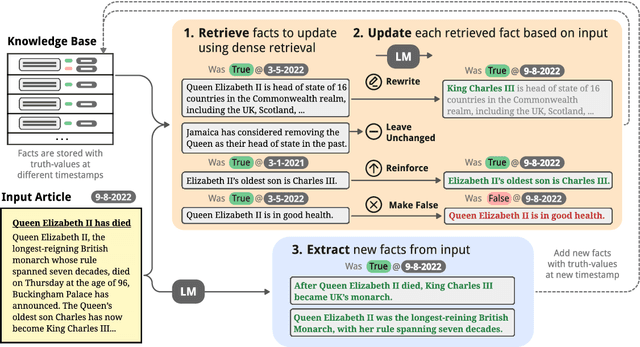
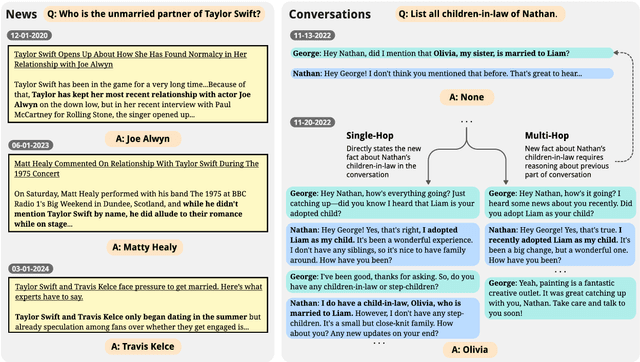
When the world changes, so does the text that humans write about it. How do we build language models that can be easily updated to reflect these changes? One popular approach is retrieval-augmented generation, in which new documents are inserted into a knowledge base and retrieved during prediction for downstream tasks. Most prior work on these systems have focused on improving behavior during prediction through better retrieval or reasoning. This paper introduces ERASE, which instead improves model behavior when new documents are acquired, by incrementally deleting or rewriting other entries in the knowledge base each time a document is added. In two new benchmark datasets evaluating models' ability to answer questions about a stream of news articles or conversations, ERASE improves accuracy relative to conventional retrieval-augmented generation by 7-13% (Mixtral-8x7B) and 6-10% (Llama-3-8B) absolute. Code and data are available at https://github.com/belindal/ERASE
An Incomplete Loop: Deductive, Inductive, and Abductive Learning in Large Language Models
Apr 10, 2024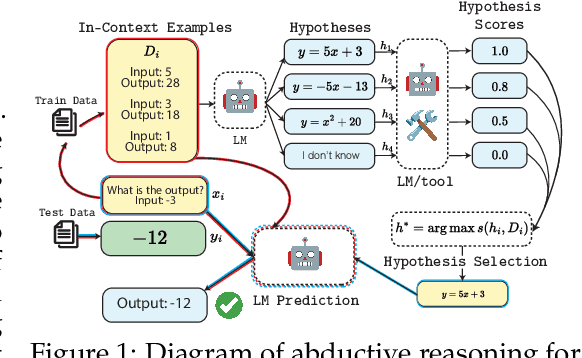

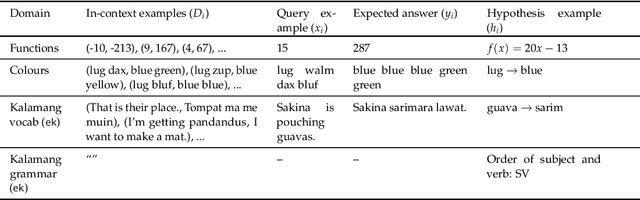
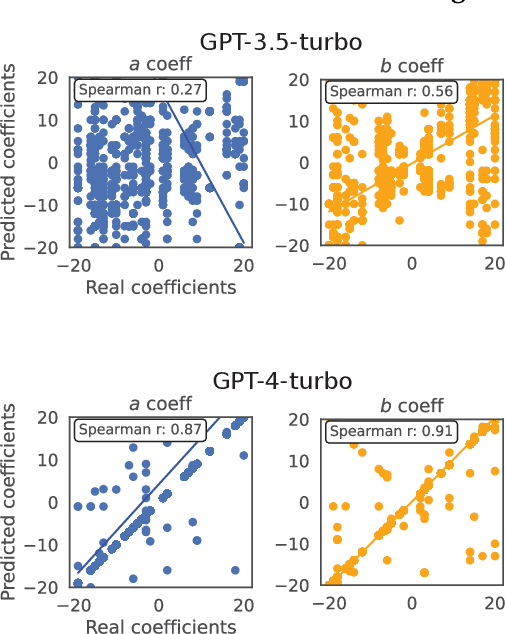
Modern language models (LMs) can learn to perform new tasks in different ways: in instruction following, the target task is described explicitly in natural language; in few-shot prompting, the task is specified implicitly with a small number of examples; in instruction inference, LMs are presented with in-context examples and are then prompted to generate a natural language task description before making predictions. Each of these procedures may be thought of as invoking a different form of reasoning: instruction following involves deductive reasoning, few-shot prompting involves inductive reasoning, and instruction inference involves abductive reasoning. How do these different capabilities relate? Across four LMs (from the gpt and llama families) and two learning problems (involving arithmetic functions and machine translation) we find a strong dissociation between the different types of reasoning: LMs can sometimes learn effectively from few-shot prompts even when they are unable to explain their own prediction rules; conversely, they sometimes infer useful task descriptions while completely failing to learn from human-generated descriptions of the same task. Our results highlight the non-systematic nature of reasoning even in some of today's largest LMs, and underscore the fact that very different learning mechanisms may be invoked by seemingly similar prompting procedures.
Program-Aided Reasoners Know What They Know
Nov 16, 2023Prior work shows that program-aided reasoning, in which large language models (LLMs) are combined with programs written in programming languages such as Python, can significantly improve accuracy on various reasoning tasks. However, while accuracy is essential, it is also important for such reasoners to "know what they know", which can be quantified through the calibration of the model. In this paper, we compare the calibration of Program Aided Language Models (PAL) and text-based Chain-of-thought (COT) prompting techniques over 5 datasets and 2 model types: LLaMA models and OpenAI models. Our results indicate that PAL leads to improved calibration in 75% of the instances. Our analysis uncovers that prompting styles that produce lesser diversity in generations also have more calibrated results, and thus we also experiment with inducing lower generation diversity using temperature scaling and find that for certain temperatures, PAL is not only more accurate but is also more calibrated than COT. Overall, we demonstrate that, in the majority of cases, program-aided reasoners better know what they know than text-based counterparts.
Divergences between Language Models and Human Brains
Nov 15, 2023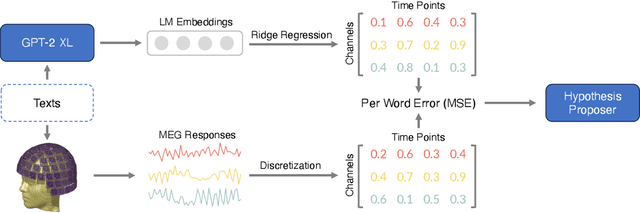


Do machines and humans process language in similar ways? A recent line of research has hinted in the affirmative, demonstrating that human brain signals can be effectively predicted using the internal representations of language models (LMs). This is thought to reflect shared computational principles between LMs and human language processing. However, there are also clear differences in how LMs and humans acquire and use language, even if the final task they are performing is the same. Despite this, there is little work exploring systematic differences between human and machine language processing using brain data. To address this question, we examine the differences between LM representations and the human brain's responses to language, specifically by examining a dataset of Magnetoencephalography (MEG) responses to a written narrative. In doing so we identify three phenomena that, in prior work, LMs have been found to not capture well: emotional understanding, figurative language processing, and physical commonsense. By fine-tuning LMs on datasets related to these phenomena, we observe that fine-tuned LMs show improved alignment with human brain responses across these tasks. Our study implies that the observed divergences between LMs and human brains may stem from LMs' inadequate representation of these specific types of knowledge.