 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompletion $ eq$ Collaboration: Scaling Collaborative Effort with Agents
Oct 30, 2025Current evaluations of agents remain centered around one-shot task completion, failing to account for the inherently iterative and collaborative nature of many real-world problems, where human goals are often underspecified and evolve. We argue for a shift from building and assessing task completion agents to developing collaborative agents, assessed not only by the quality of their final outputs but by how well they engage with and enhance human effort throughout the problem-solving process. To support this shift, we introduce collaborative effort scaling, a framework that captures how an agent's utility grows with increasing user involvement. Through case studies and simulated evaluations, we show that state-of-the-art agents often underperform in multi-turn, real-world scenarios, revealing a missing ingredient in agent design: the ability to sustain engagement and scaffold user understanding. Collaborative effort scaling offers a lens for diagnosing agent behavior and guiding development toward more effective interactions.
Modeling Student Learning with 3.8 Million Program Traces
Oct 06, 2025As programmers write code, they often edit and retry multiple times, creating rich "interaction traces" that reveal how they approach coding tasks and provide clues about their level of skill development. For novice programmers in particular, these traces reflect the diverse reasoning processes they employ to code, such as exploratory behavior to understand how a programming concept works, re-strategizing in response to bugs, and personalizing stylistic choices. In this work, we explore what can be learned from training language models on such reasoning traces: not just about code, but about coders, and particularly students learning to program. We introduce a dataset of over 3.8 million programming reasoning traces from users of Pencil Code, a free online educational platform used by students to learn simple programming concepts. Compared to models trained only on final programs or synthetically-generated traces, we find that models trained on real traces are stronger at modeling diverse student behavior. Through both behavioral and probing analyses, we also find that many properties of code traces, such as goal backtracking or number of comments, can be predicted from learned representations of the students who write them. Building on this result, we show that we can help students recover from mistakes by steering code generation models to identify a sequence of edits that will results in more correct code while remaining close to the original student's style. Together, our results suggest that many properties of code are properties of individual students and that training on edit traces can lead to models that are more steerable, more predictive of student behavior while programming, and better at generating programs in their final states. Code and data is available at https://github.com/meghabyte/pencilcode-public
Language Modeling with Editable External Knowledge
Jun 17, 2024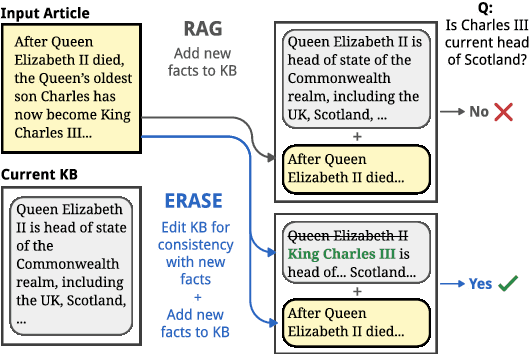
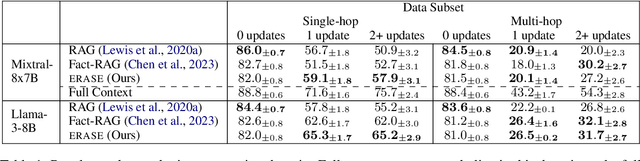
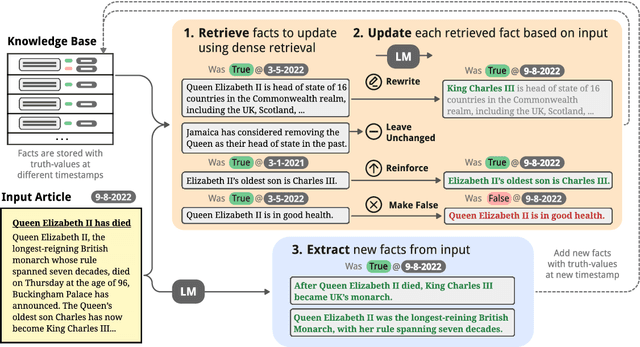
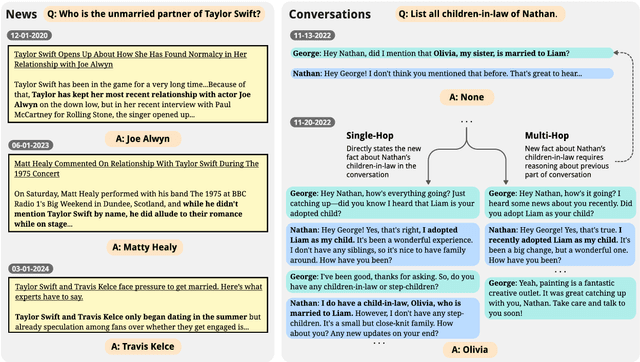
When the world changes, so does the text that humans write about it. How do we build language models that can be easily updated to reflect these changes? One popular approach is retrieval-augmented generation, in which new documents are inserted into a knowledge base and retrieved during prediction for downstream tasks. Most prior work on these systems have focused on improving behavior during prediction through better retrieval or reasoning. This paper introduces ERASE, which instead improves model behavior when new documents are acquired, by incrementally deleting or rewriting other entries in the knowledge base each time a document is added. In two new benchmark datasets evaluating models' ability to answer questions about a stream of news articles or conversations, ERASE improves accuracy relative to conventional retrieval-augmented generation by 7-13% (Mixtral-8x7B) and 6-10% (Llama-3-8B) absolute. Code and data are available at https://github.com/belindal/ERASE
Learning Phonotactics from Linguistic Informants
May 08, 2024We propose an interactive approach to language learning that utilizes linguistic acceptability judgments from an informant (a competent language user) to learn a grammar. Given a grammar formalism and a framework for synthesizing data, our model iteratively selects or synthesizes a data-point according to one of a range of information-theoretic policies, asks the informant for a binary judgment, and updates its own parameters in preparation for the next query. We demonstrate the effectiveness of our model in the domain of phonotactics, the rules governing what kinds of sound-sequences are acceptable in a language, and carry out two experiments, one with typologically-natural linguistic data and another with a range of procedurally-generated languages. We find that the information-theoretic policies that our model uses to select items to query the informant achieve sample efficiency comparable to, and sometimes greater than, fully supervised approaches.
Toward In-Context Teaching: Adapting Examples to Students' Misconceptions
May 07, 2024When a teacher provides examples for a student to study, these examples must be informative, enabling a student to progress from their current state toward a target concept or skill. Good teachers must therefore simultaneously infer what students already know and adapt their teaching to students' changing state of knowledge. There is increasing interest in using computational models, particularly large language models, as pedagogical tools. As students, language models in particular have shown a remarkable ability to adapt to new tasks given small numbers of examples. But how effectively can these models adapt as teachers to students of different types? To study this question, we introduce a suite of models and evaluation methods we call AdapT. AdapT has two components: (1) a collection of simulated Bayesian student models that can be used for evaluation of automated teaching methods; (2) a platform for evaluation with human students, to characterize the real-world effectiveness of these methods. We additionally introduce (3) AToM, a new probabilistic model for adaptive teaching that jointly infers students' past beliefs and optimizes for the correctness of future beliefs. In evaluations of simulated students across three learning domains (fraction arithmetic, English morphology, function learning), AToM systematically outperforms LLM-based and standard Bayesian teaching models. In human experiments, both AToM and LLMs outperform non-adaptive random example selection. Our results highlight both the difficulty of the adaptive teaching task and the potential of learned adaptive models for solving it.
Reasoning or Reciting? Exploring the Capabilities and Limitations of Language Models Through Counterfactual Tasks
Aug 01, 2023The impressive performance of recent language models across a wide range of tasks suggests that they possess a degree of abstract reasoning skills. Are these skills general and transferable, or specialized to specific tasks seen during pretraining? To disentangle these effects, we propose an evaluation framework based on "counterfactual" task variants that deviate from the default assumptions underlying standard tasks. Across a suite of 11 tasks, we observe nontrivial performance on the counterfactual variants, but nevertheless find that performance substantially and consistently degrades compared to the default conditions. This suggests that while current LMs may possess abstract task-solving skills to a degree, they often also rely on narrow, non-transferable procedures for task-solving. These results motivate a more careful interpretation of language model performance that teases apart these aspects of behavior.
ARIES: A Corpus of Scientific Paper Edits Made in Response to Peer Reviews
Jun 21, 2023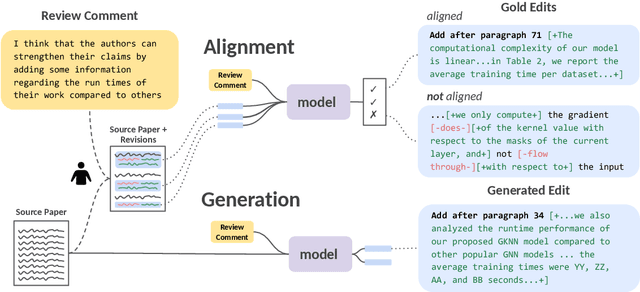
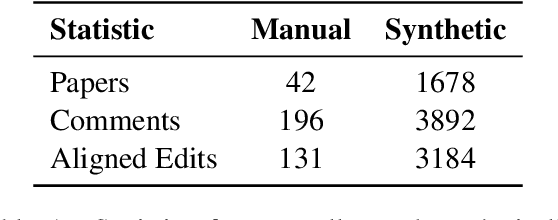

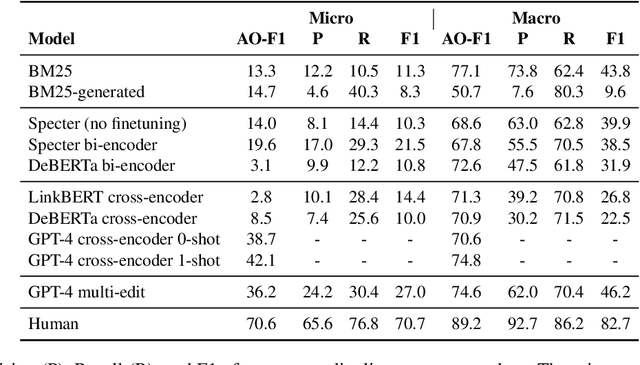
Revising scientific papers based on peer feedback is a challenging task that requires not only deep scientific knowledge and reasoning, but also the ability to recognize the implicit requests in high-level feedback and to choose the best of many possible ways to update the manuscript in response. We introduce this task for large language models and release ARIES, a dataset of review comments and their corresponding paper edits, to enable training and evaluating models. We study two versions of the task: comment-edit alignment and edit generation, and evaluate several baselines, including GPT-4. We find that models struggle even to identify the edits that correspond to a comment, especially in cases where the comment is phrased in an indirect way or where the edit addresses the spirit of a comment but not the precise request. When tasked with generating edits, GPT-4 often succeeds in addressing comments on a surface level, but it rigidly follows the wording of the feedback rather than the underlying intent, and includes fewer technical details than human-written edits. We hope that our formalization, dataset, and analysis will form a foundation for future work in this area.
Inverse Scaling: When Bigger Isn't Better
Jun 15, 2023



Work on scaling laws has found that large language models (LMs) show predictable improvements to overall loss with increased scale (model size, training data, and compute). Here, we present evidence for the claim that LMs may show inverse scaling, or worse task performance with increased scale, e.g., due to flaws in the training objective and data. We present empirical evidence of inverse scaling on 11 datasets collected by running a public contest, the Inverse Scaling Prize, with a substantial prize pool. Through analysis of the datasets, along with other examples found in the literature, we identify four potential causes of inverse scaling: (i) preference to repeat memorized sequences over following in-context instructions, (ii) imitation of undesirable patterns in the training data, (iii) tasks containing an easy distractor task which LMs could focus on, rather than the harder real task, and (iv) correct but misleading few-shot demonstrations of the task. We release the winning datasets at https://inversescaling.com/data to allow for further investigation of inverse scaling. Our tasks have helped drive the discovery of U-shaped and inverted-U scaling trends, where an initial trend reverses, suggesting that scaling trends are less reliable at predicting the behavior of larger-scale models than previously understood. Overall, our results suggest that there are tasks for which increased model scale alone may not lead to progress, and that more careful thought needs to go into the data and objectives for training language models.
CREST: A Joint Framework for Rationalization and Counterfactual Text Generation
May 26, 2023Selective rationales and counterfactual examples have emerged as two effective, complementary classes of interpretability methods for analyzing and training NLP models. However, prior work has not explored how these methods can be integrated to combine their complementary advantages. We overcome this limitation by introducing CREST (ContRastive Edits with Sparse raTionalization), a joint framework for selective rationalization and counterfactual text generation, and show that this framework leads to improvements in counterfactual quality, model robustness, and interpretability. First, CREST generates valid counterfactuals that are more natural than those produced by previous methods, and subsequently can be used for data augmentation at scale, reducing the need for human-generated examples. Second, we introduce a new loss function that leverages CREST counterfactuals to regularize selective rationales and show that this regularization improves both model robustness and rationale quality, compared to methods that do not leverage CREST counterfactuals. Our results demonstrate that CREST successfully bridges the gap between selective rationales and counterfactual examples, addressing the limitations of existing methods and providing a more comprehensive view of a model's predictions.
Does Self-Rationalization Improve Robustness to Spurious Correlations?
Oct 24, 2022



Rationalization is fundamental to human reasoning and learning. NLP models trained to produce rationales along with predictions, called self-rationalization models, have been investigated for their interpretability and utility to end-users. However, the extent to which training with human-written rationales facilitates learning remains an under-explored question. We ask whether training models to self-rationalize can aid in their learning to solve tasks for the right reasons. Specifically, we evaluate how training self-rationalization models with free-text rationales affects robustness to spurious correlations in fine-tuned encoder-decoder and decoder-only models of six different sizes. We evaluate robustness to spurious correlations by measuring performance on 1) manually annotated challenge datasets and 2) subsets of original test sets where reliance on spurious correlations would fail to produce correct answers. We find that while self-rationalization can improve robustness to spurious correlations in low-resource settings, it tends to hurt robustness in higher-resource settings. Furthermore, these effects depend on model family and size, as well as on rationale content. Together, our results suggest that explainability can come at the cost of robustness; thus, appropriate care should be taken when training self-rationalizing models with the goal of creating more trustworthy models.