 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Adapting Language Models
Jun 12, 2025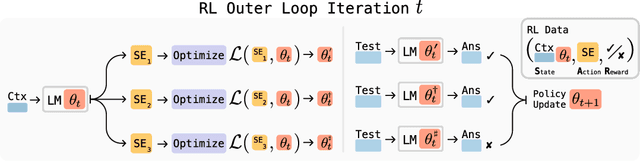


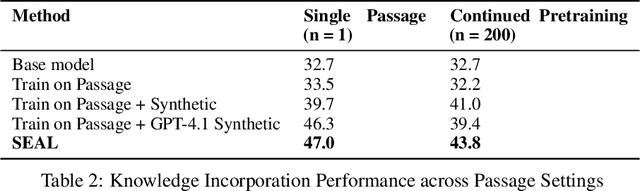
Large language models (LLMs) are powerful but static; they lack mechanisms to adapt their weights in response to new tasks, knowledge, or examples. We introduce Self-Adapting LLMs (SEAL), a framework that enables LLMs to self-adapt by generating their own finetuning data and update directives. Given a new input, the model produces a self-edit-a generation that may restructure the information in different ways, specify optimization hyperparameters, or invoke tools for data augmentation and gradient-based updates. Through supervised finetuning (SFT), these self-edits result in persistent weight updates, enabling lasting adaptation. To train the model to produce effective self-edits, we use a reinforcement learning loop with the downstream performance of the updated model as the reward signal. Unlike prior approaches that rely on separate adaptation modules or auxiliary networks, SEAL directly uses the model's own generation to control its adaptation process. Experiments on knowledge incorporation and few-shot generalization show that SEAL is a promising step toward language models capable of self-directed adaptation. Our website and code is available at https://jyopari.github.io/posts/seal.
WikiPersonas: What Can We Learn From Personalized Alignment to Famous People?
May 19, 2025Preference alignment has become a standard pipeline in finetuning models to follow \emph{generic} human preferences. Majority of work seeks to optimize model to produce responses that would be preferable \emph{on average}, simplifying the diverse and often \emph{contradicting} space of human preferences. While research has increasingly focused on personalized alignment: adapting models to individual user preferences, there is a lack of personalized preference dataset which focus on nuanced individual-level preferences. To address this, we introduce WikiPersona: the first fine-grained personalization using well-documented, famous individuals. Our dataset challenges models to align with these personas through an interpretable process: generating verifiable textual descriptions of a persona's background and preferences in addition to alignment. We systematically evaluate different personalization approaches and find that as few-shot prompting with preferences and fine-tuning fail to simultaneously ensure effectiveness and efficiency, using \textit{inferred personal preferences} as prefixes enables effective personalization, especially in topics where preferences clash while leading to more equitable generalization across unseen personas.
The Surprising Effectiveness of Test-Time Training for Abstract Reasoning
Nov 11, 2024
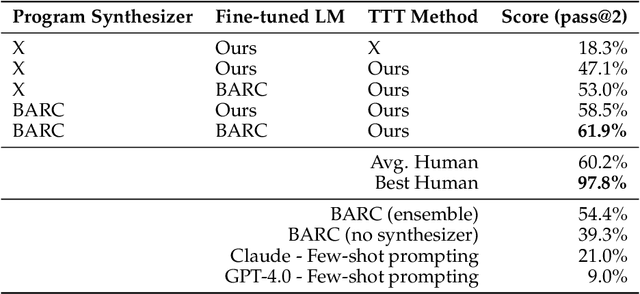
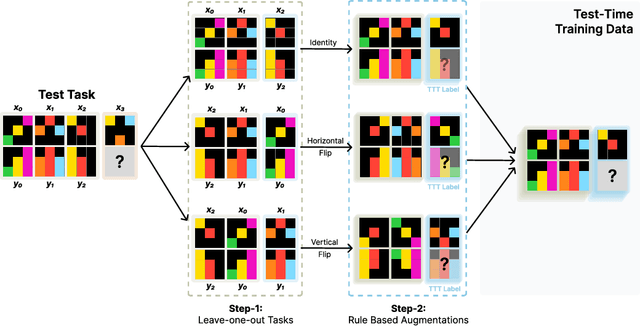
Language models have shown impressive performance on tasks within their training distribution, but often struggle with novel problems requiring complex reasoning. We investigate the effectiveness of test-time training (TTT) -- updating model parameters temporarily during inference using a loss derived from input data -- as a mechanism for improving models' reasoning capabilities, using the Abstraction and Reasoning Corpus (ARC) as a benchmark. Through systematic experimentation, we identify three crucial components for successful TTT: (1) initial finetuning on similar tasks (2) auxiliary task format and augmentations (3) per-instance training. TTT significantly improves performance on ARC tasks, achieving up to 6x improvement in accuracy compared to base fine-tuned models; applying TTT to an 8B-parameter language model, we achieve 53% accuracy on the ARC's public validation set, improving the state-of-the-art by nearly 25% for public and purely neural approaches. By ensembling our method with recent program generation approaches, we get SoTA public validation accuracy of 61.9%, matching the average human score. Our findings suggest that explicit symbolic search is not the only path to improved abstract reasoning in neural language models; additional test-time applied to continued training on few-shot examples can also be extremely effective.
In-Context Language Learning: Architectures and Algorithms
Jan 30, 2024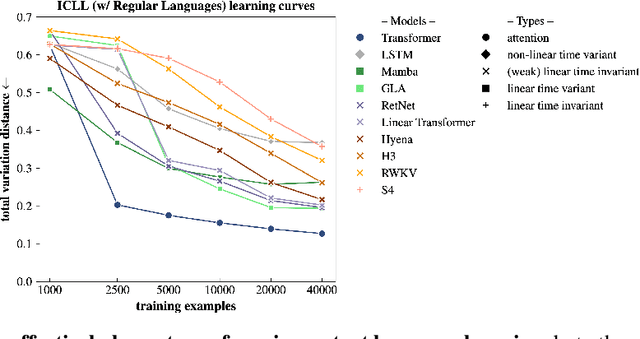



Large-scale neural language models exhibit a remarkable capacity for in-context learning (ICL): they can infer novel functions from datasets provided as input. Most of our current understanding of when and how ICL arises comes from LMs trained on extremely simple learning problems like linear regression and associative recall. There remains a significant gap between these model problems and the "real" ICL exhibited by LMs trained on large text corpora, which involves not just retrieval and function approximation but free-form generation of language and other structured outputs. In this paper, we study ICL through the lens of a new family of model problems we term in context language learning (ICLL). In ICLL, LMs are presented with a set of strings from a formal language, and must generate additional strings from the same language. We focus on in-context learning of regular languages generated by random finite automata. We evaluate a diverse set of neural sequence models (including several RNNs, Transformers, and state-space model variants) on regular ICLL tasks, aiming to answer three questions: (1) Which model classes are empirically capable of ICLL? (2) What algorithmic solutions do successful models implement to perform ICLL? (3) What architectural changes can improve ICLL in less performant models? We first show that Transformers significantly outperform neural sequence models with recurrent or convolutional representations on ICLL tasks. Next, we provide evidence that their ability to do so relies on specialized "n-gram heads" (higher-order variants of induction heads) that compute input-conditional next-token distributions. Finally, we show that hard-wiring these heads into neural models improves performance not just on ICLL, but natural language modeling -- improving the perplexity of 340M-parameter models by up to 1.14 points (6.7%) on the SlimPajama dataset.
Deductive Closure Training of Language Models for Coherence, Accuracy, and Updatability
Jan 16, 2024While language models (LMs) can sometimes generate factually correct text and estimate truth values of individual claims, these generally do not reflect a globally coherent, manipulable model of the world. As a consequence, current LMs also generate incorrect or nonsensical content, and are difficult to edit and bring up to date. We present a method called Deductive Closure Training (DCT) that uses LMs themselves to identify implications of (and contradictions within) the text that they generate, yielding an efficient self-supervised procedure for improving LM factuality. Given a collection of seed documents, DCT prompts LMs to generate additional text implied by these documents, reason globally about the correctness of this generated text, and finally fine-tune on text inferred to be correct. Given seed documents from a trusted source, DCT provides a tool for supervised model updating; if seed documents are sampled from the LM itself, DCT enables fully unsupervised fine-tuning for improved coherence and accuracy. Across the CREAK, MQUaKE, and Reversal Curse datasets, supervised DCT improves LM fact verification and text generation accuracy by 3-26%; on CREAK fully unsupervised DCT improves verification accuracy by 12%. These results show that LMs' reasoning capabilities during inference can be leveraged during training to improve their reliability.
Reasoning or Reciting? Exploring the Capabilities and Limitations of Language Models Through Counterfactual Tasks
Aug 01, 2023The impressive performance of recent language models across a wide range of tasks suggests that they possess a degree of abstract reasoning skills. Are these skills general and transferable, or specialized to specific tasks seen during pretraining? To disentangle these effects, we propose an evaluation framework based on "counterfactual" task variants that deviate from the default assumptions underlying standard tasks. Across a suite of 11 tasks, we observe nontrivial performance on the counterfactual variants, but nevertheless find that performance substantially and consistently degrades compared to the default conditions. This suggests that while current LMs may possess abstract task-solving skills to a degree, they often also rely on narrow, non-transferable procedures for task-solving. These results motivate a more careful interpretation of language model performance that teases apart these aspects of behavior.
RL4F: Generating Natural Language Feedback with Reinforcement Learning for Repairing Model Outputs
May 15, 2023



Despite their unprecedented success, even the largest language models make mistakes. Similar to how humans learn and improve using feedback, previous work proposed providing language models with natural language feedback to guide them in repairing their outputs. Because human-generated critiques are expensive to obtain, researchers have devised learned critique generators in lieu of human critics while assuming one can train downstream models to utilize generated feedback. However, this approach does not apply to black-box or limited access models such as ChatGPT, as they cannot be fine-tuned. Moreover, in the era of large general-purpose language agents, fine-tuning is neither computationally nor spatially efficient as it results in multiple copies of the network. In this work, we introduce RL4F (Reinforcement Learning for Feedback), a multi-agent collaborative framework where the critique generator is trained to maximize end-task performance of GPT-3, a fixed model more than 200 times its size. RL4F produces critiques that help GPT-3 revise its outputs. We study three datasets for action planning, summarization and alphabetization and show improvements (~5% on average) in multiple text similarity metrics over strong baselines across all three tasks.
What learning algorithm is in-context learning? Investigations with linear models
Nov 29, 2022



Neural sequence models, especially transformers, exhibit a remarkable capacity for in-context learning. They can construct new predictors from sequences of labeled examples $(x, f(x))$ presented in the input without further parameter updates. We investigate the hypothesis that transformer-based in-context learners implement standard learning algorithms implicitly, by encoding smaller models in their activations, and updating these implicit models as new examples appear in the context. Using linear regression as a prototypical problem, we offer three sources of evidence for this hypothesis. First, we prove by construction that transformers can implement learning algorithms for linear models based on gradient descent and closed-form ridge regression. Second, we show that trained in-context learners closely match the predictors computed by gradient descent, ridge regression, and exact least-squares regression, transitioning between different predictors as transformer depth and dataset noise vary, and converging to Bayesian estimators for large widths and depths. Third, we present preliminary evidence that in-context learners share algorithmic features with these predictors: learners' late layers non-linearly encode weight vectors and moment matrices. These results suggest that in-context learning is understandable in algorithmic terms, and that (at least in the linear case) learners may rediscover standard estimation algorithms. Code and reference implementations are released at https://github.com/ekinakyurek/google-research/blob/master/incontext.
Compositional Semantic Parsing with Large Language Models
Sep 30, 2022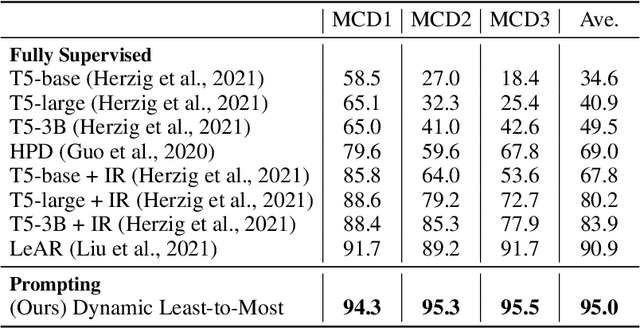
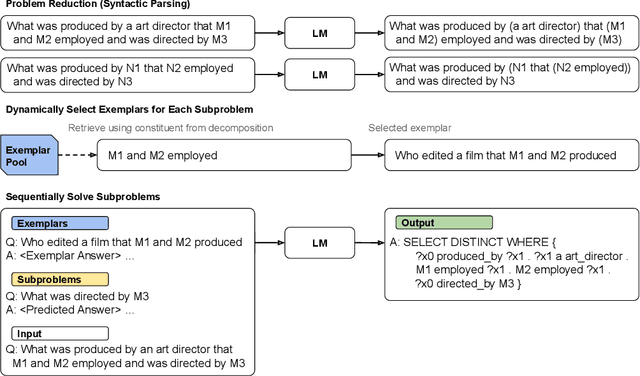
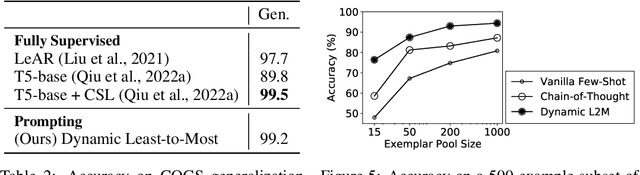
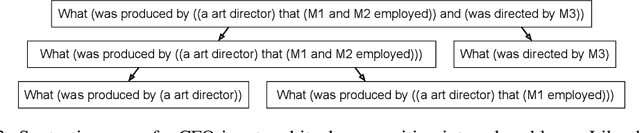
Humans can reason compositionally when presented with new tasks. Previous research shows that appropriate prompting techniques enable large language models (LLMs) to solve artificial compositional generalization tasks such as SCAN. In this work, we identify additional challenges in more realistic semantic parsing tasks with larger vocabulary and refine these prompting techniques to address them. Our best method is based on least-to-most prompting: it decomposes the problem using prompting-based syntactic parsing, then uses this decomposition to select appropriate exemplars and to sequentially generate the semantic parse. This method allows us to set a new state of the art for CFQ while requiring only 1% of the training data used by traditional approaches. Due to the general nature of our approach, we expect similar efforts will lead to new results in other tasks and domains, especially for knowledge-intensive applications.
Tracing Knowledge in Language Models Back to the Training Data
May 24, 2022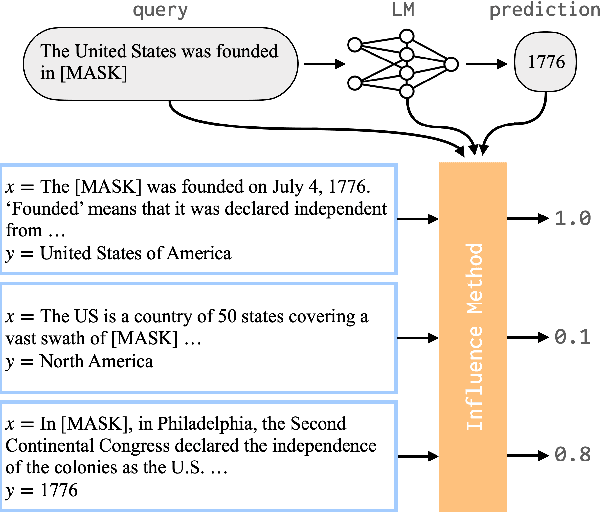
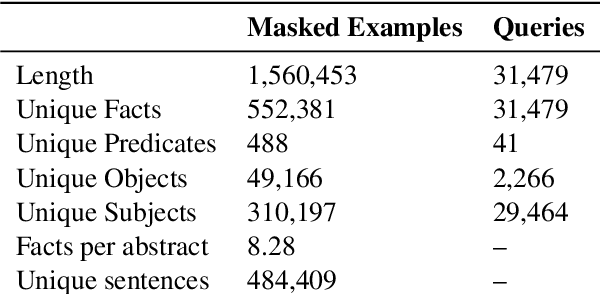
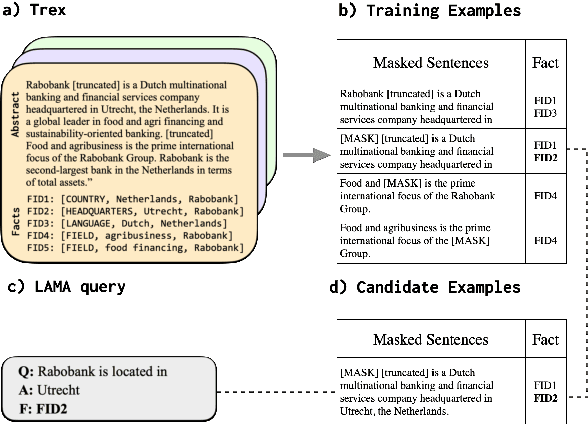
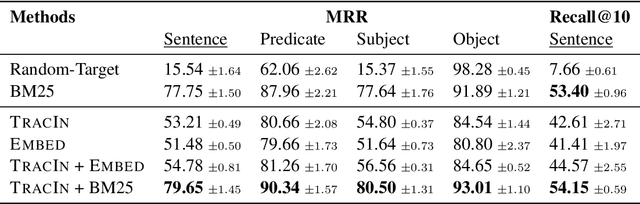
Neural language models (LMs) have been shown to memorize a great deal of factual knowledge. But when an LM generates an assertion, it is often difficult to determine where it learned this information and whether it is true. In this paper, we introduce a new benchmark for fact tracing: tracing language models' assertions back to the training examples that provided evidence for those predictions. Prior work has suggested that dataset-level influence methods might offer an effective framework for tracing predictions back to training data. However, such methods have not been evaluated for fact tracing, and researchers primarily have studied them through qualitative analysis or as a data cleaning technique for classification/regression tasks. We present the first experiments that evaluate influence methods for fact tracing, using well-understood information retrieval (IR) metrics. We compare two popular families of influence methods -- gradient-based and embedding-based -- and show that neither can fact-trace reliably; indeed, both methods fail to outperform an IR baseline (BM25) that does not even access the LM. We explore why this occurs (e.g., gradient saturation) and demonstrate that existing influence methods must be improved significantly before they can reliably attribute factual predictions in LMs.