 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Language Learning: Architectures and Algorithms
Paper and Code
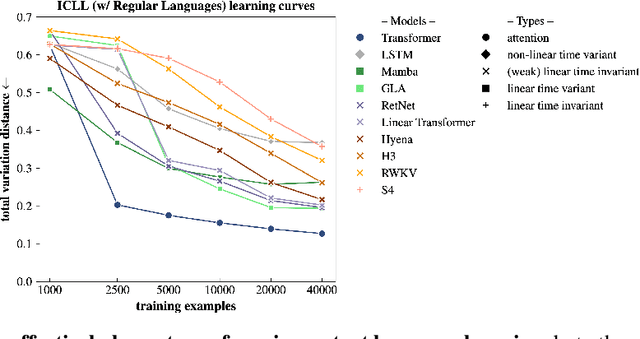



Large-scale neural language models exhibit a remarkable capacity for in-context learning (ICL): they can infer novel functions from datasets provided as input. Most of our current understanding of when and how ICL arises comes from LMs trained on extremely simple learning problems like linear regression and associative recall. There remains a significant gap between these model problems and the "real" ICL exhibited by LMs trained on large text corpora, which involves not just retrieval and function approximation but free-form generation of language and other structured outputs. In this paper, we study ICL through the lens of a new family of model problems we term in context language learning (ICLL). In ICLL, LMs are presented with a set of strings from a formal language, and must generate additional strings from the same language. We focus on in-context learning of regular languages generated by random finite automata. We evaluate a diverse set of neural sequence models (including several RNNs, Transformers, and state-space model variants) on regular ICLL tasks, aiming to answer three questions: (1) Which model classes are empirically capable of ICLL? (2) What algorithmic solutions do successful models implement to perform ICLL? (3) What architectural changes can improve ICLL in less performant models? We first show that Transformers significantly outperform neural sequence models with recurrent or convolutional representations on ICLL tasks. Next, we provide evidence that their ability to do so relies on specialized "n-gram heads" (higher-order variants of induction heads) that compute input-conditional next-token distributions. Finally, we show that hard-wiring these heads into neural models improves performance not just on ICLL, but natural language modeling -- improving the perplexity of 340M-parameter models by up to 1.14 points (6.7%) on the SlimPajama dataset.