 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Language Models Track Entities Across State Changes?
May 28, 2026Entity tracking (ET), the ability to keep track of states, is a fundamental skill that underlies complex reasoning. An increasing amount of work investigates how transformer language models (LMs) solve entity binding $\textit{without}$ state changes. However, there is limited understanding of how non-toy LMs address ET problems of realistic difficulties expressed in natural language. To this end, we investigate the mechanisms underlying ET in more complex scenarios featuring multiple state-changing operations. We find that LMs do not incrementally track world states across tokens or query-relevant states across layers, but simply aggregate relevant information in parallel at the last token when the query becomes evident. We further investigate mechanisms of individual operations ($\texttt{PUT}$, $\texttt{REMOVE}$, $\texttt{MOVE}$) to characterize this non-incremental ET mechanism. Surprisingly, LMs implement the $\texttt{REMOVE}$ operation with a fragile global suppression tag; this global removal mechanism predicts various failure modes that we confirm behaviorally. We provide a mechanistic solution of nullifying this tag to partially address this issue. Overall, our findings reveal that LMs solve a fundamentally sequential task using a non-sequential strategy. More broadly, our work illustrates how behavioral and mechanistic analyses can fruitfully interact. Behavioral results inform mechanistic hypotheses, and insights from mechanistic analyses help build stronger behavioral evaluations by predicting failure modes missing from existing evaluations.
R3: Robust Rubric-Agnostic Reward Models
May 19, 2025Reward models are essential for aligning language model outputs with human preferences, yet existing approaches often lack both controllability and interpretability. These models are typically optimized for narrow objectives, limiting their generalizability to broader downstream tasks. Moreover, their scalar outputs are difficult to interpret without contextual reasoning. To address these limitations, we introduce R3, a novel reward modeling framework that is rubric-agnostic, generalizable across evaluation dimensions, and provides interpretable, reasoned score assignments. R3 enables more transparent and flexible evaluation of language models, supporting robust alignment with diverse human values and use cases. Our models, data, and code are available as open source at https://github.com/rubricreward/r3
WikiPersonas: What Can We Learn From Personalized Alignment to Famous People?
May 19, 2025Preference alignment has become a standard pipeline in finetuning models to follow \emph{generic} human preferences. Majority of work seeks to optimize model to produce responses that would be preferable \emph{on average}, simplifying the diverse and often \emph{contradicting} space of human preferences. While research has increasingly focused on personalized alignment: adapting models to individual user preferences, there is a lack of personalized preference dataset which focus on nuanced individual-level preferences. To address this, we introduce WikiPersona: the first fine-grained personalization using well-documented, famous individuals. Our dataset challenges models to align with these personas through an interpretable process: generating verifiable textual descriptions of a persona's background and preferences in addition to alignment. We systematically evaluate different personalization approaches and find that as few-shot prompting with preferences and fine-tuning fail to simultaneously ensure effectiveness and efficiency, using \textit{inferred personal preferences} as prefixes enables effective personalization, especially in topics where preferences clash while leading to more equitable generalization across unseen personas.
Mitigating Hallucinated Translations in Large Language Models with Hallucination-focused Preference Optimization
Jan 28, 2025



Machine Translation (MT) is undergoing a paradigm shift, with systems based on fine-tuned large language models (LLM) becoming increasingly competitive with traditional encoder-decoder models trained specifically for translation tasks. However, LLM-based systems are at a higher risk of generating hallucinations, which can severely undermine user's trust and safety. Most prior research on hallucination mitigation focuses on traditional MT models, with solutions that involve post-hoc mitigation - detecting hallucinated translations and re-translating them. While effective, this approach introduces additional complexity in deploying extra tools in production and also increases latency. To address these limitations, we propose a method that intrinsically learns to mitigate hallucinations during the model training phase. Specifically, we introduce a data creation framework to generate hallucination focused preference datasets. Fine-tuning LLMs on these preference datasets reduces the hallucination rate by an average of 96% across five language pairs, while preserving overall translation quality. In a zero-shot setting our approach reduces hallucinations by 89% on an average across three unseen target languages.
* NAACL 2025 Main Conference Long paper (9 pages)
What Linguistic Features and Languages are Important in LLM Translation?
Feb 21, 2024Large Language Models (LLMs) demonstrate strong capability across multiple tasks, including machine translation. Our study focuses on evaluating Llama2's machine translation capabilities and exploring how translation depends on languages in its training data. Our experiments show that the 7B Llama2 model yields above 10 BLEU score for all languages it has seen, but not always for languages it has not seen. Most gains for those unseen languages are observed the most with the model scale compared to using chat versions or adding shot count. Furthermore, our linguistic distance analysis reveals that syntactic similarity is not always the primary linguistic factor in determining translation quality. Interestingly, we discovered that under specific circumstances, some languages, despite having significantly less training data than English, exhibit strong correlations comparable to English. Our discoveries here give new perspectives for the current landscape of LLMs, raising the possibility that LLMs centered around languages other than English may offer a more effective foundation for a multilingual model.
Explain-then-Translate: An Analysis on Improving Program Translation with Self-generated Explanations
Nov 13, 2023
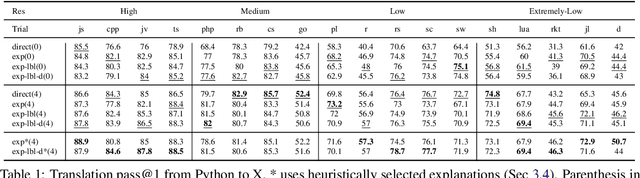
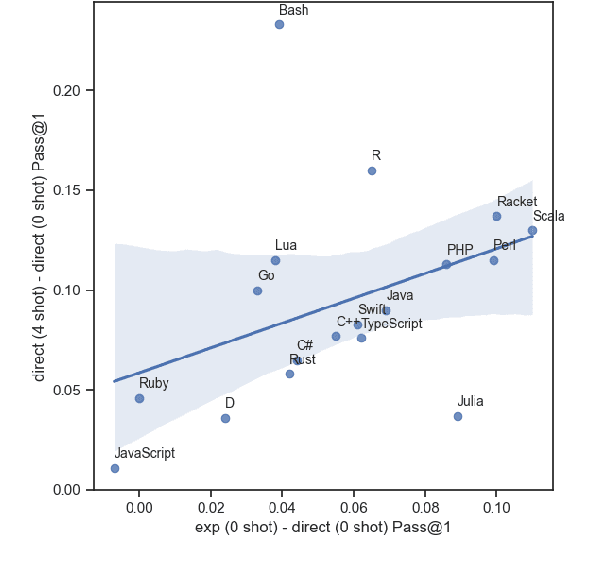
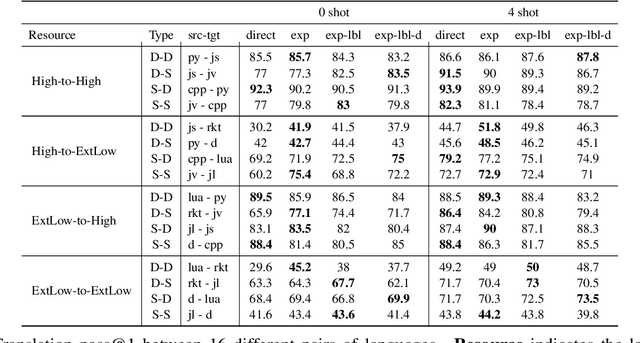
This work explores the use of self-generated natural language explanations as an intermediate step for code-to-code translation with language models. Across three types of explanations and 19 programming languages constructed from the MultiPL-E dataset, we find the explanations to be particularly effective in the zero-shot case, improving performance by 12% on average. Improvements with natural language explanations are particularly pronounced on difficult programs. We release our dataset, code, and canonical solutions in all 19 languages.
Knowledge Based Template Machine Translation In Low-Resource Setting
Sep 08, 2022

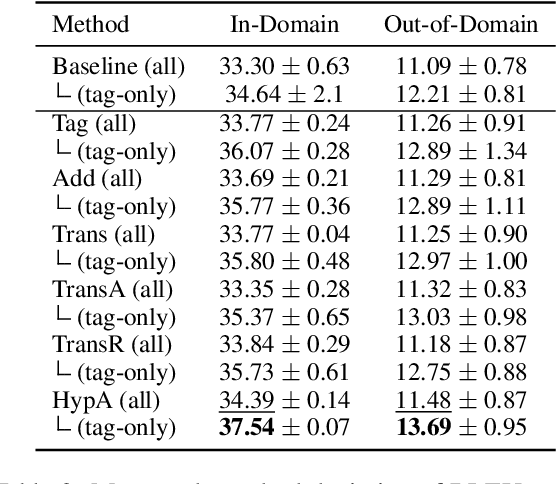
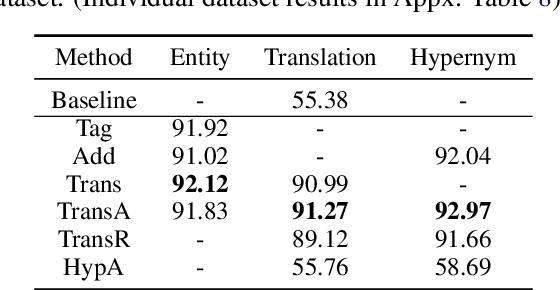
Incorporating tagging into neural machine translation (NMT) systems has shown promising results in helping translate rare words such as named entities (NE). However, translating NE in low-resource setting remains a challenge. In this work, we investigate the effect of using tags and NE hypernyms from knowledge graphs (KGs) in parallel corpus in different levels of resource conditions. We find the tag-and-copy mechanism (tag the NEs in the source sentence and copy them to the target sentence) improves translation in high-resource settings only. Introducing copying also results in polarizing effects in translating different parts-of-speech (POS). Interestingly, we find that copy accuracy for hypernyms is consistently higher than that of entities. As a way of avoiding "hard" copying and utilizing hypernym in bootstrapping rare entities, we introduced a "soft" tagging mechanism and found consistent improvement in high and low-resource settings.
Discrete Word Embedding for Logical Natural Language Understanding
Aug 26, 2020

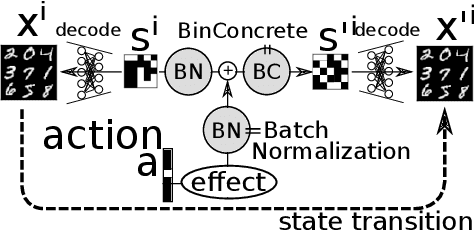
In this paper, we propose an unsupervised neural model for learning a discrete embedding of words. While being discrete, our embedding supports vector arithmetic operations similar to continuous embeddings by interpreting each word as a set of propositional statements describing a rule. The formulation of our vector arithmetic closely reflects the logical structure originating from the symbolic sequential decision making formalism (classical/STRIPS planning). Contrary to the conventional wisdom that discrete representation cannot perform well due to the lack of ability to capture the uncertainty, our representation is competitive against the continuous representations in several downstream tasks. We demonstrate that our embedding is directly compatible with the symbolic, classical planning solvers by performing a "paraphrasing" task. Due to the discrete/logical decision making in classical algorithms with deterministic (non-probabilistic) completeness, and also because it does not require additional training on the paraphrasing dataset, our system can negatively answer a paraphrasing query (inexistence of solutions), and can answer that only some approximate solutions exist -- A feature that is missing in the recent, huge, purely neural language models such as GPT-3.