 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMomento: Evaluating Persistent Memory and Reasoning with Multi-Session Agentic Conversations
May 30, 2026Recent advances in agentic AI have enabled agents to complete complex tasks through tool use, reasoning, and multi-step planning. Yet existing benchmarks evaluate agents within a single session, ignoring past actions, stated preferences, and prior decisions that agents must integrate to fulfill personalized user goals. We introduce Momento, a benchmark for persistent agentic task completion in multi-session service environments, requiring agents to take consequential, tool-mediated actions while resolving temporal dependencies and evolving user goals across sessions. Experimental results reveal that current agents fail primarily through misestimation of user state, treating prior session history as a reliable proxy for current context rather than stale information requiring re-validation, highlighting a substantial gap between current agent capabilities and realistic long-horizon human-agent interaction.
PingPong: A Natural Benchmark for Multi-Turn Code-Switching Dialogues
Jan 24, 2026Code-switching is a widespread practice among the world's multilingual majority, yet few benchmarks accurately reflect its complexity in everyday communication. We present PingPong, a benchmark for natural multi-party code-switching dialogues covering five language-combination variations, some of which are trilingual. Our dataset consists of human-authored conversations among 2 to 4 participants covering authentic, multi-threaded structures where replies frequently reference much earlier points in the dialogue. We demonstrate that our data is significantly more natural and structurally diverse than machine-generated alternatives, offering greater variation in message length, speaker dominance, and reply distance. Based on these dialogues, we define three downstream tasks: Question Answering, Dialogue Summarization, and Topic Classification. Evaluations of several state-of-the-art language models on PingPong reveal that performance remains limited on code-switched inputs, underscoring the urgent need for more robust NLP systems capable of addressing the intricacies of real-world multilingual discourse.
Mechanisms are Transferable: Data-Efficient Low-Resource Adaptation via Circuit-Targeted Supervised Fine-Tuning
Jan 13, 2026Adapting LLMs to low-resource languages is difficult: labeled data is scarce, full-model fine-tuning is unstable, and continued cross-lingual tuning can cause catastrophic forgetting. We propose Circuit-Targeted Supervised Fine-Tuning (CT-SFT): a counterfactual-free adaptation of CD-T (Contextual Decomposition Transformer) that uses a label-balanced mean baseline and task-directional relevance scoring to identify a sparse set of task-relevant attention heads in a proxy-language checkpoint, then transfer learns to a target language by updating only those heads (plus LayerNorm) via head-level gradient masking. Across NusaX-Senti and XNLI, CT-SFT improves cross-lingual accuracy over continued full fine-tuning while updating only a small subset of model parameters. We find an editing-preserving trade-off: harder transfers favor editing circuit heads, while easier transfers often favor near-zero (i.e., low-relevance heads) updates, preserving the source mechanism. CT-SFT also substantially reduces catastrophic forgetting, preserving proxy/source-language competence during transfer.
Moment and Highlight Detection via MLLM Frame Segmentation
Dec 13, 2025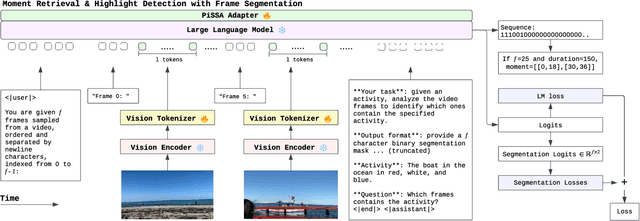
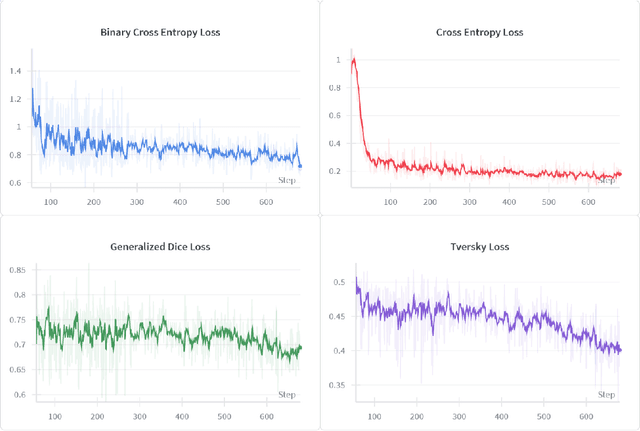
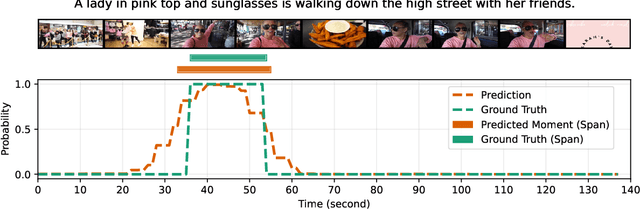
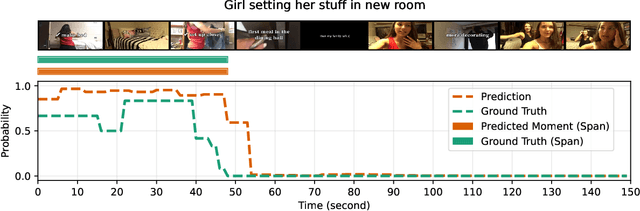
Detecting video moments and highlights from natural-language queries have been unified by transformer-based methods. Other works use generative Multimodal LLM (MLLM) to predict moments and/or highlights as text timestamps, utilizing its reasoning capability. While effective, text-based generation cannot provide direct gradients for frame-level predictions because the model only emits language tokens. Although recent Reinforcement Learning (RL) methods attempt to address the issue, we propose a novel approach by applying segmentation objectives directly on the LLM's output tokens. The LLM is fed with a fixed number of frames alongside a prompt that enforces it to output a sequence of continuous "0" and/or "1" characters, with one character per frame. The "0"/"1" characters benefit from the LLM's inherent language capability while also acting as background and foreground probabilities, respectively. Training employs segmentation losses on the probabilities alongside a normal causal LM loss. At inference, beam search generates sequence and logits, acting as moments and saliency scores, respectively. Despite sampling only 25 frames -- less than half of comparable methods -- our method achieved strong highlight detection (56.74 HIT@1) on QVHighlights. Additionally, our efficient method scores above the baseline (35.28 MAP) for moment retrieval. Empirically, segmentation losses provide a stable complementary learning signal even when the causal LM loss plateaus.
IndoPref: A Multi-Domain Pairwise Preference Dataset for Indonesian
Jul 29, 2025Over 200 million people speak Indonesian, yet the language remains significantly underrepresented in preference-based research for large language models (LLMs). Most existing multilingual datasets are derived from English translations, often resulting in content that lacks cultural and linguistic authenticity. To address this gap, we introduce IndoPref, the first fully human-authored and multi-domain Indonesian preference dataset specifically designed to evaluate the naturalness and quality of LLM-generated text. All annotations are natively written in Indonesian and evaluated using Krippendorff's alpha, demonstrating strong inter-annotator agreement. Additionally, we benchmark the dataset across multiple LLMs and assess the output quality of each model.
What Causes Knowledge Loss in Multilingual Language Models?
Apr 29, 2025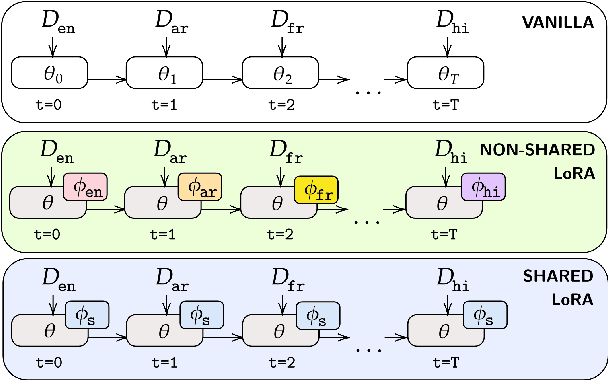
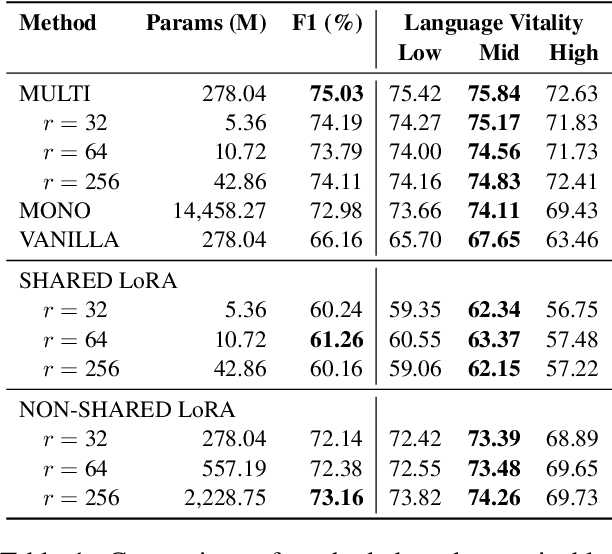
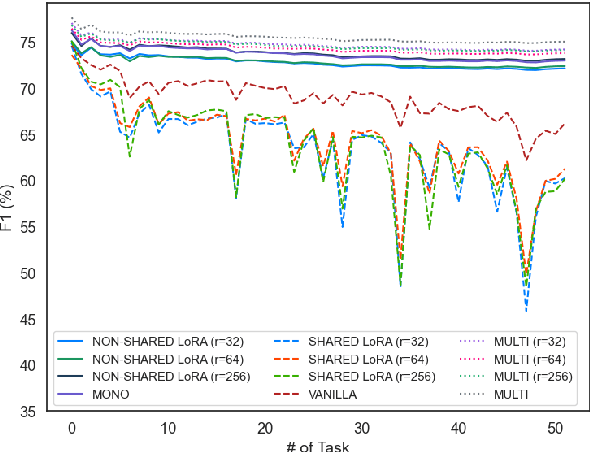
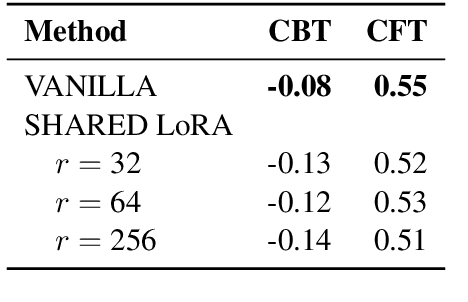
Cross-lingual transfer in natural language processing (NLP) models enhances multilingual performance by leveraging shared linguistic knowledge. However, traditional methods that process all data simultaneously often fail to mimic real-world scenarios, leading to challenges like catastrophic forgetting, where fine-tuning on new tasks degrades performance on previously learned ones. Our study explores this issue in multilingual contexts, focusing on linguistic differences affecting representational learning rather than just model parameters. We experiment with 52 languages using LoRA adapters of varying ranks to evaluate non-shared, partially shared, and fully shared parameters. Our aim is to see if parameter sharing through adapters can mitigate forgetting while preserving prior knowledge. We find that languages using non-Latin scripts are more susceptible to catastrophic forgetting, whereas those written in Latin script facilitate more effective cross-lingual transfer.
QLESS: A Quantized Approach for Data Valuation and Selection in Large Language Model Fine-Tuning
Feb 03, 2025Fine-tuning large language models (LLMs) is often constrained by the computational costs of processing massive datasets. We propose \textbf{QLESS} (Quantized Low-rank Gradient Similarity Search), which integrates gradient quantization with the LESS framework to enable memory-efficient data valuation and selection. QLESS employs a two-step compression process: first, it obtains low-dimensional gradient representations through LoRA-based random projection; then, it quantizes these gradients to low-bitwidth representations. Experiments on multiple LLM architectures (LLaMA, Mistral, Qwen) and benchmarks (MMLU, BBH, TyDiQA) show that QLESS achieves comparable data selection performance to LESS while reducing memory usage by up to 16x. Even 1-bit gradient quantization preserves data valuation quality. These findings underscore QLESS as a practical, scalable approach to identifying informative examples within strict memory constraints.
Continual Learning in Machine Speech Chain Using Gradient Episodic Memory
Nov 27, 2024



Continual learning for automatic speech recognition (ASR) systems poses a challenge, especially with the need to avoid catastrophic forgetting while maintaining performance on previously learned tasks. This paper introduces a novel approach leveraging the machine speech chain framework to enable continual learning in ASR using gradient episodic memory (GEM). By incorporating a text-to-speech (TTS) component within the machine speech chain, we support the replay mechanism essential for GEM, allowing the ASR model to learn new tasks sequentially without significant performance degradation on earlier tasks. Our experiments, conducted on the LJ Speech dataset, demonstrate that our method outperforms traditional fine-tuning and multitask learning approaches, achieving a substantial error rate reduction while maintaining high performance across varying noise conditions. We showed the potential of our semi-supervised machine speech chain approach for effective and efficient continual learning in speech recognition.
DriveThru: a Document Extraction Platform and Benchmark Datasets for Indonesian Local Language Archives
Nov 14, 2024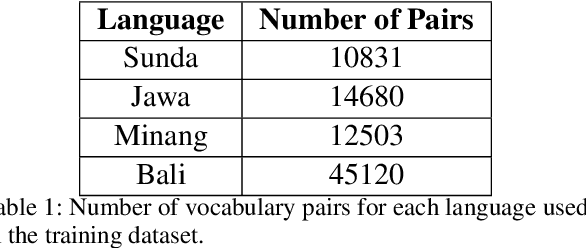
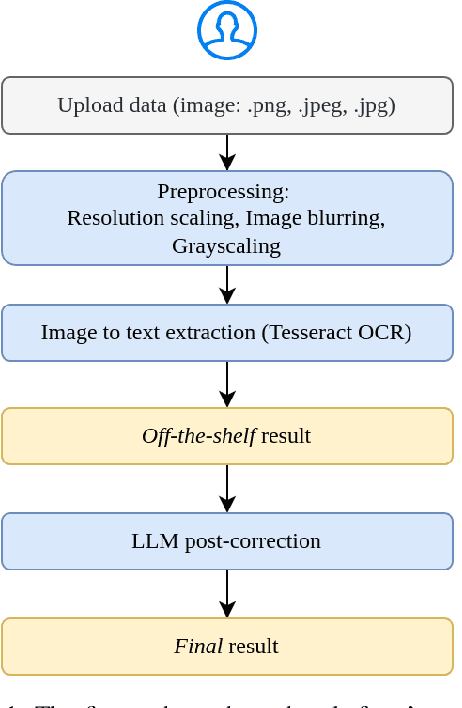
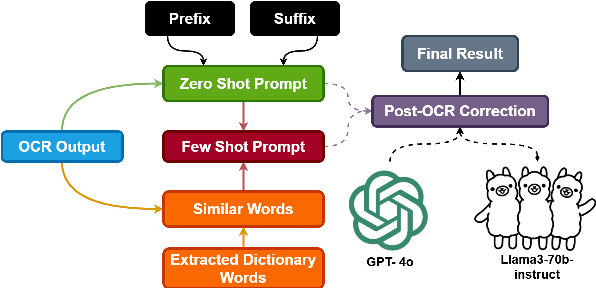
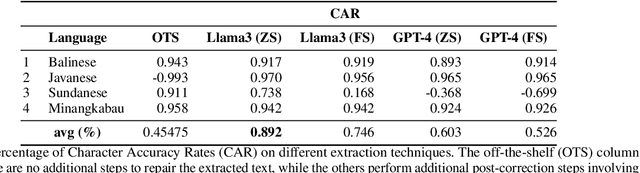
Indonesia is one of the most diverse countries linguistically. However, despite this linguistic diversity, Indonesian languages remain underrepresented in Natural Language Processing (NLP) research and technologies. In the past two years, several efforts have been conducted to construct NLP resources for Indonesian languages. However, most of these efforts have been focused on creating manual resources thus difficult to scale to more languages. Although many Indonesian languages do not have a web presence, locally there are resources that document these languages well in printed forms such as books, magazines, and newspapers. Digitizing these existing resources will enable scaling of Indonesian language resource construction to many more languages. In this paper, we propose an alternative method of creating datasets by digitizing documents, which have not previously been used to build digital language resources in Indonesia. DriveThru is a platform for extracting document content utilizing Optical Character Recognition (OCR) techniques in its system to provide language resource building with less manual effort and cost. This paper also studies the utility of current state-of-the-art LLM for post-OCR correction to show the capability of increasing the character accuracy rate (CAR) and word accuracy rate (WAR) compared to off-the-shelf OCR.
WorldCuisines: A Massive-Scale Benchmark for Multilingual and Multicultural Visual Question Answering on Global Cuisines
Oct 16, 2024



Vision Language Models (VLMs) often struggle with culture-specific knowledge, particularly in languages other than English and in underrepresented cultural contexts. To evaluate their understanding of such knowledge, we introduce WorldCuisines, a massive-scale benchmark for multilingual and multicultural, visually grounded language understanding. This benchmark includes a visual question answering (VQA) dataset with text-image pairs across 30 languages and dialects, spanning 9 language families and featuring over 1 million data points, making it the largest multicultural VQA benchmark to date. It includes tasks for identifying dish names and their origins. We provide evaluation datasets in two sizes (12k and 60k instances) alongside a training dataset (1 million instances). Our findings show that while VLMs perform better with correct location context, they struggle with adversarial contexts and predicting specific regional cuisines and languages. To support future research, we release a knowledge base with annotated food entries and images along with the VQA data.