 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Spoof Voices in Asian Non-Native Speech: An Indonesian and Thai Case Study
Dec 02, 2024


This study focuses on building effective spoofing countermeasures (CMs) for non-native speech, specifically targeting Indonesian and Thai speakers. We constructed a dataset comprising both native and non-native speech to facilitate our research. Three key features (MFCC, LFCC, and CQCC) were extracted from the speech data, and three classic machine learning-based classifiers (CatBoost, XGBoost, and GMM) were employed to develop robust spoofing detection systems using the native and combined (native and non-native) speech data. This resulted in two types of CMs: Native and Combined. The performance of these CMs was evaluated on both native and non-native speech datasets. Our findings reveal significant challenges faced by Native CM in handling non-native speech, highlighting the necessity for domain-specific solutions. The proposed method shows improved detection capabilities, demonstrating the importance of incorporating non-native speech data into the training process. This work lays the foundation for more effective spoofing detection systems in diverse linguistic contexts.
WorldCuisines: A Massive-Scale Benchmark for Multilingual and Multicultural Visual Question Answering on Global Cuisines
Oct 16, 2024



Vision Language Models (VLMs) often struggle with culture-specific knowledge, particularly in languages other than English and in underrepresented cultural contexts. To evaluate their understanding of such knowledge, we introduce WorldCuisines, a massive-scale benchmark for multilingual and multicultural, visually grounded language understanding. This benchmark includes a visual question answering (VQA) dataset with text-image pairs across 30 languages and dialects, spanning 9 language families and featuring over 1 million data points, making it the largest multicultural VQA benchmark to date. It includes tasks for identifying dish names and their origins. We provide evaluation datasets in two sizes (12k and 60k instances) alongside a training dataset (1 million instances). Our findings show that while VLMs perform better with correct location context, they struggle with adversarial contexts and predicting specific regional cuisines and languages. To support future research, we release a knowledge base with annotated food entries and images along with the VQA data.
Enhancing Indonesian Automatic Speech Recognition: Evaluating Multilingual Models with Diverse Speech Variabilities
Oct 11, 2024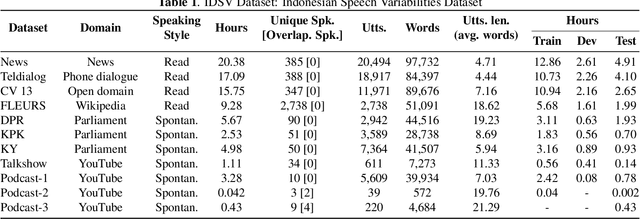
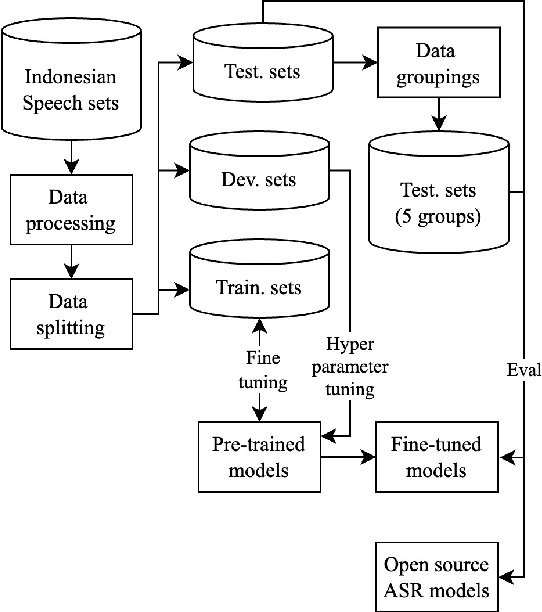
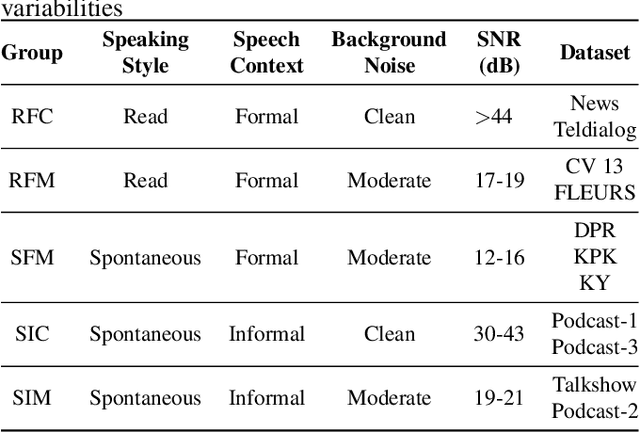
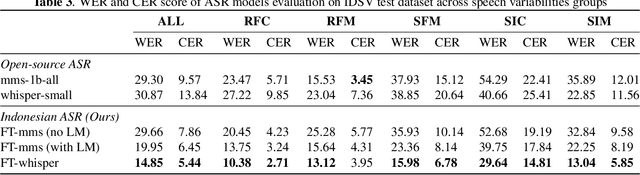
An ideal speech recognition model has the capability to transcribe speech accurately under various characteristics of speech signals, such as speaking style (read and spontaneous), speech context (formal and informal), and background noise conditions (clean and moderate). Building such a model requires a significant amount of training data with diverse speech characteristics. Currently, Indonesian data is dominated by read, formal, and clean speech, leading to a scarcity of Indonesian data with other speech variabilities. To develop Indonesian automatic speech recognition (ASR), we present our research on state-of-the-art speech recognition models, namely Massively Multilingual Speech (MMS) and Whisper, as well as compiling a dataset comprising Indonesian speech with variabilities to facilitate our study. We further investigate the models' predictive ability to transcribe Indonesian speech data across different variability groups. The best results were achieved by the Whisper fine-tuned model across datasets with various characteristics, as indicated by the decrease in word error rate (WER) and character error rate (CER). Moreover, we found that speaking style variability affected model performance the most.