 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-Aware In-Context Learning for Hallucination Mitigation in ALLMs
Apr 10, 2026Auditory large language models (ALLMs) have demonstrated strong general capabilities in audio understanding and reasoning tasks. However, their reliability is still undermined by hallucination issues. Existing hallucination evaluation methods are formulated as binary classification tasks, which are insufficient to characterize the more complex hallucination patterns that arise in generative tasks. Moreover, current hallucination mitigation strategies rely on fine-tuning, resulting in high computational costs. To address the above limitations, we propose a plug-and-play Noise-Aware In-Context Learning (NAICL) method. Specifically, we construct a noise prior library, retrieve noise examples relevant to the input audio, and incorporate them as contextual priors, thereby guiding the model to reduce speculative associations when acoustic evidence is insufficient and to adopt a more conservative generation strategy. In addition, we establish a hallucination benchmark for audio caption tasks including the construction of the Clotho-1K multi-event benchmark dataset, the definition of four types of auditory hallucinations, and the introduction of metrics such as hallucination type distribution to support fine-grained analysis. Experimental results show that all evaluated ALLMs exhibit same hallucination behaviors. Moreover, the proposed NAICL method reduces the overall hallucination rate from 26.53% to 16.98%.
Modeling Multi-Level Hearing Loss for Speech Intelligibility Prediction
Jul 30, 2025The diverse perceptual consequences of hearing loss severely impede speech communication, but standard clinical audiometry, which is focused on threshold-based frequency sensitivity, does not adequately capture deficits in frequency and temporal resolution. To address this limitation, we propose a speech intelligibility prediction method that explicitly simulates auditory degradations according to hearing loss severity by broadening cochlear filters and applying low-pass modulation filtering to temporal envelopes. Speech signals are subsequently analyzed using the spectro-temporal modulation (STM) representations, which reflect how auditory resolution loss alters the underlying modulation structure. In addition, normalized cross-correlation (NCC) matrices quantify the similarity between the STM representations of clean speech and speech in noise. These auditory-informed features are utilized to train a Vision Transformer-based regression model that integrates the STM maps and NCC embeddings to estimate speech intelligibility scores. Evaluations on the Clarity Prediction Challenge corpus show that the proposed method outperforms the Hearing-Aid Speech Perception Index v2 (HASPI v2) in both mild and moderate-to-severe hearing loss groups, with a relative root mean squared error reduction of 16.5% for the mild group and a 6.1% reduction for the moderate-to-severe group. These results highlight the importance of explicitly modeling listener-specific frequency and temporal resolution degradations to improve speech intelligibility prediction and provide interpretability in auditory distortions.
Detecting Spoof Voices in Asian Non-Native Speech: An Indonesian and Thai Case Study
Dec 02, 2024


This study focuses on building effective spoofing countermeasures (CMs) for non-native speech, specifically targeting Indonesian and Thai speakers. We constructed a dataset comprising both native and non-native speech to facilitate our research. Three key features (MFCC, LFCC, and CQCC) were extracted from the speech data, and three classic machine learning-based classifiers (CatBoost, XGBoost, and GMM) were employed to develop robust spoofing detection systems using the native and combined (native and non-native) speech data. This resulted in two types of CMs: Native and Combined. The performance of these CMs was evaluated on both native and non-native speech datasets. Our findings reveal significant challenges faced by Native CM in handling non-native speech, highlighting the necessity for domain-specific solutions. The proposed method shows improved detection capabilities, demonstrating the importance of incorporating non-native speech data into the training process. This work lays the foundation for more effective spoofing detection systems in diverse linguistic contexts.
Machine Anomalous Sound Detection Using Spectral-temporal Modulation Representations Derived from Machine-specific Filterbanks
Sep 09, 2024Early detection of factory machinery malfunctions is crucial in industrial applications. In machine anomalous sound detection (ASD), different machines exhibit unique vibration-frequency ranges based on their physical properties. Meanwhile, the human auditory system is adept at tracking both temporal and spectral dynamics of machine sounds. Consequently, integrating the computational auditory models of the human auditory system with machine-specific properties can be an effective approach to machine ASD. We first quantified the frequency importances of four types of machines using the Fisher ratio (F-ratio). The quantified frequency importances were then used to design machine-specific non-uniform filterbanks (NUFBs), which extract the log non-uniform spectrum (LNS) feature. The designed NUFBs have a narrower bandwidth and higher filter distribution density in frequency regions with relatively high F-ratios. Finally, spectral and temporal modulation representations derived from the LNS feature were proposed. These proposed LNS feature and modulation representations are input into an autoencoder neural-network-based detector for ASD. The quantification results from the training set of the Malfunctioning Industrial Machine Investigation and Inspection dataset with a signal-to-noise (SNR) of 6 dB reveal that the distinguishing information between normal and anomalous sounds of different machines is encoded non-uniformly in the frequency domain. By highlighting these important frequency regions using NUFBs, the LNS feature can significantly enhance performance using the metric of AUC (area under the receiver operating characteristic curve) under various SNR conditions. Furthermore, modulation representations can further improve performance. Specifically, temporal modulation is effective for fans, pumps, and sliders, while spectral modulation is particularly effective for valves.
Computational models of sound-quality metrics using method for calculating loudness with gammatone/gammachirp auditory filterbank
May 19, 2023



Sound-quality metrics (SQMs), such as sharpness, roughness, and fluctuation strength, are calculated using a standard method for calculating loudness (Zwicker method, ISO532B, 1975). Since ISO 532 had been revised to contain the Zwicker method (ISO 5321) and Moore-Glasberg method (ISO 532-2) in 2017, the classical computational SQM model should also be revised in accordance with these revisions. A roex auditory filterbank used with the Moore-Glasberg method is defined separately in the frequency domain not to have impulse responses. It is therefore difficult to construct a computational SQM model, e.g., the classical computational SQM model, on the basis of ISO 532-2. We propose a method for calculating loudness using the time-domain gammatone or gammachirp auditory filterbank instead of the roex auditory filterbank to solve this problem. We also propose three computational SQM models based on ISO 532-2 to use with the proposed loudness method. We evaluated the root-mean squared errors (RMSEs) of the calculated loudness with the proposed and Moore-Glasberg methods. We then evaluated the RMSEs of the calculated SQMs with the proposed method and human data of SQMs. We found that the proposed method can be considered as a time-domain method for calculating loudness on the basis of ISO 532-2 because the RMSEs are very small. We also found that the proposed computational SQM models can effectively account for the human data of SQMs compared with the classical computational SQM model in terms of RMSEs.
Blind estimation of room acoustic parameters from speech signals based on extended model of room impulse response
Dec 26, 2022The speech transmission index (STI) and room acoustic parameters (RAPs), which are derived from a room impulse response (RIR), such as reverberation time and early decay time, are essential to assess speech transmission and to predict the listening difficulty in a sound field. Since it is difficult to measure RIR in daily occupied spaces, simultaneous blind estimation of STI and RAPs must be resolved as it is an imperative and challenging issue. This paper proposes a deterministic method for blindly estimating STI and five RAPs on the basis of an RIR stochastic model that approximates an unknown RIR. The proposed method formulates a temporal power envelope of a reverberant speech signal to obtain the optimal parameters for the RIR model. Simulations were conducted to evaluate STI and RAPs from observed reverberant speech signals. The root-mean-square errors between the estimated and ground-truth results were used to comparatively evaluate the proposed method with the previous method. The results showed that the proposed method can estimate STI and RAPs effectively without any training.
Improving Security in McAdams Coefficient-Based Speaker Anonymization by Watermarking Method
Jul 15, 2021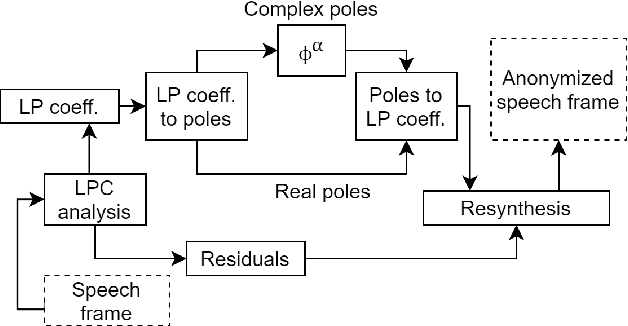
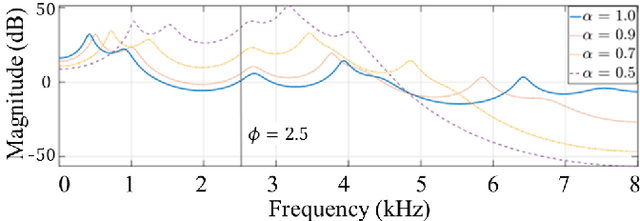
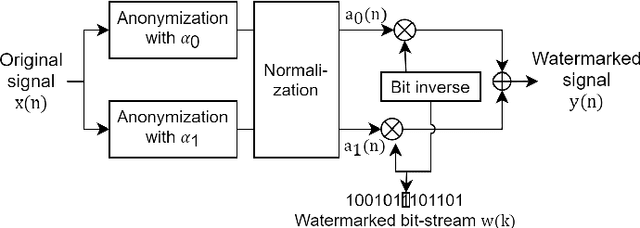
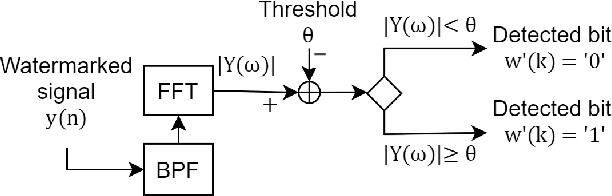
Speaker anonymization aims to suppress speaker individuality to protect privacy in speech while preserving the other aspects, such as speech content. One effective solution for anonymization is to modify the McAdams coefficient. In this work, we propose a method to improve the security for speaker anonymization based on the McAdams coefficient by using a speech watermarking approach. The proposed method consists of two main processes: one for embedding and one for detection. In embedding process, two different McAdams coefficients represent binary bits ``0" and ``1". The watermarked speech is then obtained by frame-by-frame bit inverse switching. Subsequently, the detection process is carried out by a power spectrum comparison. We conducted objective evaluations with reference to the VoicePrivacy 2020 Challenge (VP2020) and of the speech watermarking with reference to the Information Hiding Challenge (IHC) and found that our method could satisfy the blind detection, inaudibility, and robustness requirements in watermarking. It also significantly improved the anonymization performance in comparison to the secondary baseline system in VP2020.
Blind Estimation of Room Acoustic Parameters and Speech Transmission Index using MTF-based CNNs
Mar 14, 2021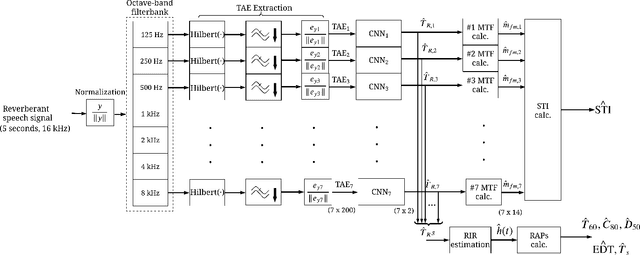
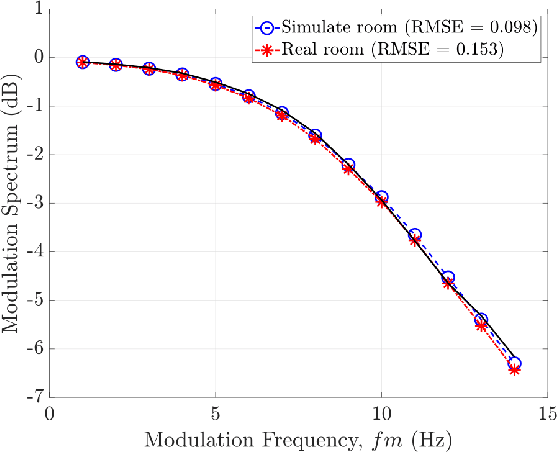
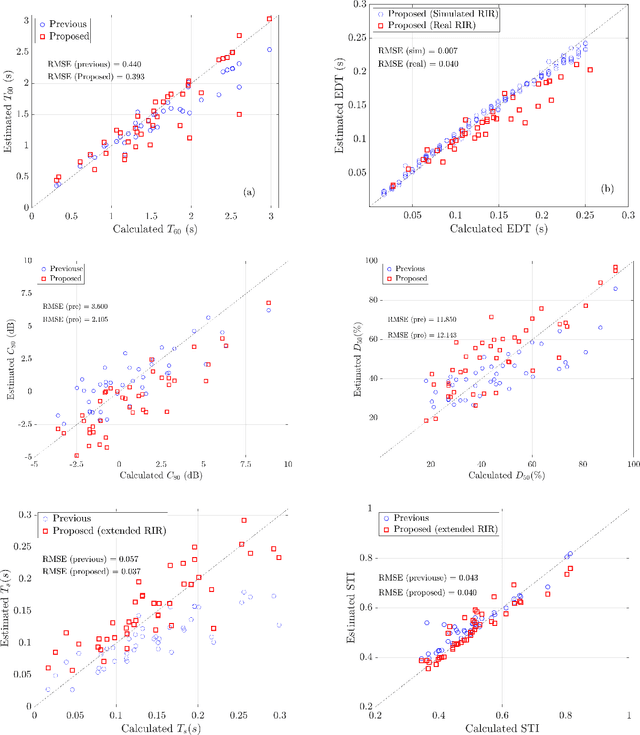
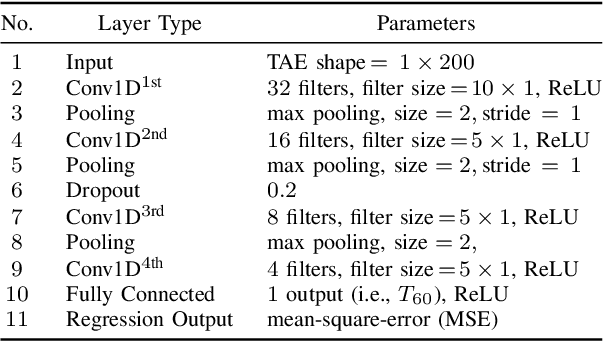
This paper proposes a blind estimation method based on the modulation transfer function and Schroeder model for estimating reverberation time in seven-octave bands. Therefore, the speech transmission index and five room-acoustic parameters can be estimated.
Evolving Multi-Resolution Pooling CNN for Monaural Singing Voice Separation
Aug 03, 2020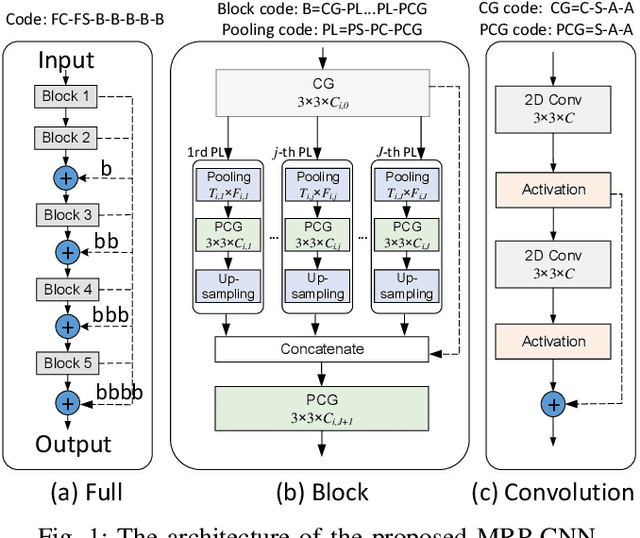
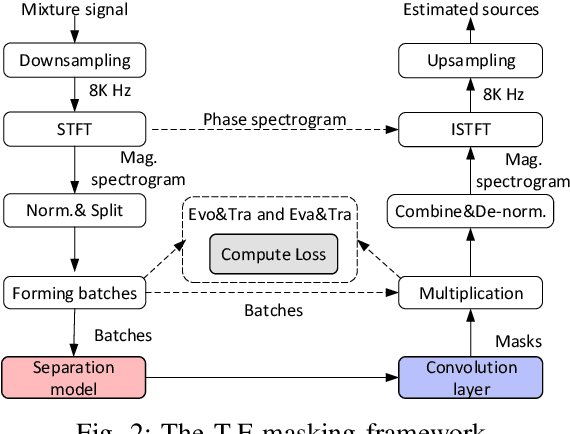
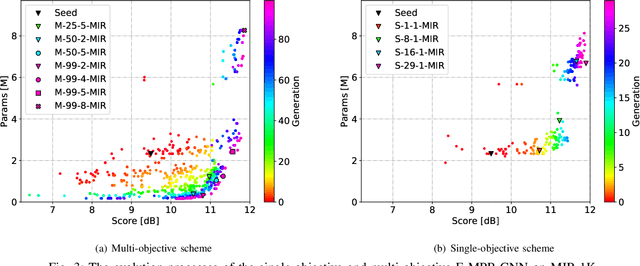
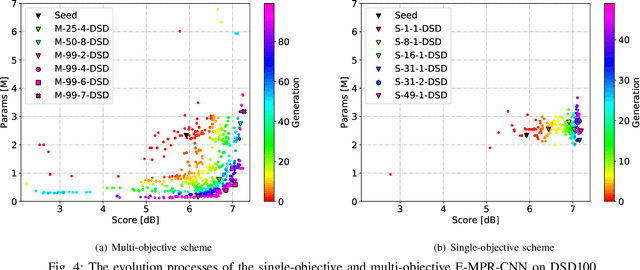
Monaural Singing Voice Separation (MSVS) is a challenging task and has been studied for decades. Deep neural networks (DNNs) are the current state-of-the-art methods for MSVS. However, the existing DNNs are often designed manually, which is time-consuming and error-prone. In addition, the network architectures are usually pre-defined, and not adapted to the training data. To address these issues, we introduce a Neural Architecture Search (NAS) method to the structure design of DNNs for MSVS. Specifically, we propose a new multi-resolution Convolutional Neural Network (CNN) framework for MSVS namely Multi-Resolution Pooling CNN (MRP-CNN), which uses various-size pooling operators to extract multi-resolution features. Based on the NAS, we then develop an evolving framework namely Evolving MRP-CNN (E-MRP-CNN), by automatically searching the effective MRP-CNN structures using genetic algorithms, optimized in terms of a single-objective considering only separation performance, or multi-objective considering both the separation performance and the model complexity. The multi-objective E-MRP-CNN gives a set of Pareto-optimal solutions, each providing a trade-off between separation performance and model complexity. Quantitative and qualitative evaluations on the MIR-1K and DSD100 datasets are used to demonstrate the advantages of the proposed framework over several recent baselines.