 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolving Multi-Resolution Pooling CNN for Monaural Singing Voice Separation
Aug 03, 2020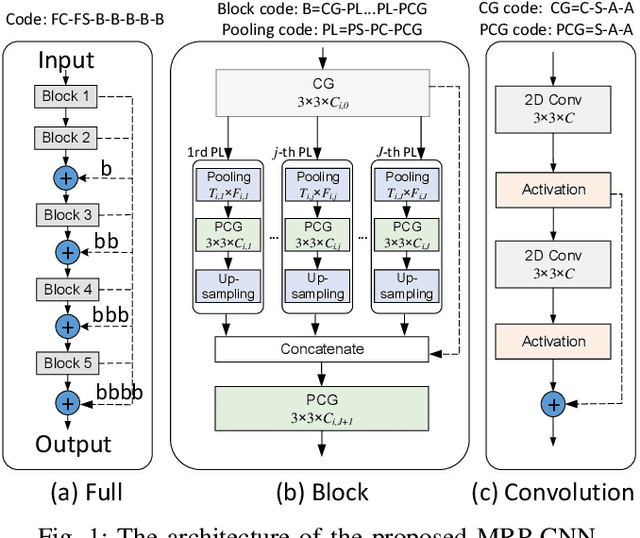
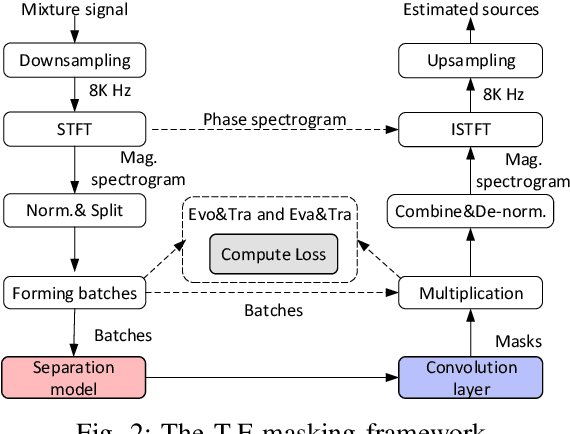
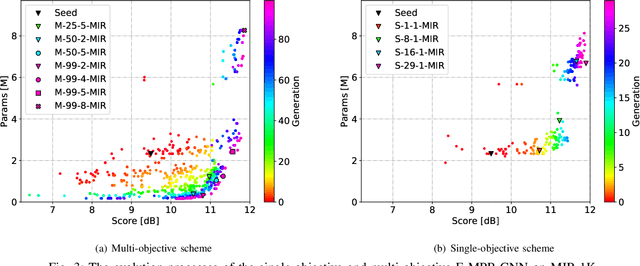
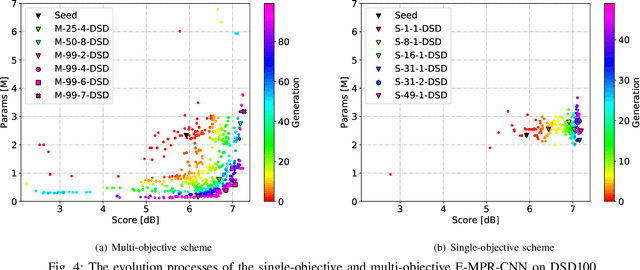
Monaural Singing Voice Separation (MSVS) is a challenging task and has been studied for decades. Deep neural networks (DNNs) are the current state-of-the-art methods for MSVS. However, the existing DNNs are often designed manually, which is time-consuming and error-prone. In addition, the network architectures are usually pre-defined, and not adapted to the training data. To address these issues, we introduce a Neural Architecture Search (NAS) method to the structure design of DNNs for MSVS. Specifically, we propose a new multi-resolution Convolutional Neural Network (CNN) framework for MSVS namely Multi-Resolution Pooling CNN (MRP-CNN), which uses various-size pooling operators to extract multi-resolution features. Based on the NAS, we then develop an evolving framework namely Evolving MRP-CNN (E-MRP-CNN), by automatically searching the effective MRP-CNN structures using genetic algorithms, optimized in terms of a single-objective considering only separation performance, or multi-objective considering both the separation performance and the model complexity. The multi-objective E-MRP-CNN gives a set of Pareto-optimal solutions, each providing a trade-off between separation performance and model complexity. Quantitative and qualitative evaluations on the MIR-1K and DSD100 datasets are used to demonstrate the advantages of the proposed framework over several recent baselines.