 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Multi-Level Hearing Loss for Speech Intelligibility Prediction
Jul 30, 2025The diverse perceptual consequences of hearing loss severely impede speech communication, but standard clinical audiometry, which is focused on threshold-based frequency sensitivity, does not adequately capture deficits in frequency and temporal resolution. To address this limitation, we propose a speech intelligibility prediction method that explicitly simulates auditory degradations according to hearing loss severity by broadening cochlear filters and applying low-pass modulation filtering to temporal envelopes. Speech signals are subsequently analyzed using the spectro-temporal modulation (STM) representations, which reflect how auditory resolution loss alters the underlying modulation structure. In addition, normalized cross-correlation (NCC) matrices quantify the similarity between the STM representations of clean speech and speech in noise. These auditory-informed features are utilized to train a Vision Transformer-based regression model that integrates the STM maps and NCC embeddings to estimate speech intelligibility scores. Evaluations on the Clarity Prediction Challenge corpus show that the proposed method outperforms the Hearing-Aid Speech Perception Index v2 (HASPI v2) in both mild and moderate-to-severe hearing loss groups, with a relative root mean squared error reduction of 16.5% for the mild group and a 6.1% reduction for the moderate-to-severe group. These results highlight the importance of explicitly modeling listener-specific frequency and temporal resolution degradations to improve speech intelligibility prediction and provide interpretability in auditory distortions.
Detecting Spoof Voices in Asian Non-Native Speech: An Indonesian and Thai Case Study
Dec 02, 2024


This study focuses on building effective spoofing countermeasures (CMs) for non-native speech, specifically targeting Indonesian and Thai speakers. We constructed a dataset comprising both native and non-native speech to facilitate our research. Three key features (MFCC, LFCC, and CQCC) were extracted from the speech data, and three classic machine learning-based classifiers (CatBoost, XGBoost, and GMM) were employed to develop robust spoofing detection systems using the native and combined (native and non-native) speech data. This resulted in two types of CMs: Native and Combined. The performance of these CMs was evaluated on both native and non-native speech datasets. Our findings reveal significant challenges faced by Native CM in handling non-native speech, highlighting the necessity for domain-specific solutions. The proposed method shows improved detection capabilities, demonstrating the importance of incorporating non-native speech data into the training process. This work lays the foundation for more effective spoofing detection systems in diverse linguistic contexts.
WorldCuisines: A Massive-Scale Benchmark for Multilingual and Multicultural Visual Question Answering on Global Cuisines
Oct 16, 2024



Vision Language Models (VLMs) often struggle with culture-specific knowledge, particularly in languages other than English and in underrepresented cultural contexts. To evaluate their understanding of such knowledge, we introduce WorldCuisines, a massive-scale benchmark for multilingual and multicultural, visually grounded language understanding. This benchmark includes a visual question answering (VQA) dataset with text-image pairs across 30 languages and dialects, spanning 9 language families and featuring over 1 million data points, making it the largest multicultural VQA benchmark to date. It includes tasks for identifying dish names and their origins. We provide evaluation datasets in two sizes (12k and 60k instances) alongside a training dataset (1 million instances). Our findings show that while VLMs perform better with correct location context, they struggle with adversarial contexts and predicting specific regional cuisines and languages. To support future research, we release a knowledge base with annotated food entries and images along with the VQA data.
Improving Security in McAdams Coefficient-Based Speaker Anonymization by Watermarking Method
Jul 15, 2021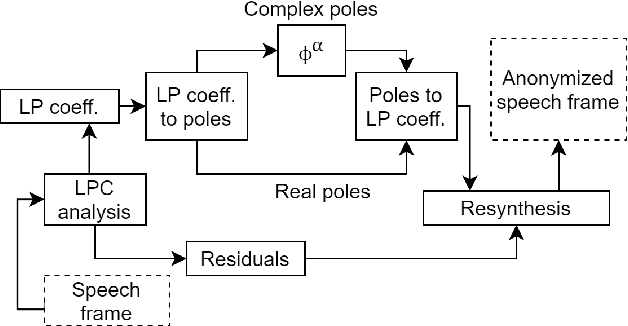
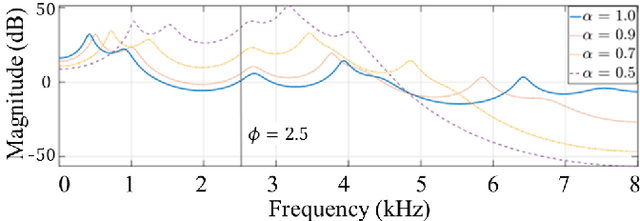
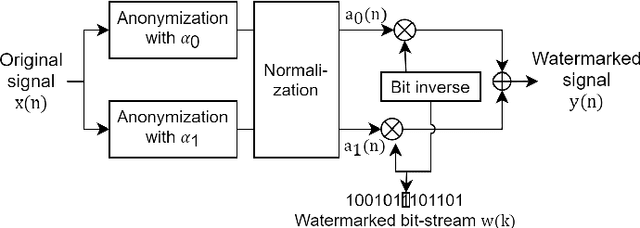
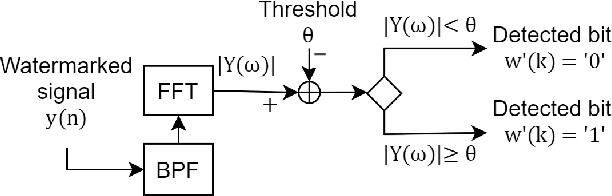
Speaker anonymization aims to suppress speaker individuality to protect privacy in speech while preserving the other aspects, such as speech content. One effective solution for anonymization is to modify the McAdams coefficient. In this work, we propose a method to improve the security for speaker anonymization based on the McAdams coefficient by using a speech watermarking approach. The proposed method consists of two main processes: one for embedding and one for detection. In embedding process, two different McAdams coefficients represent binary bits ``0" and ``1". The watermarked speech is then obtained by frame-by-frame bit inverse switching. Subsequently, the detection process is carried out by a power spectrum comparison. We conducted objective evaluations with reference to the VoicePrivacy 2020 Challenge (VP2020) and of the speech watermarking with reference to the Information Hiding Challenge (IHC) and found that our method could satisfy the blind detection, inaudibility, and robustness requirements in watermarking. It also significantly improved the anonymization performance in comparison to the secondary baseline system in VP2020.