 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Anomalous Sound Detection Using Spectral-temporal Modulation Representations Derived from Machine-specific Filterbanks
Sep 09, 2024Early detection of factory machinery malfunctions is crucial in industrial applications. In machine anomalous sound detection (ASD), different machines exhibit unique vibration-frequency ranges based on their physical properties. Meanwhile, the human auditory system is adept at tracking both temporal and spectral dynamics of machine sounds. Consequently, integrating the computational auditory models of the human auditory system with machine-specific properties can be an effective approach to machine ASD. We first quantified the frequency importances of four types of machines using the Fisher ratio (F-ratio). The quantified frequency importances were then used to design machine-specific non-uniform filterbanks (NUFBs), which extract the log non-uniform spectrum (LNS) feature. The designed NUFBs have a narrower bandwidth and higher filter distribution density in frequency regions with relatively high F-ratios. Finally, spectral and temporal modulation representations derived from the LNS feature were proposed. These proposed LNS feature and modulation representations are input into an autoencoder neural-network-based detector for ASD. The quantification results from the training set of the Malfunctioning Industrial Machine Investigation and Inspection dataset with a signal-to-noise (SNR) of 6 dB reveal that the distinguishing information between normal and anomalous sounds of different machines is encoded non-uniformly in the frequency domain. By highlighting these important frequency regions using NUFBs, the LNS feature can significantly enhance performance using the metric of AUC (area under the receiver operating characteristic curve) under various SNR conditions. Furthermore, modulation representations can further improve performance. Specifically, temporal modulation is effective for fans, pumps, and sliders, while spectral modulation is particularly effective for valves.
Two-stage dimensional emotion recognition by fusing predictions of acoustic and text networks using SVM
Oct 26, 2022Automatic speech emotion recognition (SER) by a computer is a critical component for more natural human-machine interaction. As in human-human interaction, the capability to perceive emotion correctly is essential to take further steps in a particular situation. One issue in SER is whether it is necessary to combine acoustic features with other data such as facial expressions, text, and motion capture. This research proposes to combine acoustic and text information by applying a late-fusion approach consisting of two steps. First, acoustic and text features are trained separately in deep learning systems. Second, the prediction results from the deep learning systems are fed into a support vector machine (SVM) to predict the final regression score. Furthermore, the task in this research is dimensional emotion modeling because it can enable a deeper analysis of affective states. Experimental results show that this two-stage, late-fusion approach, obtains higher performance than that of any one-stage processing, with a linear correlation from one-stage to two-stage processing. This late-fusion approach improves previous early fusion results measured in concordance correlation coefficients score.
* Published in Speech Communications
Speak Like a Professional: Increasing Speech Intelligibility by Mimicking Professional Announcer Voice with Voice Conversion
Jun 27, 2022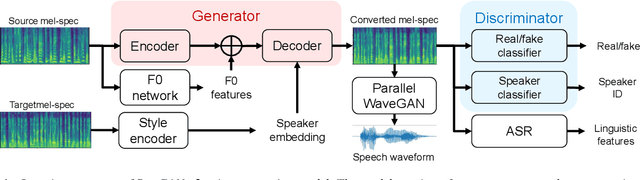



In most of practical scenarios, the announcement system must deliver speech messages in a noisy environment, in which the background noise cannot be cancelled out. The local noise reduces speech intelligibility and increases listening effort of the listener, hence hamper the effectiveness of announcement system. There has been reported that voices of professional announcers are clearer and more comprehensive than that of non-expert speakers in noisy environment. This finding suggests that the speech intelligibility might be related to the speaking style of professional announcer, which can be adapted using voice conversion method. Motivated by this idea, this paper proposes a speech intelligibility enhancement in noisy environment by applying voice conversion method on non-professional voice. We discovered that the professional announcers and non-professional speakers are clusterized into different clusters on the speaker embedding plane. This implies that the speech intelligibility can be controlled as an independent feature of speaker individuality. To examine the advantage of converted voice in noisy environment, we experimented using test words masked in pink noise at different SNR levels. The results of objective and subjective evaluations confirm that the speech intelligibility of converted voice is higher than that of original voice in low SNR conditions.