 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Based Ensemble Learning For Speech Classification
Jul 24, 2024Speech classification has attracted increasing attention due to its wide applications, particularly in classifying physical and mental states. However, these tasks are challenging due to the high variability in speech signals. Ensemble learning has shown promising results when multiple classifiers are combined to improve performance. With recent advancements in hardware development, combining several models is not a limitation in deep learning research and applications. In this paper, we propose an uncertainty-based ensemble learning approach for speech classification. Specifically, we train a set of base features on the same classifier and quantify the uncertainty of their predictions. The predictions are combined using variants of uncertainty calculation to produce the final prediction. The visualization of the effect of uncertainty and its ensemble learning results show potential improvements in speech classification tasks. The proposed method outperforms single models and conventional ensemble learning methods in terms of unweighted accuracy or weighted accuracy.
Ensembling Multilingual Pre-Trained Models for Predicting Multi-Label Regression Emotion Share from Speech
Sep 20, 2023Speech emotion recognition has evolved from research to practical applications. Previous studies of emotion recognition from speech have focused on developing models on certain datasets like IEMOCAP. The lack of data in the domain of emotion modeling emerges as a challenge to evaluate models in the other dataset, as well as to evaluate speech emotion recognition models that work in a multilingual setting. This paper proposes an ensemble learning to fuse results of pre-trained models for emotion share recognition from speech. The models were chosen to accommodate multilingual data from English and Spanish. The results show that ensemble learning can improve the performance of the baseline model with a single model and the previous best model from the late fusion. The performance is measured using the Spearman rank correlation coefficient since the task is a regression problem with ranking values. A Spearman rank correlation coefficient of 0.537 is reported for the test set, while for the development set, the score is 0.524. These scores are higher than the previous study of a fusion method from monolingual data, which achieved scores of 0.476 for the test and 0.470 for the development.
Lab-scale Vibration Analysis Dataset and Baseline Methods for Machinery Fault Diagnosis with Machine Learning
Dec 27, 2022The monitoring of machine conditions in a plant is crucial for production in manufacturing. A sudden failure of a machine can stop production and cause a loss of revenue. The vibration signal of a machine is a good indicator of its condition. This paper presents a dataset of vibration signals from a lab-scale machine. The dataset contains four different types of machine conditions: normal, unbalance, misalignment, and bearing fault. Three machine learning methods (SVM, KNN, and GNB) evaluated the dataset, and a perfect result was obtained by one of the methods on a 1-fold test. The performance of the algorithms is evaluated using weighted accuracy (WA) since the data is balanced. The results show that the best-performing algorithm is the SVM with a WA of 99.75\% on the 5-fold cross-validations. The dataset is provided in the form of CSV files in an open and free repository at https://zenodo.org/record/7006575.
Effect of different splitting criteria on the performance of speech emotion recognition
Oct 26, 2022Traditional speech emotion recognition (SER) evaluations have been performed merely on a speaker-independent condition; some of them even did not evaluate their result on this condition. This paper highlights the importance of splitting training and test data for SER by script, known as sentence-open or text-independent criteria. The results show that employing sentence-open criteria degraded the performance of SER. This finding implies the difficulties of recognizing emotion from speech in different linguistic information embedded in acoustic information. Surprisingly, text-independent criteria consistently performed worse than speaker+text-independent criteria. The full order of difficulties for splitting criteria on SER performances from the most difficult to the easiest is text-independent, speaker+text-independent, speaker-independent, and speaker+text-dependent. The gap between speaker+text-independent and text-independent was smaller than other criteria, strengthening the difficulties of recognizing emotion from speech in different sentences.
* Accepted at TENCON 2021
Two-stage dimensional emotion recognition by fusing predictions of acoustic and text networks using SVM
Oct 26, 2022Automatic speech emotion recognition (SER) by a computer is a critical component for more natural human-machine interaction. As in human-human interaction, the capability to perceive emotion correctly is essential to take further steps in a particular situation. One issue in SER is whether it is necessary to combine acoustic features with other data such as facial expressions, text, and motion capture. This research proposes to combine acoustic and text information by applying a late-fusion approach consisting of two steps. First, acoustic and text features are trained separately in deep learning systems. Second, the prediction results from the deep learning systems are fed into a support vector machine (SVM) to predict the final regression score. Furthermore, the task in this research is dimensional emotion modeling because it can enable a deeper analysis of affective states. Experimental results show that this two-stage, late-fusion approach, obtains higher performance than that of any one-stage processing, with a linear correlation from one-stage to two-stage processing. This late-fusion approach improves previous early fusion results measured in concordance correlation coefficients score.
* Published in Speech Communications
Cross-dataset COVID-19 Transfer Learning with Cough Detection, Cough Segmentation, and Data Augmentation
Oct 12, 2022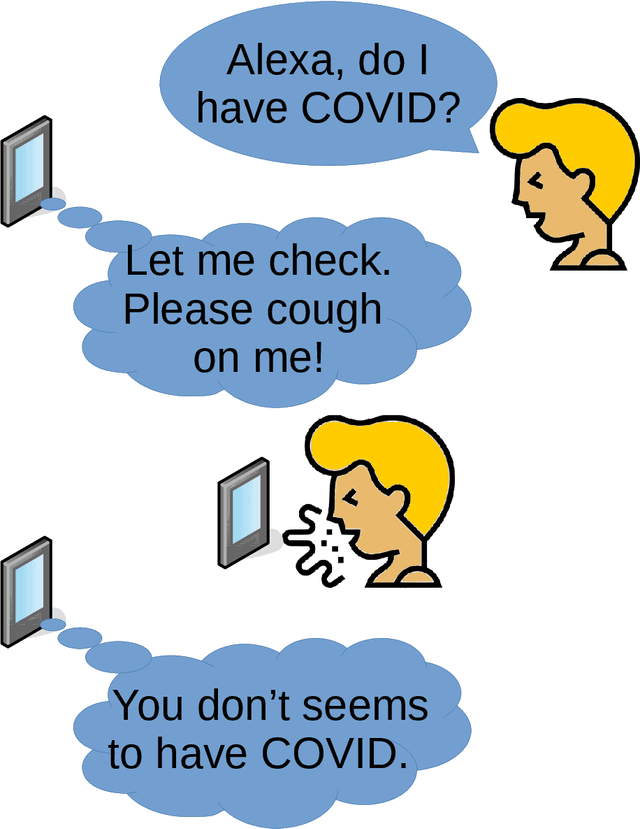
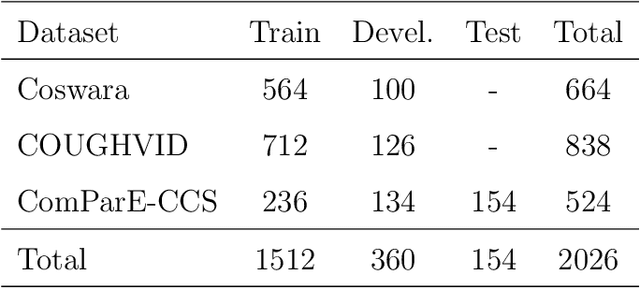
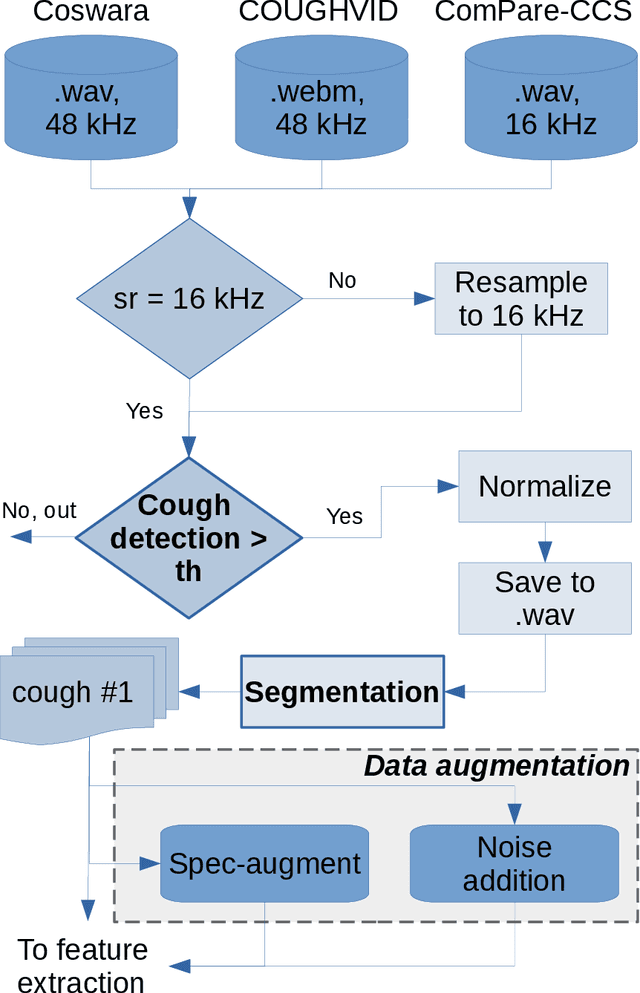
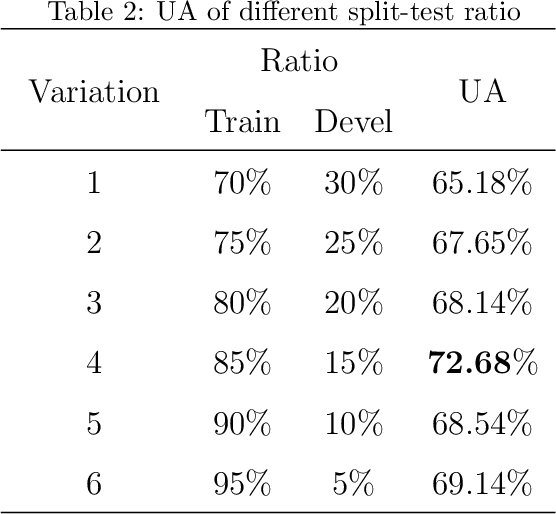
This paper addresses issues on cough-based COVID-19 detection. We propose a cross-dataset transfer learning approach to improve the performance of COVID-19 detection by incorporating cough detection, cough segmentation, and data augmentation. The first aimed at removing non-cough signals and cough signals with low probability. The second aimed at segregating several coughs in a waveform into individual coughs. The third aimed at increasing the number of samples for the deep learning model. These three processing blocks are important as our finding revealed a large margin of improvement relative to the baseline methods without these blocks. An ablation study is conducted to optimize hyperparameters and it was found that alpha mixup is an important factor among others in improving the model performance via this augmentation method. A summary of this study with previous studies on the same evaluation set was given to gain insights into different methods of cough-based COVID-19 detection.
Evaluation of Automatic Single Cough Segmentation
Oct 05, 2022
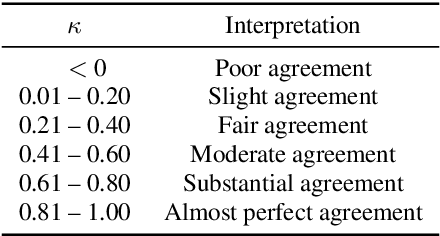
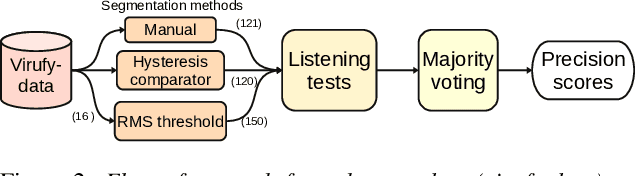
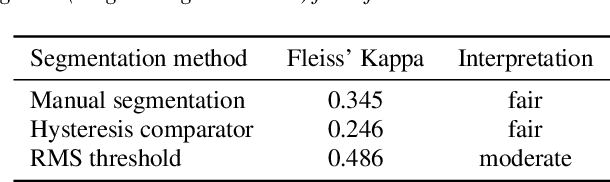
Research on diagnosing diseases based on voice signals currently are rapidly increasing, including cough-related diseases. When training the cough sound signals into deep learning models, it is necessary to have a standard input by segmenting several cough signals into individual cough signals. Previous research has been developed to segment cough signals from non-cough signals. This research evaluates the segmentation methods of several cough signals from a single audio file into several single-cough signals. We evaluate three different methods employing manual segmentation as a baseline and automatic segmentation. The results by two automatic segmentation methods obtained precisions of 73% and 70% compared to 49% by manual segmentation. The agreements of listening tests to count the number of correct single-cough segmentations show fair and moderate correlations for automatic segmentation methods and are comparable with manual segmentation.
Predicting Affective Vocal Bursts with Finetuned wav2vec 2.0
Sep 27, 2022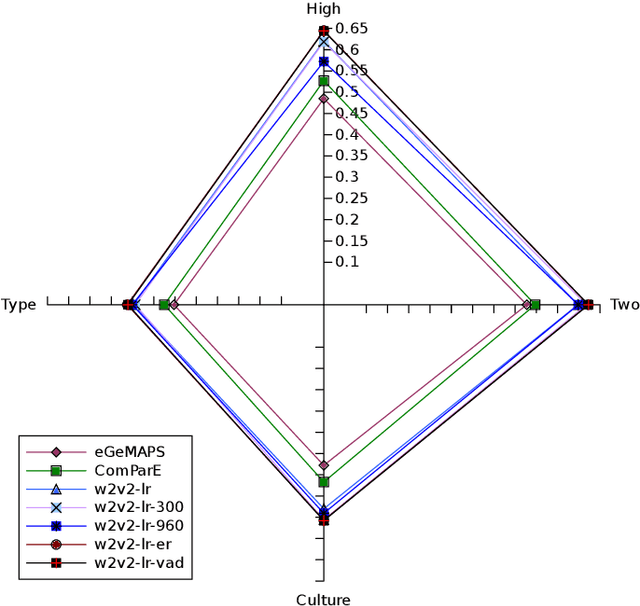


The studies of predicting affective states from human voices have relied heavily on speech. This study, indeed, explores the recognition of humans' affective state from their vocal burst, a short non-verbal vocalization. Borrowing the idea from the recent success of wav2vec 2.0, we evaluated finetuned wav2vec 2.0 models from different datasets to predict the affective state of the speaker from their vocal burst. The finetuned wav2vec 2.0 models are then trained on the vocal burst data. The results show that the finetuned wav2vec 2.0 models, particularly on an affective speech dataset, outperform the baseline model, which is handcrafted acoustic features. However, there is no large gap between the model finetuned on non-affective speech dataset and affective speech dataset.
Jointly Predicting Emotion, Age, and Country Using Pre-Trained Acoustic Embedding
Jul 21, 2022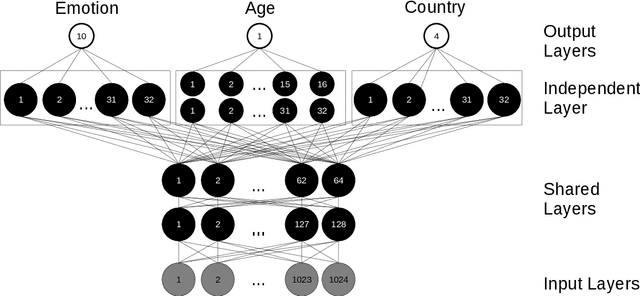
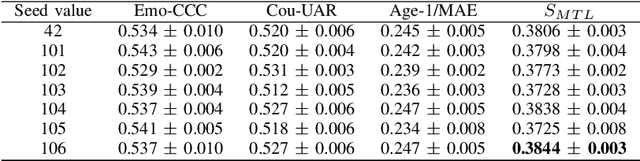
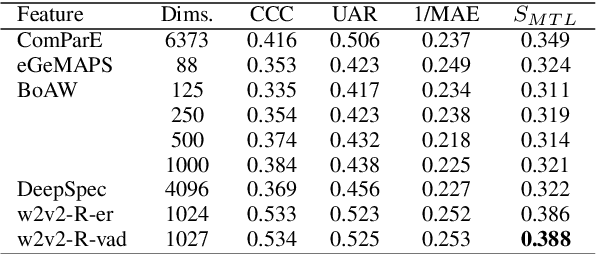
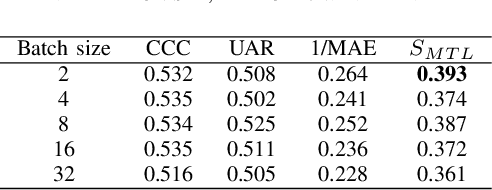
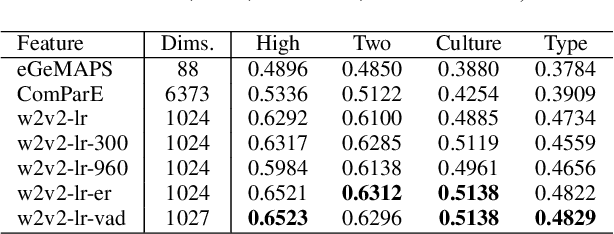
In this paper, we demonstrated the benefit of using pre-trained model to extract acoustic embedding to jointly predict (multitask learning) three tasks: emotion, age, and native country. The pre-trained model was trained with wav2vec 2.0 large robust model on the speech emotion corpus. The emotion and age tasks were regression problems, while country prediction was a classification task. A single harmonic mean from three metrics was used to evaluate the performance of multitask learning. The classifier was a linear network with two independent layers and shared layers, including the output layers. This study explores multitask learning on different acoustic features (including the acoustic embedding extracted from a model trained on an affective speech dataset), seed numbers, batch sizes, and normalizations for predicting paralinguistic information from speech.