 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Affective Vocal Bursts with Finetuned wav2vec 2.0
Paper and Code
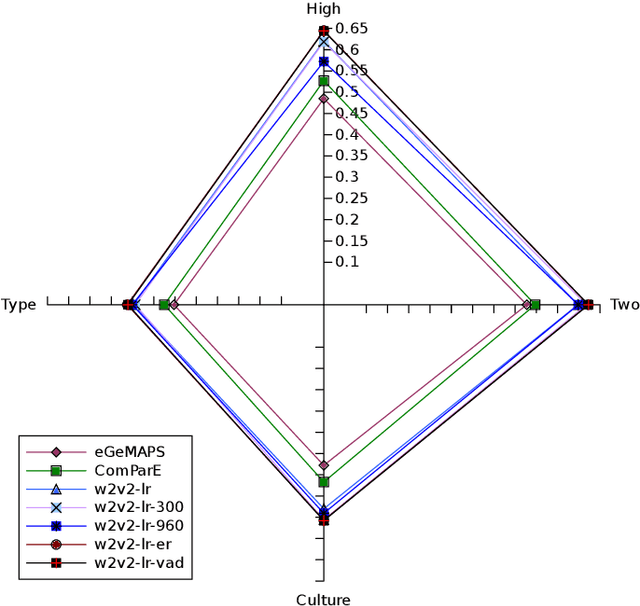


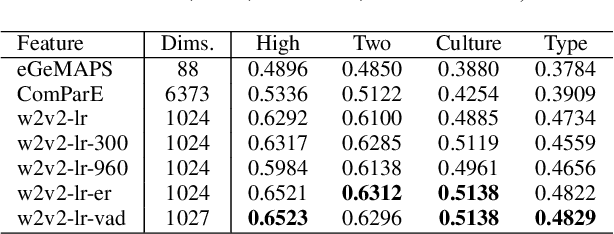
The studies of predicting affective states from human voices have relied heavily on speech. This study, indeed, explores the recognition of humans' affective state from their vocal burst, a short non-verbal vocalization. Borrowing the idea from the recent success of wav2vec 2.0, we evaluated finetuned wav2vec 2.0 models from different datasets to predict the affective state of the speaker from their vocal burst. The finetuned wav2vec 2.0 models are then trained on the vocal burst data. The results show that the finetuned wav2vec 2.0 models, particularly on an affective speech dataset, outperform the baseline model, which is handcrafted acoustic features. However, there is no large gap between the model finetuned on non-affective speech dataset and affective speech dataset.