 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJointly Predicting Emotion, Age, and Country Using Pre-Trained Acoustic Embedding
Paper and Code
Jul 21, 2022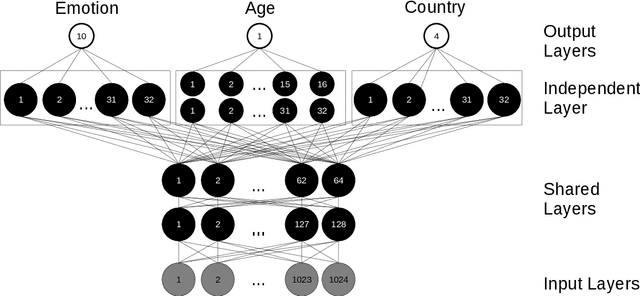
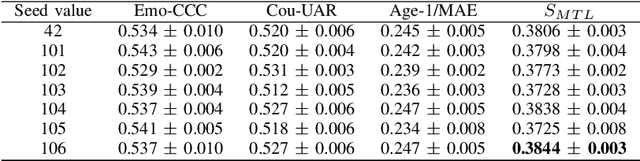
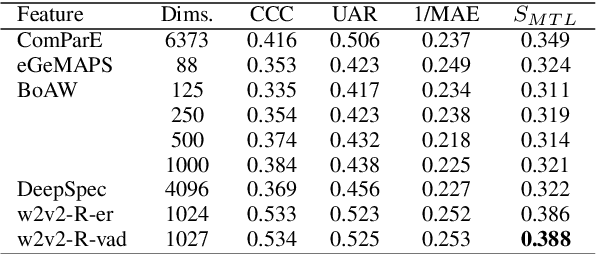
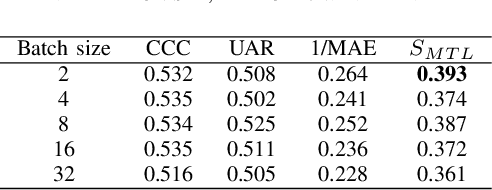
In this paper, we demonstrated the benefit of using pre-trained model to extract acoustic embedding to jointly predict (multitask learning) three tasks: emotion, age, and native country. The pre-trained model was trained with wav2vec 2.0 large robust model on the speech emotion corpus. The emotion and age tasks were regression problems, while country prediction was a classification task. A single harmonic mean from three metrics was used to evaluate the performance of multitask learning. The classifier was a linear network with two independent layers and shared layers, including the output layers. This study explores multitask learning on different acoustic features (including the acoustic embedding extracted from a model trained on an affective speech dataset), seed numbers, batch sizes, and normalizations for predicting paralinguistic information from speech.