 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-dataset COVID-19 Transfer Learning with Cough Detection, Cough Segmentation, and Data Augmentation
Oct 12, 2022
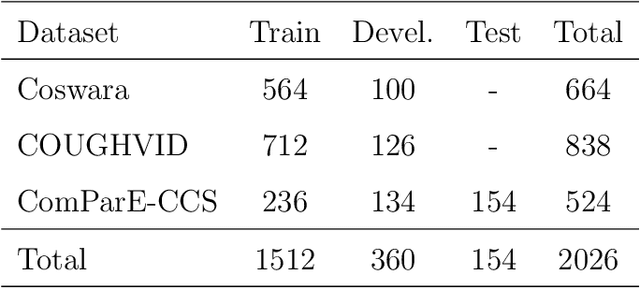
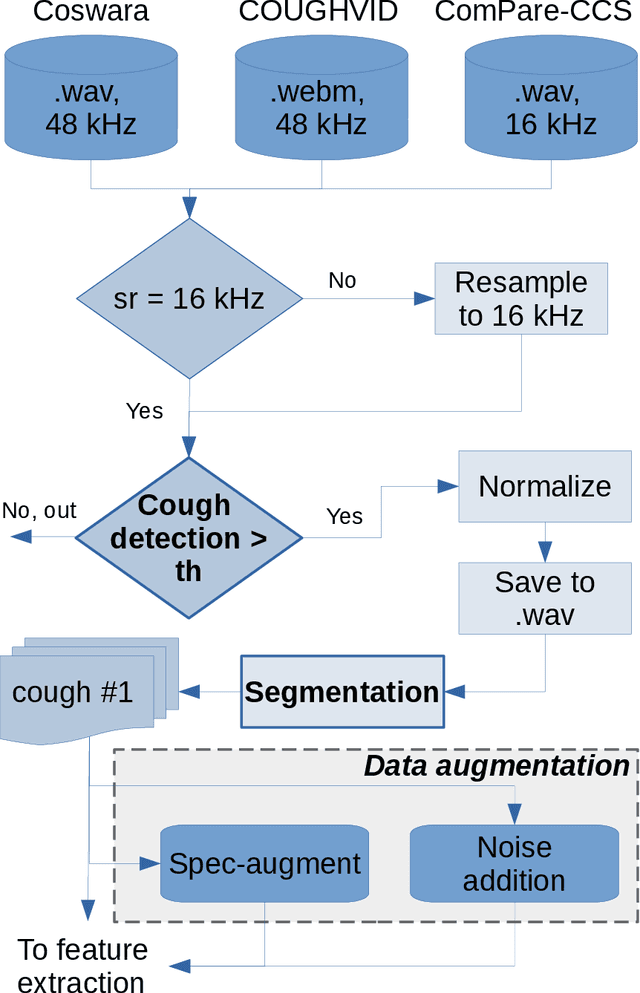
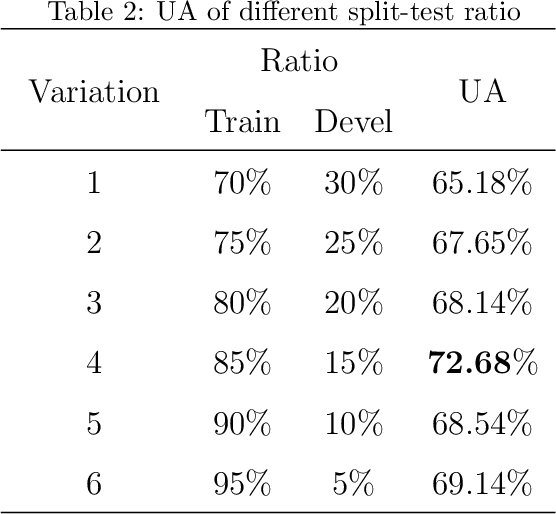
This paper addresses issues on cough-based COVID-19 detection. We propose a cross-dataset transfer learning approach to improve the performance of COVID-19 detection by incorporating cough detection, cough segmentation, and data augmentation. The first aimed at removing non-cough signals and cough signals with low probability. The second aimed at segregating several coughs in a waveform into individual coughs. The third aimed at increasing the number of samples for the deep learning model. These three processing blocks are important as our finding revealed a large margin of improvement relative to the baseline methods without these blocks. An ablation study is conducted to optimize hyperparameters and it was found that alpha mixup is an important factor among others in improving the model performance via this augmentation method. A summary of this study with previous studies on the same evaluation set was given to gain insights into different methods of cough-based COVID-19 detection.
Evaluation of Automatic Single Cough Segmentation
Oct 05, 2022
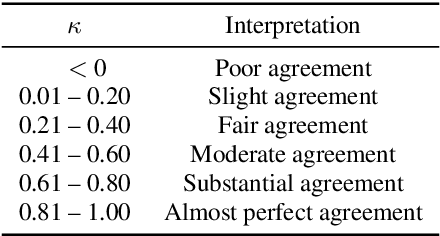
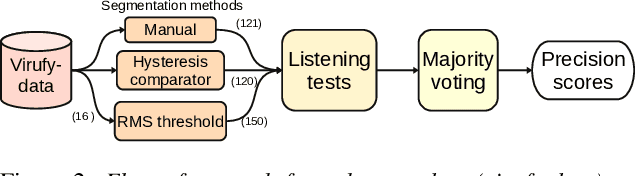
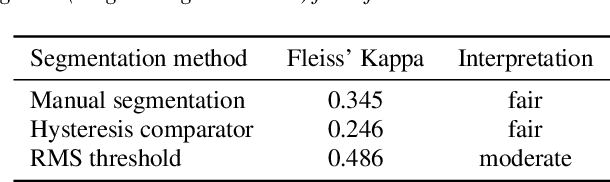
Research on diagnosing diseases based on voice signals currently are rapidly increasing, including cough-related diseases. When training the cough sound signals into deep learning models, it is necessary to have a standard input by segmenting several cough signals into individual cough signals. Previous research has been developed to segment cough signals from non-cough signals. This research evaluates the segmentation methods of several cough signals from a single audio file into several single-cough signals. We evaluate three different methods employing manual segmentation as a baseline and automatic segmentation. The results by two automatic segmentation methods obtained precisions of 73% and 70% compared to 49% by manual segmentation. The agreements of listening tests to count the number of correct single-cough segmentations show fair and moderate correlations for automatic segmentation methods and are comparable with manual segmentation.
Jointly Predicting Emotion, Age, and Country Using Pre-Trained Acoustic Embedding
Jul 21, 2022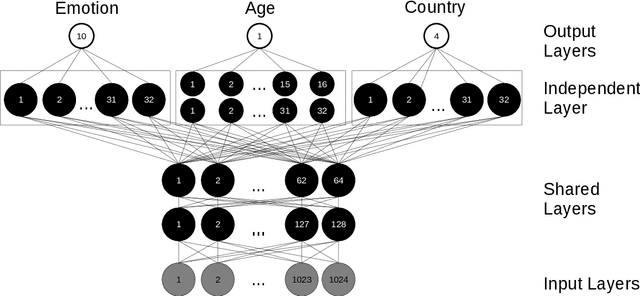
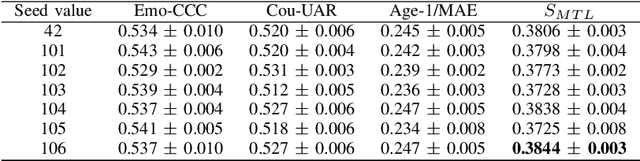
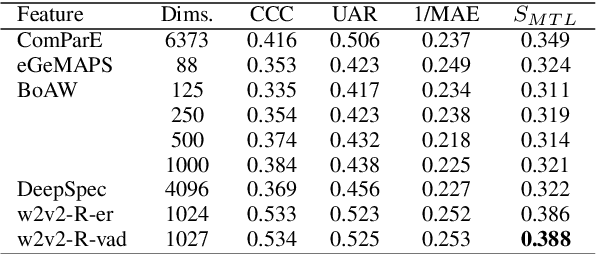
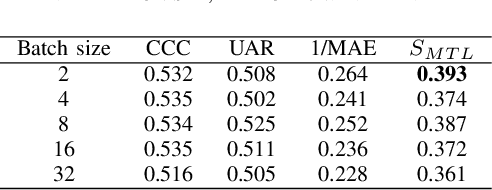
In this paper, we demonstrated the benefit of using pre-trained model to extract acoustic embedding to jointly predict (multitask learning) three tasks: emotion, age, and native country. The pre-trained model was trained with wav2vec 2.0 large robust model on the speech emotion corpus. The emotion and age tasks were regression problems, while country prediction was a classification task. A single harmonic mean from three metrics was used to evaluate the performance of multitask learning. The classifier was a linear network with two independent layers and shared layers, including the output layers. This study explores multitask learning on different acoustic features (including the acoustic embedding extracted from a model trained on an affective speech dataset), seed numbers, batch sizes, and normalizations for predicting paralinguistic information from speech.