 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Automatic Single Cough Segmentation
Paper and Code

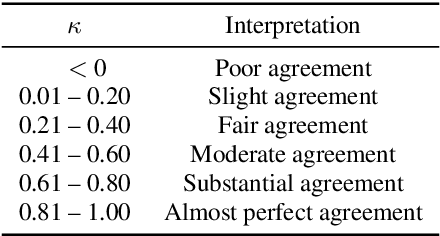
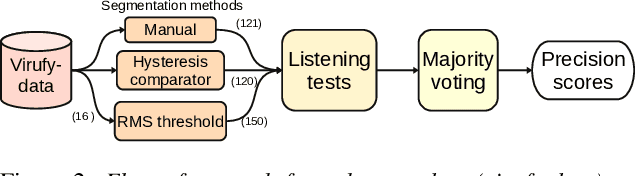
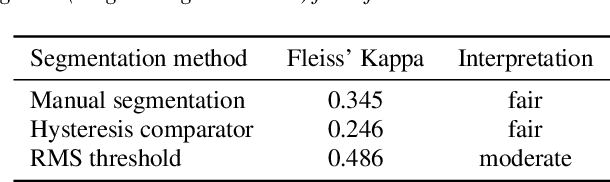
Research on diagnosing diseases based on voice signals currently are rapidly increasing, including cough-related diseases. When training the cough sound signals into deep learning models, it is necessary to have a standard input by segmenting several cough signals into individual cough signals. Previous research has been developed to segment cough signals from non-cough signals. This research evaluates the segmentation methods of several cough signals from a single audio file into several single-cough signals. We evaluate three different methods employing manual segmentation as a baseline and automatic segmentation. The results by two automatic segmentation methods obtained precisions of 73% and 70% compared to 49% by manual segmentation. The agreements of listening tests to count the number of correct single-cough segmentations show fair and moderate correlations for automatic segmentation methods and are comparable with manual segmentation.