 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChunkFormer: Masked Chunking Conformer For Long-Form Speech Transcription
Feb 20, 2025



Deploying ASR models at an industrial scale poses significant challenges in hardware resource management, especially for long-form transcription tasks where audio may last for hours. Large Conformer models, despite their capabilities, are limited to processing only 15 minutes of audio on an 80GB GPU. Furthermore, variable input lengths worsen inefficiencies, as standard batching leads to excessive padding, increasing resource consumption and execution time. To address this, we introduce ChunkFormer, an efficient ASR model that uses chunk-wise processing with relative right context, enabling long audio transcriptions on low-memory GPUs. ChunkFormer handles up to 16 hours of audio on an 80GB GPU, 1.5x longer than the current state-of-the-art FastConformer, while also boosting long-form transcription performance with up to 7.7% absolute reduction on word error rate and maintaining accuracy on shorter tasks compared to Conformer. By eliminating the need for padding in standard batching, ChunkFormer's masked batching technique reduces execution time and memory usage by more than 3x in batch processing, substantially reducing costs for a wide range of ASR systems, particularly regarding GPU resources for models serving in real-world applications.
SegAug: CTC-Aligned Segmented Augmentation For Robust RNN-Transducer Based Speech Recognition
Feb 20, 2025RNN-Transducer (RNN-T) is a widely adopted architecture in speech recognition, integrating acoustic and language modeling in an end-to-end framework. However, the RNN-T predictor tends to over-rely on consecutive word dependencies in training data, leading to high deletion error rates, particularly with less common or out-of-domain phrases. Existing solutions, such as regularization and data augmentation, often compromise other aspects of performance. We propose SegAug, an alignment-based augmentation technique that generates contextually varied audio-text pairs with low sentence-level semantics. This method encourages the model to focus more on acoustic features while diversifying the learned textual patterns of its internal language model, thereby reducing deletion errors and enhancing overall performance. Evaluations on the LibriSpeech and Tedlium-v3 datasets demonstrate a relative WER reduction of up to 12.5% on small-scale and 6.9% on large-scale settings. Notably, most of the improvement stems from reduced deletion errors, with relative reductions of 45.4% and 18.5%, respectively. These results highlight SegAug's effectiveness in improving RNN-T's robustness, offering a promising solution for enhancing speech recognition performance across diverse and challenging scenarios.
Stream-based Active Learning for Anomalous Sound Detection in Machine Condition Monitoring
Aug 10, 2024This paper introduces an active learning (AL) framework for anomalous sound detection (ASD) in machine condition monitoring system. Typically, ASD models are trained solely on normal samples due to the scarcity of anomalous data, leading to decreased accuracy for unseen samples during inference. AL is a promising solution to solve this problem by enabling the model to learn new concepts more effectively with fewer labeled examples, thus reducing manual annotation efforts. However, its effectiveness in ASD remains unexplored. To minimize update costs and time, our proposed method focuses on updating the scoring backend of ASD system without retraining the neural network model. Experimental results on the DCASE 2023 Challenge Task 2 dataset confirm that our AL framework significantly improves ASD performance even with low labeling budgets. Moreover, our proposed sampling strategy outperforms other baselines in terms of the partial area under the receiver operating characteristic score.
Speak Like a Professional: Increasing Speech Intelligibility by Mimicking Professional Announcer Voice with Voice Conversion
Jun 27, 2022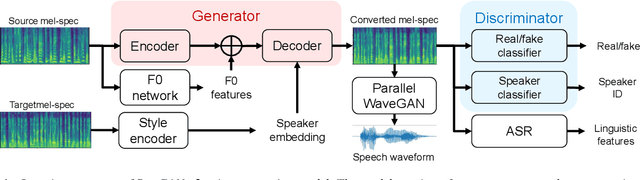



In most of practical scenarios, the announcement system must deliver speech messages in a noisy environment, in which the background noise cannot be cancelled out. The local noise reduces speech intelligibility and increases listening effort of the listener, hence hamper the effectiveness of announcement system. There has been reported that voices of professional announcers are clearer and more comprehensive than that of non-expert speakers in noisy environment. This finding suggests that the speech intelligibility might be related to the speaking style of professional announcer, which can be adapted using voice conversion method. Motivated by this idea, this paper proposes a speech intelligibility enhancement in noisy environment by applying voice conversion method on non-professional voice. We discovered that the professional announcers and non-professional speakers are clusterized into different clusters on the speaker embedding plane. This implies that the speech intelligibility can be controlled as an independent feature of speaker individuality. To examine the advantage of converted voice in noisy environment, we experimented using test words masked in pink noise at different SNR levels. The results of objective and subjective evaluations confirm that the speech intelligibility of converted voice is higher than that of original voice in low SNR conditions.