 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Inspection Based on Switch Sounds of Electric Point Machines
Aug 28, 2025Since 2018, East Japan Railway Company and Hitachi, Ltd. have been working to replace human inspections with IoT-based monitoring. The purpose is Labor-saving required for equipment inspections and provide appropriate preventive maintenance. As an alternative to visual inspection, it has been difficult to substitute electrical characteristic monitoring, and the introduction of new high-performance sensors has been costly. In 2019, we implemented cameras and microphones in an ``NS'' electric point machines to reduce downtime from equipment failures, allowing for remote monitoring of lock-piece conditions. This method for detecting turnout switching errors based on sound information was proposed, and the expected test results were obtained. The proposed method will make it possible to detect equipment failures in real time, thereby reducing the need for visual inspections. This paper presents the results of our technical studies aimed at automating the inspection of electronic point machines using sound, specifically focusing on ``switch sound'' beginning in 2019.
MIMII-Agent: Leveraging LLMs with Function Calling for Relative Evaluation of Anomalous Sound Detection
Jul 28, 2025This paper proposes a method for generating machine-type-specific anomalies to evaluate the relative performance of unsupervised anomalous sound detection (UASD) systems across different machine types, even in the absence of real anomaly sound data. Conventional keyword-based data augmentation methods often produce unrealistic sounds due to their reliance on manually defined labels, limiting scalability as machine types and anomaly patterns diversify. Advanced audio generative models, such as MIMII-Gen, show promise but typically depend on anomalous training data, making them less effective when diverse anomalous examples are unavailable. To address these limitations, we propose a novel synthesis approach leveraging large language models (LLMs) to interpret textual descriptions of faults and automatically select audio transformation functions, converting normal machine sounds into diverse and plausible anomalous sounds. We validate this approach by evaluating a UASD system trained only on normal sounds from five machine types, using both real and synthetic anomaly data. Experimental results reveal consistent trends in relative detection difficulty across machine types between synthetic and real anomalies. This finding supports our hypothesis and highlights the effectiveness of the proposed LLM-based synthesis approach for relative evaluation of UASD systems.
Retrieving Time-Series Differences Using Natural Language Queries
Mar 27, 2025Effectively searching time-series data is essential for system analysis; however, traditional methods often require domain expertise to define search criteria. Recent advancements have enabled natural language-based search, but these methods struggle to handle differences between time-series data. To address this limitation, we propose a natural language query-based approach for retrieving pairs of time-series data based on differences specified in the query. Specifically, we define six key characteristics of differences, construct a corresponding dataset, and develop a contrastive learning-based model to align differences between time-series data with query texts. Experimental results demonstrate that our model achieves an overall mAP score of 0.994 in retrieving time-series pairs.
CLaSP: Learning Concepts for Time-Series Signals from Natural Language Supervision
Nov 13, 2024This paper proposes a foundation model called "CLaSP" that can search time series signals using natural language that describes the characteristics of the signals as queries. Previous efforts to represent time series signal data in natural language have had challenges in designing a conventional class of time series signal characteristics, formulating their quantification, and creating a dictionary of synonyms. To overcome these limitations, the proposed method introduces a neural network based on contrastive learning. This network is first trained using the datasets TRUCE and SUSHI, which consist of time series signals and their corresponding natural language descriptions. Previous studies have proposed vocabularies that data analysts use to describe signal characteristics, and SUSHI was designed to cover these terms. We believe that a neural network trained on these datasets will enable data analysts to search using natural language vocabulary. Furthermore, our method does not require a dictionary of predefined synonyms, and it leverages common sense knowledge embedded in a large-scale language model (LLM). Experimental results demonstrate that CLaSP enables natural language search of time series signal data and can accurately learn the points at which signal data changes.
Timbre Difference Capturing in Anomalous Sound Detection
Oct 29, 2024



This paper proposes a framework of explaining anomalous machine sounds in the context of anomalous sound detection~(ASD). While ASD has been extensively explored, identifying how anomalous sounds differ from normal sounds is also beneficial for machine condition monitoring. However, existing sound difference captioning methods require anomalous sounds for training, which is impractical in typical machine condition monitoring settings where such sounds are unavailable. To solve this issue, we propose a new strategy for explaining anomalous differences that does not require anomalous sounds for training. Specifically, we introduce a framework that explains differences in predefined timbre attributes instead of using free-form text captions. Objective metrics of timbre attributes can be computed using timbral models developed through psycho-acoustical research, enabling the estimation of how and what timbre attributes have changed from normal sounds without training machine learning models. Additionally, to accurately determine timbre differences regardless of variations in normal training data, we developed a method that jointly conducts anomalous sound detection and timbre difference estimation based on a k-nearest neighbors method in an audio embedding space. Evaluation using the MIMII DG dataset demonstrated the effectiveness of the proposed method.
Can We Estimate Purchase Intention Based on Zero-shot Speech Emotion Recognition?
Oct 12, 2024This paper proposes a zero-shot speech emotion recognition (SER) method that estimates emotions not previously defined in the SER model training. Conventional methods are limited to recognizing emotions defined by a single word. Moreover, we have the motivation to recognize unknown bipolar emotions such as ``I want to buy - I do not want to buy.'' In order to allow the model to define classes using sentences freely and to estimate unknown bipolar emotions, our proposed method expands upon the contrastive language-audio pre-training (CLAP) framework by introducing multi-class and multi-task settings. We also focus on purchase intention as a bipolar emotion and investigate the model's performance to zero-shot estimate it. This study is the first attempt to estimate purchase intention from speech directly. Experiments confirm that the results of zero-shot estimation by the proposed method are at the same level as those of the model trained by supervised learning.
MIMII-Gen: Generative Modeling Approach for Simulated Evaluation of Anomalous Sound Detection System
Sep 27, 2024



Insufficient recordings and the scarcity of anomalies present significant challenges in developing and validating robust anomaly detection systems for machine sounds. To address these limitations, we propose a novel approach for generating diverse anomalies in machine sound using a latent diffusion-based model that integrates an encoder-decoder framework. Our method utilizes the Flan-T5 model to encode captions derived from audio file metadata, enabling conditional generation through a carefully designed U-Net architecture. This approach aids our model in generating audio signals within the EnCodec latent space, ensuring high contextual relevance and quality. We objectively evaluated the quality of our generated sounds using the Fr\'echet Audio Distance (FAD) score and other metrics, demonstrating that our approach surpasses existing models in generating reliable machine audio that closely resembles actual abnormal conditions. The evaluation of the anomaly detection system using our generated data revealed a strong correlation, with the area under the curve (AUC) score differing by 4.8\% from the original, validating the effectiveness of our generated data. These results demonstrate the potential of our approach to enhance the evaluation and robustness of anomaly detection systems across varied and previously unseen conditions. Audio samples can be found at \url{https://hpworkhub.github.io/MIMII-Gen.github.io/}.
Domain-Independent Automatic Generation of Descriptive Texts for Time-Series Data
Sep 25, 2024



Due to scarcity of time-series data annotated with descriptive texts, training a model to generate descriptive texts for time-series data is challenging. In this study, we propose a method to systematically generate domain-independent descriptive texts from time-series data. We identify two distinct approaches for creating pairs of time-series data and descriptive texts: the forward approach and the backward approach. By implementing the novel backward approach, we create the Temporal Automated Captions for Observations (TACO) dataset. Experimental results demonstrate that a contrastive learning based model trained using the TACO dataset is capable of generating descriptive texts for time-series data in novel domains.
Stream-based Active Learning for Anomalous Sound Detection in Machine Condition Monitoring
Aug 10, 2024This paper introduces an active learning (AL) framework for anomalous sound detection (ASD) in machine condition monitoring system. Typically, ASD models are trained solely on normal samples due to the scarcity of anomalous data, leading to decreased accuracy for unseen samples during inference. AL is a promising solution to solve this problem by enabling the model to learn new concepts more effectively with fewer labeled examples, thus reducing manual annotation efforts. However, its effectiveness in ASD remains unexplored. To minimize update costs and time, our proposed method focuses on updating the scoring backend of ASD system without retraining the neural network model. Experimental results on the DCASE 2023 Challenge Task 2 dataset confirm that our AL framework significantly improves ASD performance even with low labeling budgets. Moreover, our proposed sampling strategy outperforms other baselines in terms of the partial area under the receiver operating characteristic score.
Description and Discussion on DCASE 2024 Challenge Task 2: First-Shot Unsupervised Anomalous Sound Detection for Machine Condition Monitoring
Jun 11, 2024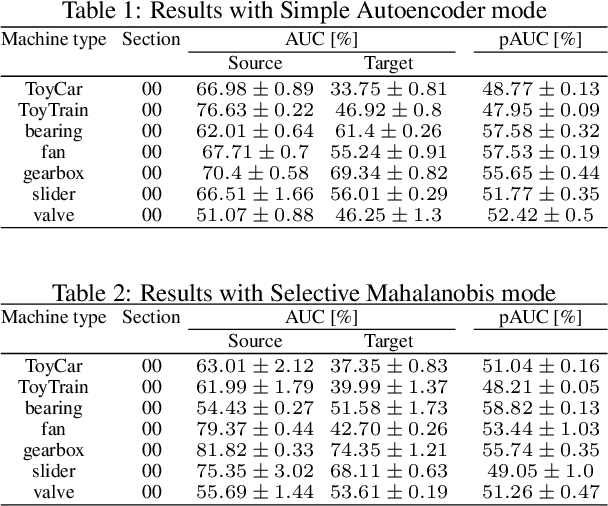
We present the task description of the Detection and Classification of Acoustic Scenes and Events (DCASE) 2024 Challenge Task 2: First-shot unsupervised anomalous sound detection (ASD) for machine condition monitoring. Continuing from last year's DCASE 2023 Challenge Task 2, we organize the task as a first-shot problem under domain generalization required settings. The main goal of the first-shot problem is to enable rapid deployment of ASD systems for new kinds of machines without the need for machine-specific hyperparameter tunings. This problem setting was realized by (1) giving only one section for each machine type and (2) having completely different machine types for the development and evaluation datasets. For the DCASE 2024 Challenge Task 2, data of completely new machine types were newly collected and provided as the evaluation dataset. In addition, attribute information such as the machine operation conditions were concealed for several machine types to mimic situations where such information are unavailable. We will add challenge results and analysis of the submissions after the challenge submission deadline.