 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-based Generative Error Correction for Rare Words with Synthetic Data and Phonetic Context
May 23, 2025Generative error correction (GER) with large language models (LLMs) has emerged as an effective post-processing approach to improve automatic speech recognition (ASR) performance. However, it often struggles with rare or domain-specific words due to limited training data. Furthermore, existing LLM-based GER approaches primarily rely on textual information, neglecting phonetic cues, which leads to over-correction. To address these issues, we propose a novel LLM-based GER approach that targets rare words and incorporates phonetic information. First, we generate synthetic data to contain rare words for fine-tuning the GER model. Second, we integrate ASR's N-best hypotheses along with phonetic context to mitigate over-correction. Experimental results show that our method not only improves the correction of rare words but also reduces the WER and CER across both English and Japanese datasets.
End-to-End Integration of Speech Emotion Recognition with Voice Activity Detection using Self-Supervised Learning Features
Oct 17, 2024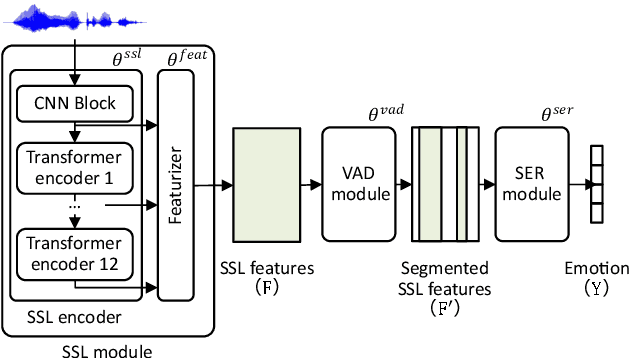
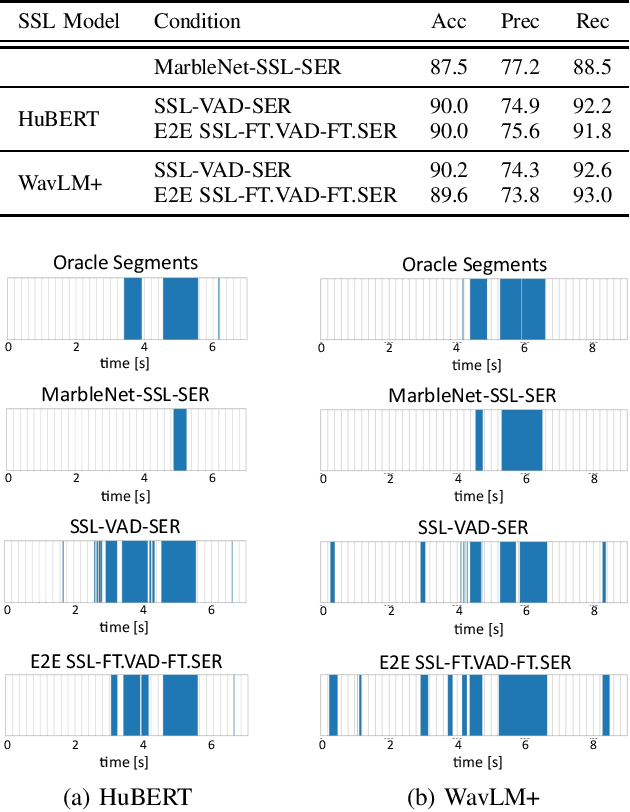
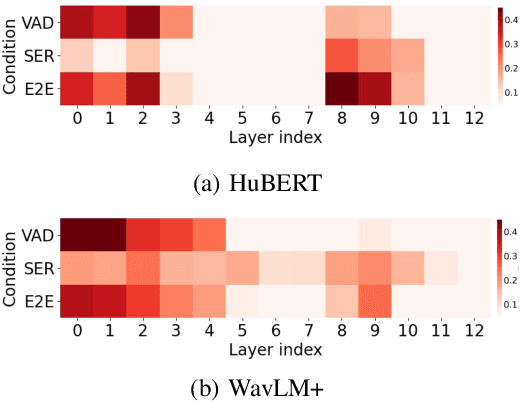
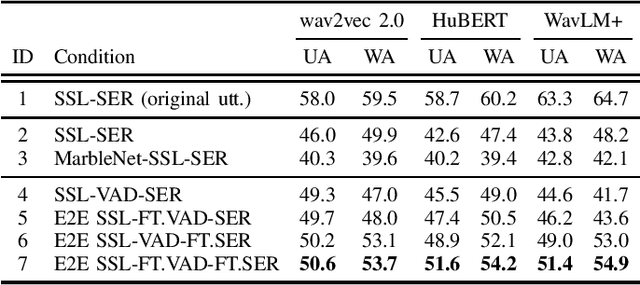
Speech Emotion Recognition (SER) often operates on speech segments detected by a Voice Activity Detection (VAD) model. However, VAD models may output flawed speech segments, especially in noisy environments, resulting in degraded performance of subsequent SER models. To address this issue, we propose an end-to-end (E2E) method that integrates VAD and SER using Self-Supervised Learning (SSL) features. The VAD module first receives the SSL features as input, and the segmented SSL features are then fed into the SER module. Both the VAD and SER modules are jointly trained to optimize SER performance. Experimental results on the IEMOCAP dataset demonstrate that our proposed method improves SER performance. Furthermore, to investigate the effect of our proposed method on the VAD and SSL modules, we present an analysis of the VAD outputs and the weights of each layer of the SSL encoder.
Can We Estimate Purchase Intention Based on Zero-shot Speech Emotion Recognition?
Oct 12, 2024This paper proposes a zero-shot speech emotion recognition (SER) method that estimates emotions not previously defined in the SER model training. Conventional methods are limited to recognizing emotions defined by a single word. Moreover, we have the motivation to recognize unknown bipolar emotions such as ``I want to buy - I do not want to buy.'' In order to allow the model to define classes using sentences freely and to estimate unknown bipolar emotions, our proposed method expands upon the contrastive language-audio pre-training (CLAP) framework by introducing multi-class and multi-task settings. We also focus on purchase intention as a bipolar emotion and investigate the model's performance to zero-shot estimate it. This study is the first attempt to estimate purchase intention from speech directly. Experiments confirm that the results of zero-shot estimation by the proposed method are at the same level as those of the model trained by supervised learning.
Improving the Naturalness of Simulated Conversations for End-to-End Neural Diarization
Apr 24, 2022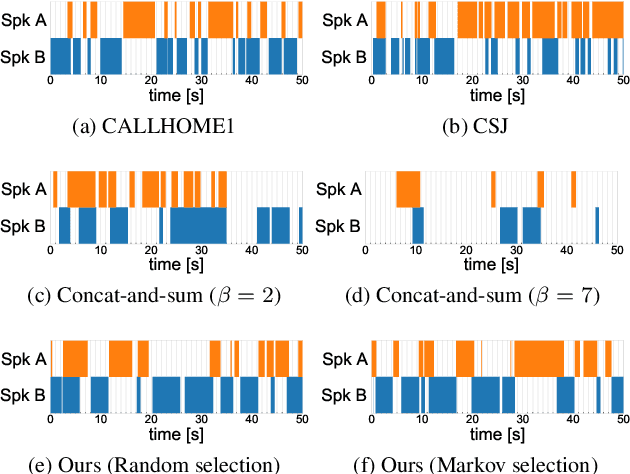
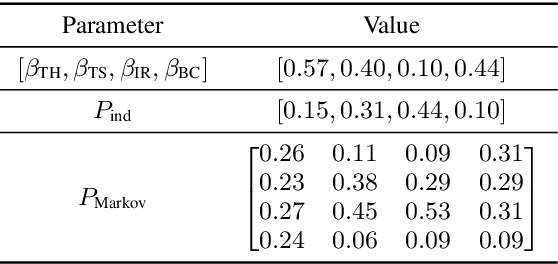
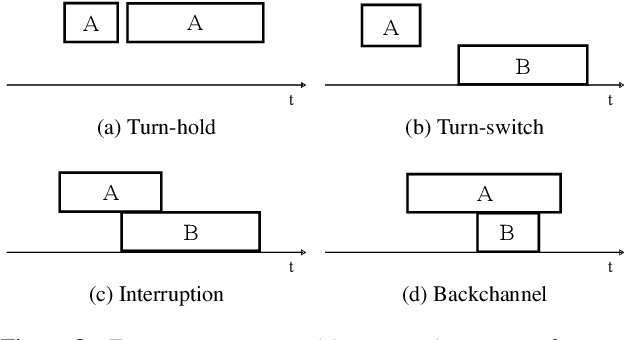
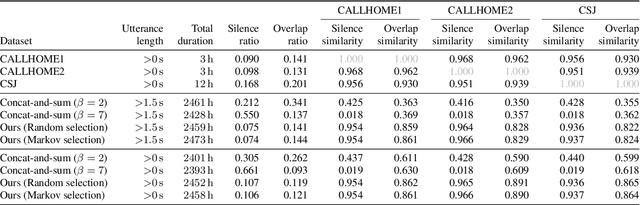
This paper investigates a method for simulating natural conversation in the model training of end-to-end neural diarization (EEND). Due to the lack of any annotated real conversational dataset, EEND is usually pretrained on a large-scale simulated conversational dataset first and then adapted to the target real dataset. Simulated datasets play an essential role in the training of EEND, but as yet there has been insufficient investigation into an optimal simulation method. We thus propose a method to simulate natural conversational speech. In contrast to conventional methods, which simply combine the speech of multiple speakers, our method takes turn-taking into account. We define four types of speaker transition and sequentially arrange them to simulate natural conversations. The dataset simulated using our method was found to be statistically similar to the real dataset in terms of the silence and overlap ratios. The experimental results on two-speaker diarization using the CALLHOME and CSJ datasets showed that the simulated dataset contributes to improving the performance of EEND.