 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Naturalness of Simulated Conversations for End-to-End Neural Diarization
Apr 24, 2022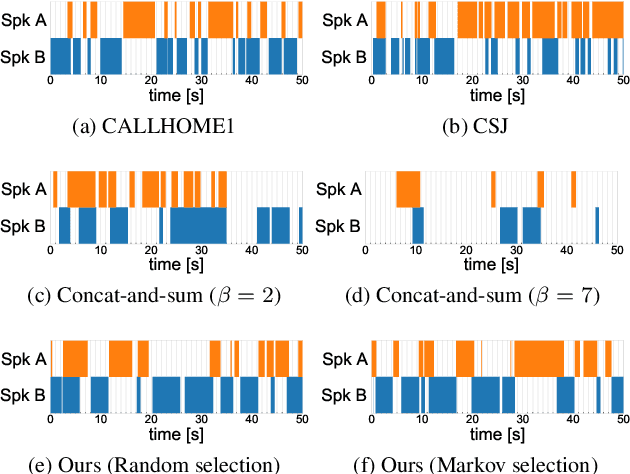
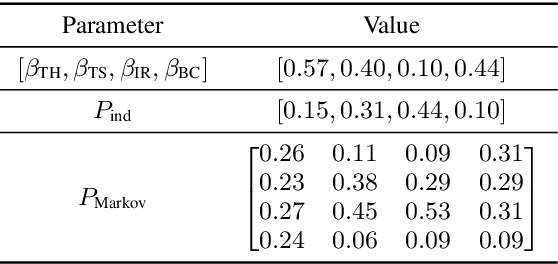
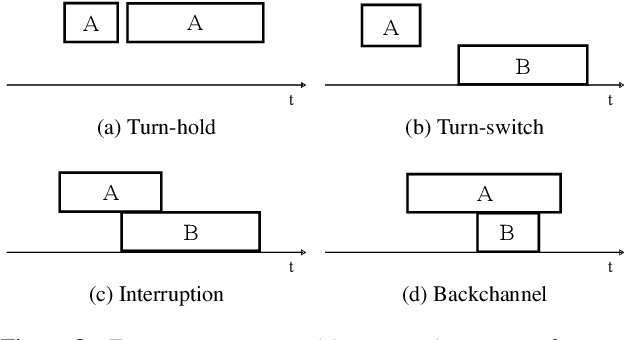
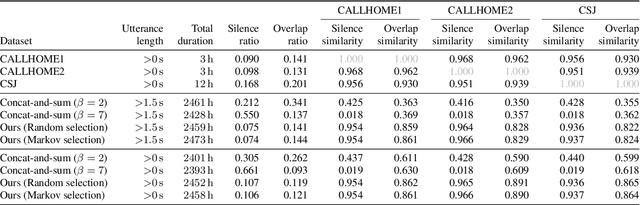
This paper investigates a method for simulating natural conversation in the model training of end-to-end neural diarization (EEND). Due to the lack of any annotated real conversational dataset, EEND is usually pretrained on a large-scale simulated conversational dataset first and then adapted to the target real dataset. Simulated datasets play an essential role in the training of EEND, but as yet there has been insufficient investigation into an optimal simulation method. We thus propose a method to simulate natural conversational speech. In contrast to conventional methods, which simply combine the speech of multiple speakers, our method takes turn-taking into account. We define four types of speaker transition and sequentially arrange them to simulate natural conversations. The dataset simulated using our method was found to be statistically similar to the real dataset in terms of the silence and overlap ratios. The experimental results on two-speaker diarization using the CALLHOME and CSJ datasets showed that the simulated dataset contributes to improving the performance of EEND.
Emotional Speech Synthesis for Companion Robot to Imitate Professional Caregiver Speech
Sep 27, 2021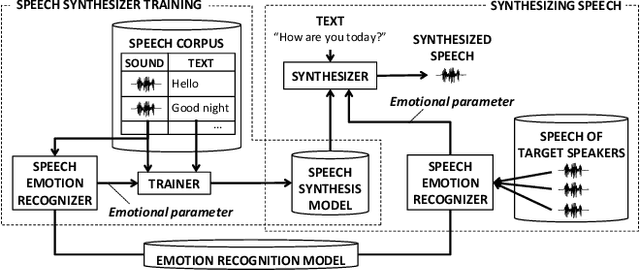
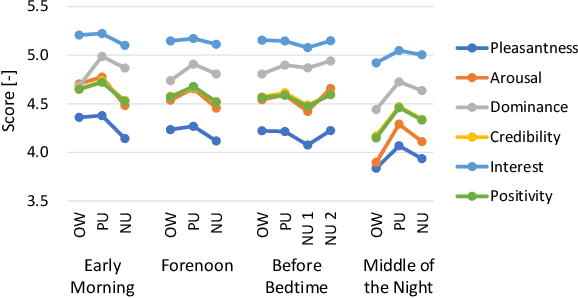


When people try to influence others to do something, they subconsciously adjust their speech to include appropriate emotional information. In order for a robot to influence people in the same way, the robot should be able to imitate the range of human emotions when speaking. To achieve this, we propose a speech synthesis method for imitating the emotional states in human speech. In contrast to previous methods, the advantage of our method is that it requires less manual effort to adjust the emotion of the synthesized speech. Our synthesizer receives an emotion vector to characterize the emotion of synthesized speech. The vector is automatically obtained from human utterances by using a speech emotion recognizer. We evaluated our method in a scenario when a robot tries to regulate an elderly person's circadian rhythm by speaking to the person using appropriate emotional states. For the target speech to imitate, we collected utterances from professional caregivers when they speak to elderly people at different times of the day. Then we conducted a subjective evaluation where the elderly participants listened to the speech samples generated by our method. The results showed that listening to the samples made the participants feel more active in the early morning and calmer in the middle of the night. This suggests that the robot may be able to adjust the participants' circadian rhythm and that the robot can potentially exert influence similarly to a person.
Addressing Ambiguity of Emotion Labels Through Meta-Learning
Nov 07, 2019

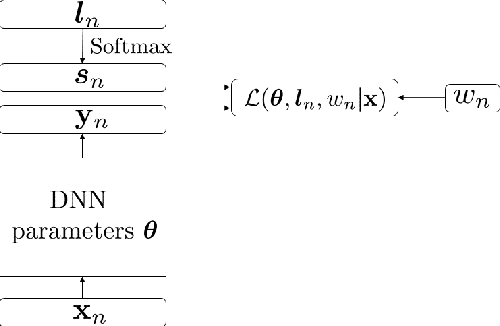

Emotion labels in emotion recognition corpora are highly noisy and ambiguous, due to the annotators' subjective perception of emotions. Such ambiguity may introduce errors in automatic classification and affect the overall performance. We therefore propose a dynamic label correction and sample contribution weight estimation model. Our model is based on a standard BLSTM model with attention with two extra parameters. The first learns a new corrected label distribution, and is aimed to fix the inaccurate labels from the dataset. The other instead estimates the contribution of each sample to the training process, and is aimed to ignore the ambiguous and noisy samples while giving higher weight to the clear ones. We train our model through an alternating optimization method, where in the first epoch we update the neural network parameters, and in the second we keep them fixed to update the label correction and sample importance parameters. When training and evaluating our model on the IEMOCAP dataset, we obtained a weighted accuracy (WA) and unweighted accuracy (UA) of respectively 65.9% and 61.4%. This yielded an absolute improvement of 2.5%, 2.7% respectively compared to a BLSTM with attention baseline, trained on the corpus gold labels.