 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing Ambiguity of Emotion Labels Through Meta-Learning
Nov 07, 2019

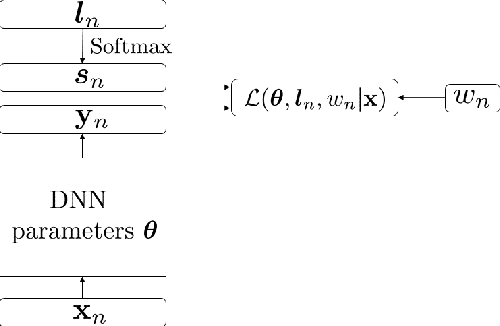

Emotion labels in emotion recognition corpora are highly noisy and ambiguous, due to the annotators' subjective perception of emotions. Such ambiguity may introduce errors in automatic classification and affect the overall performance. We therefore propose a dynamic label correction and sample contribution weight estimation model. Our model is based on a standard BLSTM model with attention with two extra parameters. The first learns a new corrected label distribution, and is aimed to fix the inaccurate labels from the dataset. The other instead estimates the contribution of each sample to the training process, and is aimed to ignore the ambiguous and noisy samples while giving higher weight to the clear ones. We train our model through an alternating optimization method, where in the first epoch we update the neural network parameters, and in the second we keep them fixed to update the label correction and sample importance parameters. When training and evaluating our model on the IEMOCAP dataset, we obtained a weighted accuracy (WA) and unweighted accuracy (UA) of respectively 65.9% and 61.4%. This yielded an absolute improvement of 2.5%, 2.7% respectively compared to a BLSTM with attention baseline, trained on the corpus gold labels.
Towards Universal End-to-End Affect Recognition from Multilingual Speech by ConvNets
Jan 19, 2019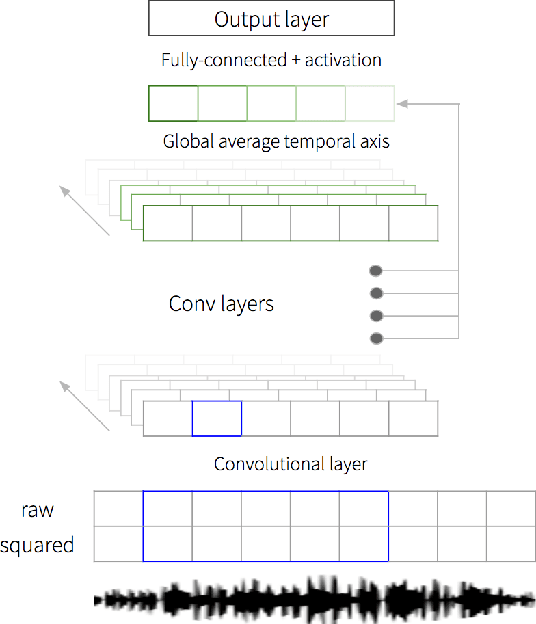
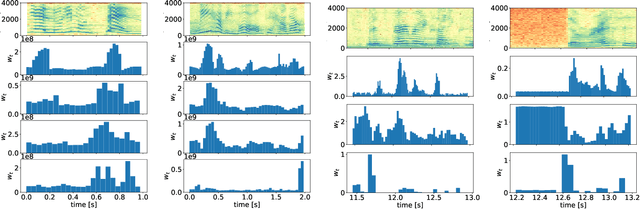
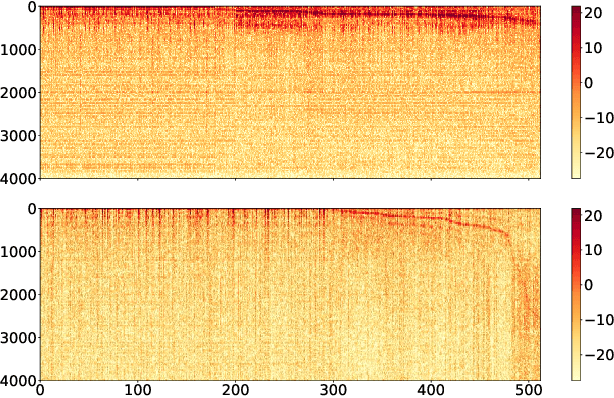
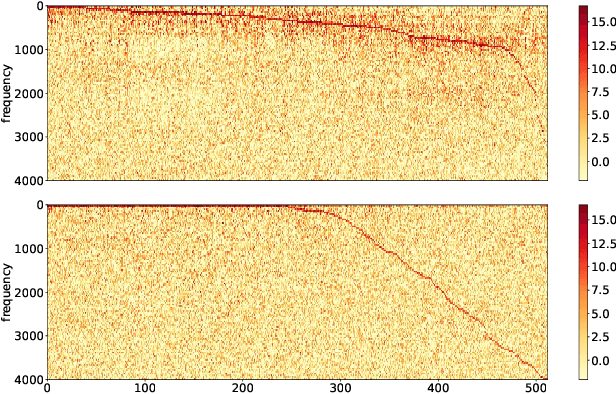
We propose an end-to-end affect recognition approach using a Convolutional Neural Network (CNN) that handles multiple languages, with applications to emotion and personality recognition from speech. We lay the foundation of a universal model that is trained on multiple languages at once. As affect is shared across all languages, we are able to leverage shared information between languages and improve the overall performance for each one. We obtained an average improvement of 12.8% on emotion and 10.1% on personality when compared with the same model trained on each language only. It is end-to-end because we directly take narrow-band raw waveforms as input. This allows us to accept as input audio recorded from any source and to avoid the overhead and information loss of feature extraction. It outperforms a similar CNN using spectrograms as input by 12.8% for emotion and 6.3% for personality, based on F-scores. Analysis of the network parameters and layers activation shows that the network learns and extracts significant features in the first layer, in particular pitch, energy and contour variations. Subsequent convolutional layers instead capture language-specific representations through the analysis of supra-segmental features. Our model represents an important step for the development of a fully universal affect recognizer, able to recognize additional descriptors, such as stress, and for the future implementation into affective interactive systems.
GlobalTrait: Personality Alignment of Multilingual Word Embeddings
Nov 01, 2018
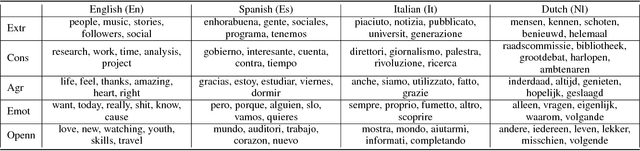
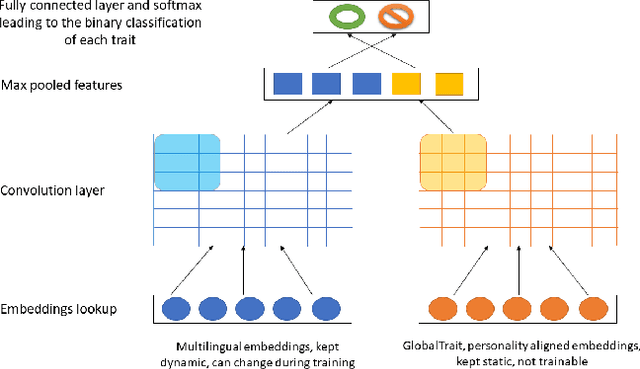

We propose a multilingual model to recognize Big Five Personality traits from text data in four different languages: English, Spanish, Dutch and Italian. Our analysis shows that words having a similar semantic meaning in different languages do not necessarily correspond to the same personality traits. Therefore, we propose a personality alignment method, GlobalTrait, which has a mapping for each trait from the source language to the target language (English), such that words that correlate positively to each trait are close together in the multilingual vector space. Using these aligned embeddings for training, we can transfer personality related training features from high-resource languages such as English to other low-resource languages, and get better multilingual results, when compared to using simple monolingual and unaligned multilingual embeddings. We achieve an average F-score increase (across all three languages except English) from 65 to 73.4 (+8.4), when comparing our monolingual model to multilingual using CNN with personality aligned embeddings. We also show relatively good performance in the regression tasks, and better classification results when evaluating our model on a separate Chinese dataset.
Investigating Audio, Visual, and Text Fusion Methods for End-to-End Automatic Personality Prediction
May 16, 2018
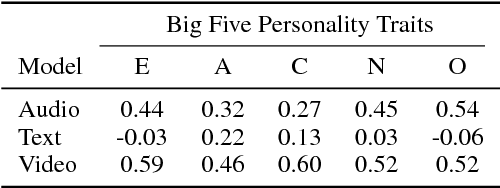
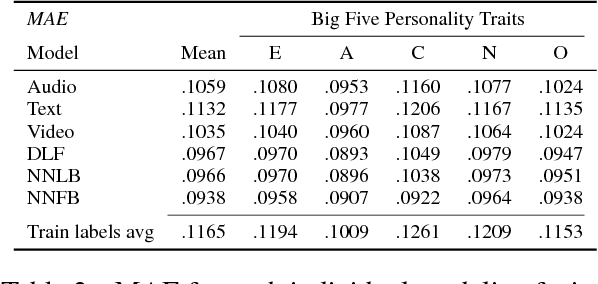

We propose a tri-modal architecture to predict Big Five personality trait scores from video clips with different channels for audio, text, and video data. For each channel, stacked Convolutional Neural Networks are employed. The channels are fused both on decision-level and by concatenating their respective fully connected layers. It is shown that a multimodal fusion approach outperforms each single modality channel, with an improvement of 9.4\% over the best individual modality (video). Full backpropagation is also shown to be better than a linear combination of modalities, meaning complex interactions between modalities can be leveraged to build better models. Furthermore, we can see the prediction relevance of each modality for each trait. The described model can be used to increase the emotional intelligence of virtual agents.
Towards Empathetic Human-Robot Interactions
May 13, 2016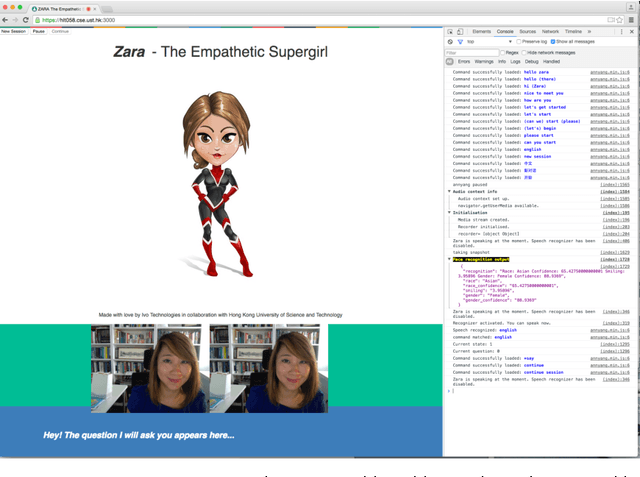
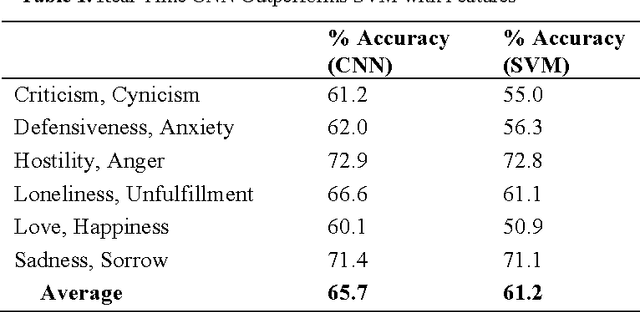


Since the late 1990s when speech companies began providing their customer-service software in the market, people have gotten used to speaking to machines. As people interact more often with voice and gesture controlled machines, they expect the machines to recognize different emotions, and understand other high level communication features such as humor, sarcasm and intention. In order to make such communication possible, the machines need an empathy module in them which can extract emotions from human speech and behavior and can decide the correct response of the robot. Although research on empathetic robots is still in the early stage, we described our approach using signal processing techniques, sentiment analysis and machine learning algorithms to make robots that can "understand" human emotion. We propose Zara the Supergirl as a prototype system of empathetic robots. It is a software based virtual android, with an animated cartoon character to present itself on the screen. She will get "smarter" and more empathetic through its deep learning algorithms, and by gathering more data and learning from it. In this paper, we present our work so far in the areas of deep learning of emotion and sentiment recognition, as well as humor recognition. We hope to explore the future direction of android development and how it can help improve people's lives.