 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational inference for neural network matrix factorization and its application to stochastic blockmodeling
May 11, 2019

We consider the probabilistic analogue to neural network matrix factorization (Dziugaite & Roy, 2015), which we construct with Bayesian neural networks and fit with variational inference. We find that a linear model fit with variational inference can attain equivalent predictive performance to the neural network variants on the Movielens data sets. We discuss the implications of this result, which include some suggestions on the pros and cons of using the neural network construction, as well as the variational approach to inference. A probabilistic approach is required in some cases, however, such as when considering the important class of stochastic blockmodels. We describe a variational inference algorithm for a neural network matrix factorization model with nonparametric block structure and evaluate it on the NIPS co-authorship data set.
Towards Universal End-to-End Affect Recognition from Multilingual Speech by ConvNets
Jan 19, 2019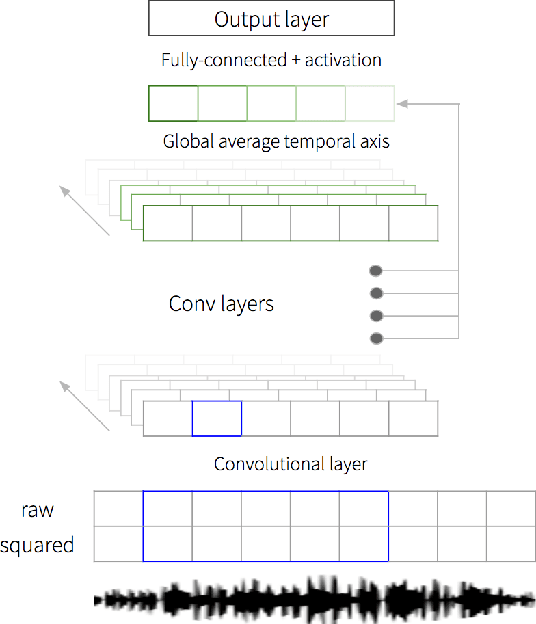
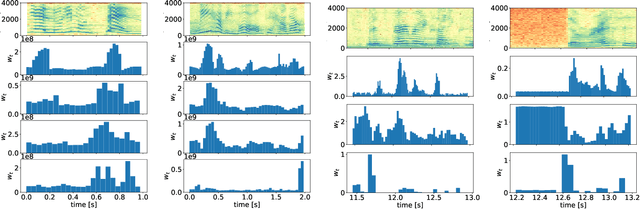
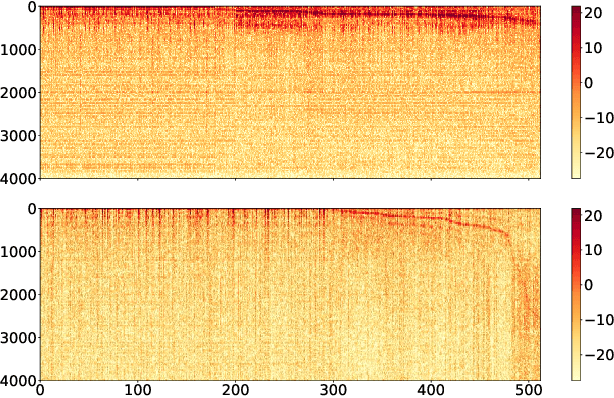
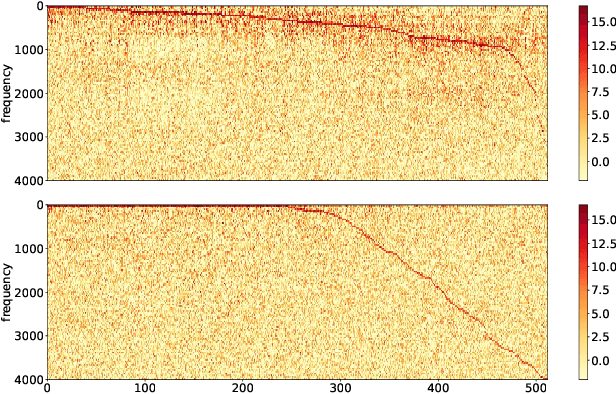
We propose an end-to-end affect recognition approach using a Convolutional Neural Network (CNN) that handles multiple languages, with applications to emotion and personality recognition from speech. We lay the foundation of a universal model that is trained on multiple languages at once. As affect is shared across all languages, we are able to leverage shared information between languages and improve the overall performance for each one. We obtained an average improvement of 12.8% on emotion and 10.1% on personality when compared with the same model trained on each language only. It is end-to-end because we directly take narrow-band raw waveforms as input. This allows us to accept as input audio recorded from any source and to avoid the overhead and information loss of feature extraction. It outperforms a similar CNN using spectrograms as input by 12.8% for emotion and 6.3% for personality, based on F-scores. Analysis of the network parameters and layers activation shows that the network learns and extracts significant features in the first layer, in particular pitch, energy and contour variations. Subsequent convolutional layers instead capture language-specific representations through the analysis of supra-segmental features. Our model represents an important step for the development of a fully universal affect recognizer, able to recognize additional descriptors, such as stress, and for the future implementation into affective interactive systems.
Investigating Audio, Visual, and Text Fusion Methods for End-to-End Automatic Personality Prediction
May 16, 2018
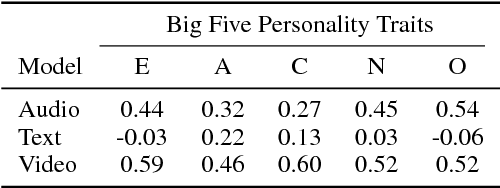
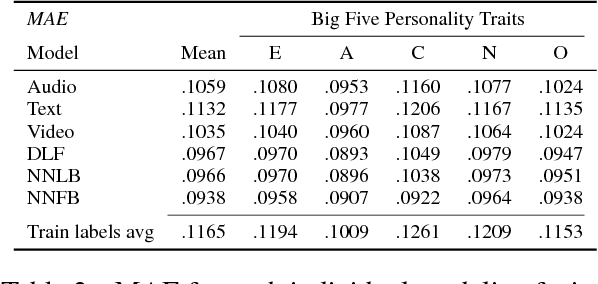

We propose a tri-modal architecture to predict Big Five personality trait scores from video clips with different channels for audio, text, and video data. For each channel, stacked Convolutional Neural Networks are employed. The channels are fused both on decision-level and by concatenating their respective fully connected layers. It is shown that a multimodal fusion approach outperforms each single modality channel, with an improvement of 9.4\% over the best individual modality (video). Full backpropagation is also shown to be better than a linear combination of modalities, meaning complex interactions between modalities can be leveraged to build better models. Furthermore, we can see the prediction relevance of each modality for each trait. The described model can be used to increase the emotional intelligence of virtual agents.