 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeSyCoCo: A Neuro-Symbolic Concept Composer for Compositional Generalization
Dec 20, 2024



Compositional generalization is crucial for artificial intelligence agents to solve complex vision-language reasoning tasks. Neuro-symbolic approaches have demonstrated promise in capturing compositional structures, but they face critical challenges: (a) reliance on predefined predicates for symbolic representations that limit adaptability, (b) difficulty in extracting predicates from raw data, and (c) using non-differentiable operations for combining primitive concepts. To address these issues, we propose NeSyCoCo, a neuro-symbolic framework that leverages large language models (LLMs) to generate symbolic representations and map them to differentiable neural computations. NeSyCoCo introduces three innovations: (a) augmenting natural language inputs with dependency structures to enhance the alignment with symbolic representations, (b) employing distributed word representations to link diverse, linguistically motivated logical predicates to neural modules, and (c) using the soft composition of normalized predicate scores to align symbolic and differentiable reasoning. Our framework achieves state-of-the-art results on the ReaSCAN and CLEVR-CoGenT compositional generalization benchmarks and demonstrates robust performance with novel concepts in the CLEVR-SYN benchmark.
Disentangling Knowledge-based and Visual Reasoning by Question Decomposition in KB-VQA
Jun 27, 2024We study the Knowledge-Based visual question-answering problem, for which given a question, the models need to ground it into the visual modality to find the answer. Although many recent works use question-dependent captioners to verbalize the given image and use Large Language Models to solve the VQA problem, the research results show they are not reasonably performing for multi-hop questions. Our study shows that replacing a complex question with several simpler questions helps to extract more relevant information from the image and provide a stronger comprehension of it. Moreover, we analyze the decomposed questions to find out the modality of the information that is required to answer them and use a captioner for the visual questions and LLMs as a general knowledge source for the non-visual KB-based questions. Our results demonstrate the positive impact of using simple questions before retrieving visual or non-visual information. We have provided results and analysis on three well-known VQA datasets including OKVQA, A-OKVQA, and KRVQA, and achieved up to 2% improvement in accuracy.
Find The Gap: Knowledge Base Reasoning For Visual Question Answering
Apr 16, 2024We analyze knowledge-based visual question answering, for which given a question, the models need to ground it into the visual modality and retrieve the relevant knowledge from a given large knowledge base (KB) to be able to answer. Our analysis has two folds, one based on designing neural architectures and training them from scratch, and another based on large pre-trained language models (LLMs). Our research questions are: 1) Can we effectively augment models by explicit supervised retrieval of the relevant KB information to solve the KB-VQA problem? 2) How do task-specific and LLM-based models perform in the integration of visual and external knowledge, and multi-hop reasoning over both sources of information? 3) Is the implicit knowledge of LLMs sufficient for KB-VQA and to what extent it can replace the explicit KB? Our results demonstrate the positive impact of empowering task-specific and LLM models with supervised external and visual knowledge retrieval models. Our findings show that though LLMs are stronger in 1-hop reasoning, they suffer in 2-hop reasoning in comparison with our fine-tuned NN model even if the relevant information from both modalities is available to the model. Moreover, we observed that LLM models outperform the NN model for KB-related questions which confirms the effectiveness of implicit knowledge in LLMs however, they do not alleviate the need for external KB.
AiSocrates: Towards Answering Ethical Quandary Questions
May 24, 2022
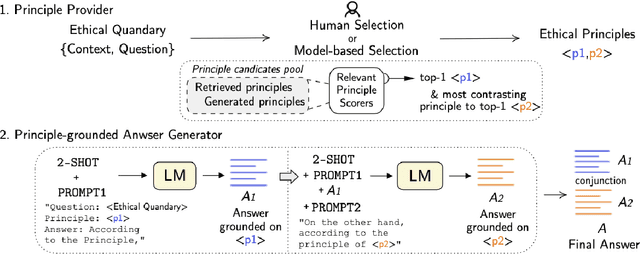


Considerable advancements have been made in various NLP tasks based on the impressive power of large pre-trained language models (LLMs). These results have inspired efforts to understand the limits of LLMs so as to evaluate how far we are from achieving human level general natural language understanding. In this work, we challenge the capability of LLMs with the new task of Ethical Quandary Generative Question Answering. Ethical quandary questions are more challenging to address because multiple conflicting answers may exist to a single quandary. We propose a system, AiSocrates, that provides an answer with a deliberative exchange of different perspectives to an ethical quandary, in the approach of Socratic philosophy, instead of providing a closed answer like an oracle. AiSocrates searches for different ethical principles applicable to the ethical quandary and generates an answer conditioned on the chosen principles through prompt-based few-shot learning. We also address safety concerns by providing a human controllability option in choosing ethical principles. We show that AiSocrates generates promising answers to ethical quandary questions with multiple perspectives, 6.92% more often than answers written by human philosophers by one measure, but the system still needs improvement to match the coherence of human philosophers fully. We argue that AiSocrates is a promising step toward developing an NLP system that incorporates human values explicitly by prompt instructions. We are releasing the code for research purposes.
Automatic Speech Recognition Datasets in Cantonese: A Survey and New Dataset
Jan 17, 2022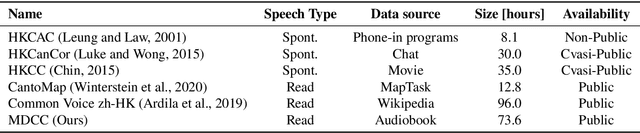
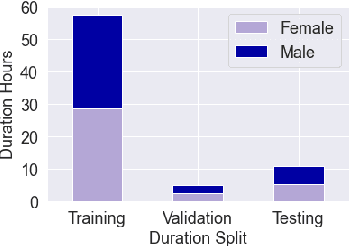
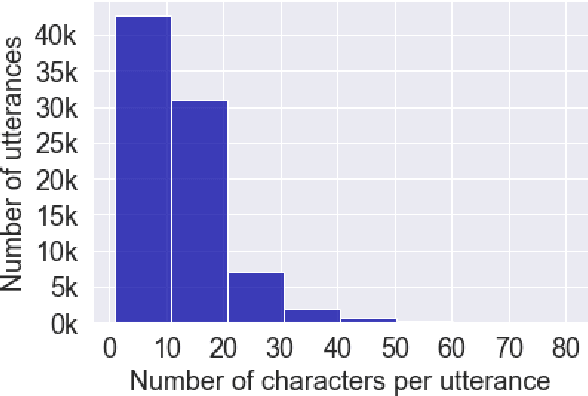
Automatic speech recognition (ASR) on low resource languages improves the access of linguistic minorities to technological advantages provided by artificial intelligence (AI). In this paper, we address the problem of data scarcity for the Hong Kong Cantonese language by creating a new Cantonese dataset. Our dataset, Multi-Domain Cantonese Corpus (MDCC), consists of 73.6 hours of clean read speech paired with transcripts, collected from Cantonese audiobooks from Hong Kong. It comprises philosophy, politics, education, culture, lifestyle and family domains, covering a wide range of topics. We also review all existing Cantonese datasets and analyze them according to their speech type, data source, total size and availability. We further conduct experiments with Fairseq S2T Transformer, a state-of-the-art ASR model, on the biggest existing dataset, Common Voice zh-HK, and our proposed MDCC, and the results show the effectiveness of our dataset. In addition, we create a powerful and robust Cantonese ASR model by applying multi-dataset learning on MDCC and Common Voice zh-HK.
CI-AVSR: A Cantonese Audio-Visual Speech Dataset for In-car Command Recognition
Jan 11, 2022
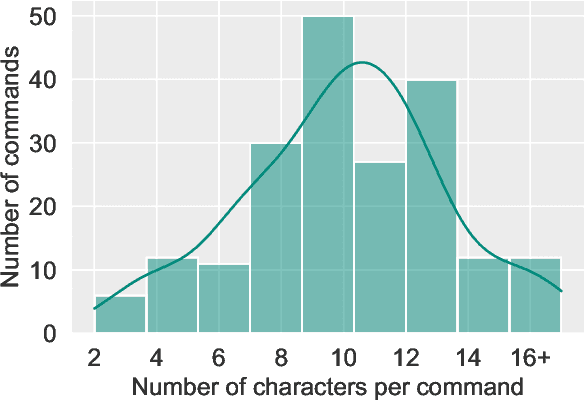
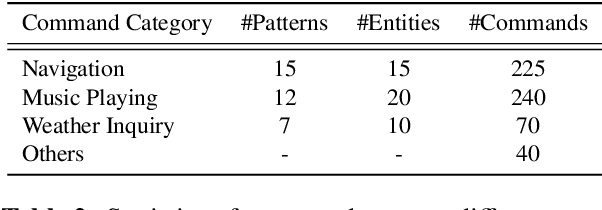
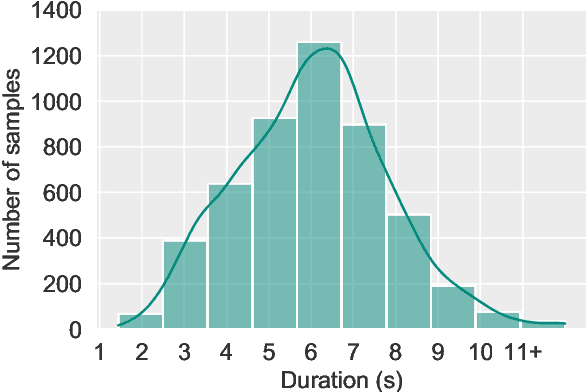
With the rise of deep learning and intelligent vehicle, the smart assistant has become an essential in-car component to facilitate driving and provide extra functionalities. In-car smart assistants should be able to process general as well as car-related commands and perform corresponding actions, which eases driving and improves safety. However, there is a data scarcity issue for low resource languages, hindering the development of research and applications. In this paper, we introduce a new dataset, Cantonese In-car Audio-Visual Speech Recognition (CI-AVSR), for in-car command recognition in the Cantonese language with both video and audio data. It consists of 4,984 samples (8.3 hours) of 200 in-car commands recorded by 30 native Cantonese speakers. Furthermore, we augment our dataset using common in-car background noises to simulate real environments, producing a dataset 10 times larger than the collected one. We provide detailed statistics of both the clean and the augmented versions of our dataset. Moreover, we implement two multimodal baselines to demonstrate the validity of CI-AVSR. Experiment results show that leveraging the visual signal improves the overall performance of the model. Although our best model can achieve a considerable quality on the clean test set, the speech recognition quality on the noisy data is still inferior and remains as an extremely challenging task for real in-car speech recognition systems. The dataset and code will be released at https://github.com/HLTCHKUST/CI-AVSR.
ASCEND: A Spontaneous Chinese-English Dataset for Code-switching in Multi-turn Conversation
Jan 07, 2022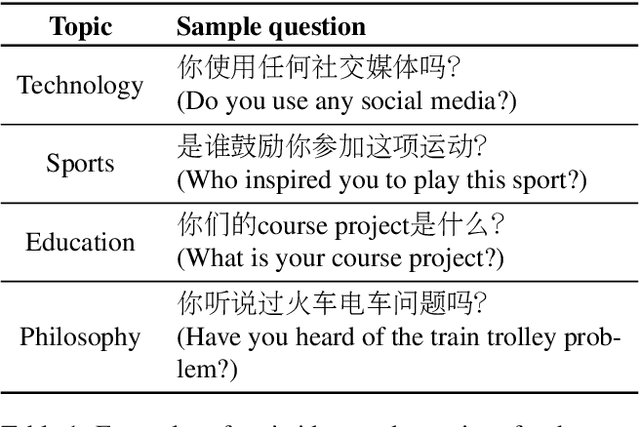

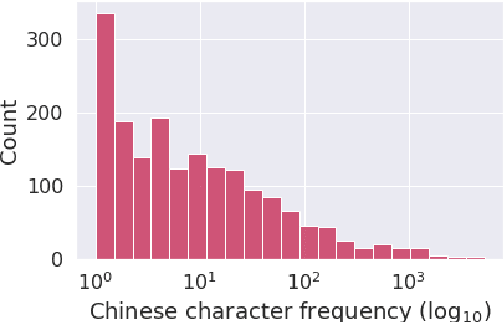
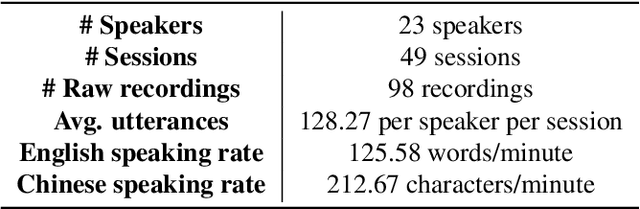
Code-switching is a speech phenomenon when a speaker switches language during a conversation. Despite the spontaneous nature of code-switching in conversational spoken language, most existing works collect code-switching data through read speech instead of spontaneous speech. ASCEND (A Spontaneous Chinese-English Dataset) introduces a high-quality resource of spontaneous multi-turn conversational dialogue Chinese-English code-switching corpus collected in Hong Kong. We report ASCEND's design and procedure of collecting the speech data, including the annotations in this work. ASCEND includes 23 bilinguals that are fluent in both Chinese and English and consists of 10.62 hours clean speech corpus. We also conduct a baseline experiment using pre-trained wav2vec 2.0 models, achieving the best performance of 22.69% character error rate and 27.05% mixed error rate.
A Study on the Autoregressive and non-Autoregressive Multi-label Learning
Dec 03, 2020Extreme classification tasks are multi-label tasks with an extremely large number of labels (tags). These tasks are hard because the label space is usually (i) very large, e.g. thousands or millions of labels, (ii) very sparse, i.e. very few labels apply to each input document, and (iii) highly correlated, meaning that the existence of one label changes the likelihood of predicting all other labels. In this work, we propose a self-attention based variational encoder-model to extract the label-label and label-feature dependencies jointly and to predict labels for a given input. In more detail, we propose a non-autoregressive latent variable model and compare it to a strong autoregressive baseline that predicts a label based on all previously generated labels. Our model can therefore be used to predict all labels in parallel while still including both label-label and label-feature dependencies through latent variables, and compares favourably to the autoregressive baseline. We apply our models to four standard extreme classification natural language data sets, and one news videos dataset for automated label detection from a lexicon of semantic concepts. Experimental results show that although the autoregressive models, where use a given order of the labels for chain-order label prediction, work great for the small scale labels or the prediction of the highly ranked label, but our non-autoregressive model surpasses them by around 2% to 6% when we need to predict more labels, or the dataset has a larger number of the labels.
CAiRE-COVID: A Question Answering and Multi-Document Summarization System for COVID-19 Research
May 04, 2020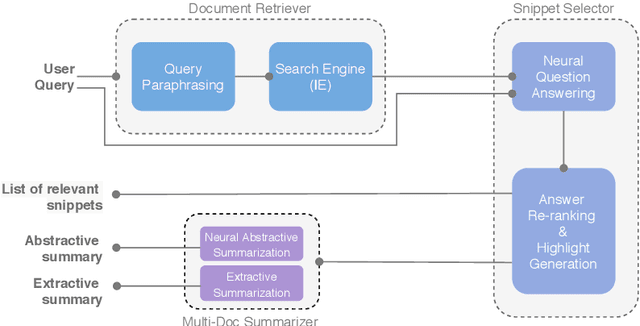
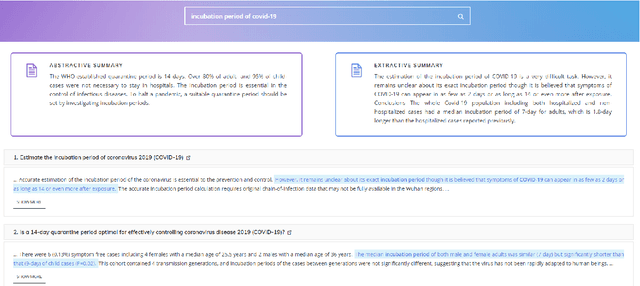
To address the need for refined information in COVID-19 pandemic, we propose a deep learning-based system that uses state-of-the-art natural language processing (NLP) question answering (QA) techniques combined with summarization for mining the available scientific literature. Our system leverages the Information Retrieval (IR) system and QA models to extract relevant snippets from the existing literature given a query. Fluent summaries are also provided to help understand the content in a more efficient way. In this paper, we describe our CAiRE-COVID system architecture and methodology for building the system. To bootstrap the further study, the code for our system is available at https://github.com/HLTCHKUST/CAiRE-COVID
On the Effectiveness of Low-Rank Matrix Factorization for LSTM Model Compression
Aug 27, 2019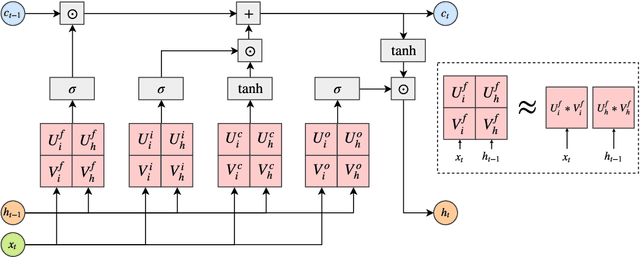
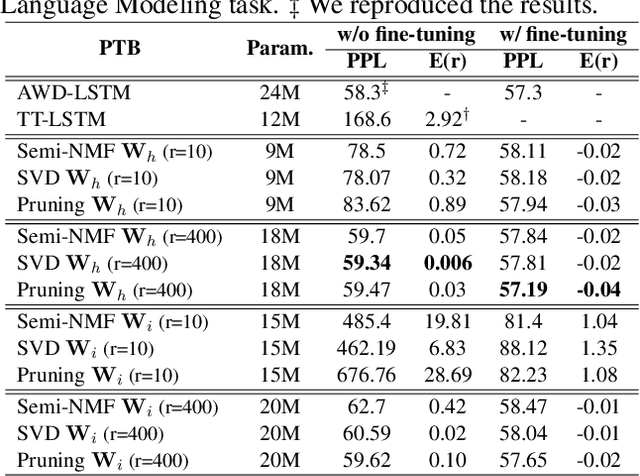
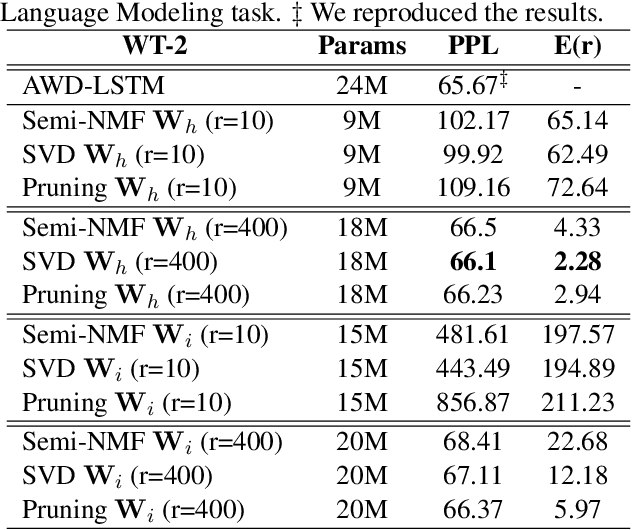
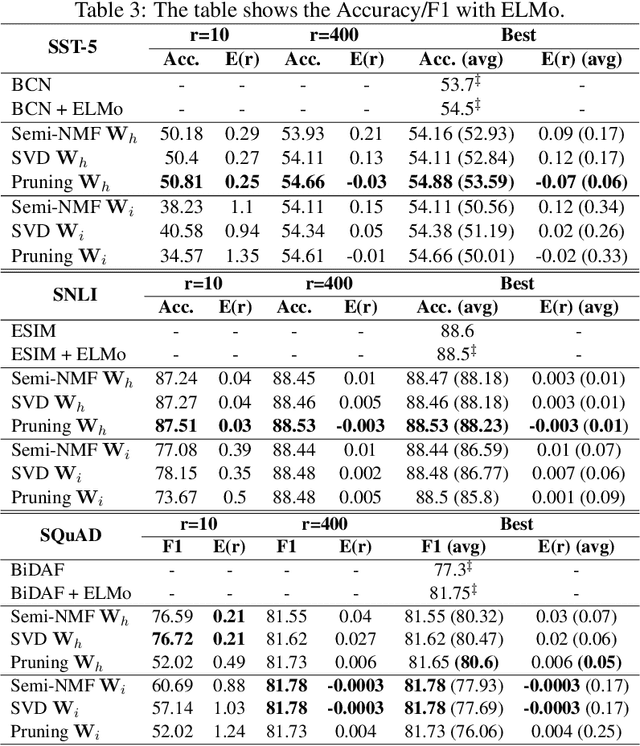
Despite their ubiquity in NLP tasks, Long Short-Term Memory (LSTM) networks suffer from computational inefficiencies caused by inherent unparallelizable recurrences, which further aggravates as LSTMs require more parameters for larger memory capacity. In this paper, we propose to apply low-rank matrix factorization (MF) algorithms to different recurrences in LSTMs, and explore the effectiveness on different NLP tasks and model components. We discover that additive recurrence is more important than multiplicative recurrence, and explain this by identifying meaningful correlations between matrix norms and compression performance. We compare our approach across two settings: 1) compressing core LSTM recurrences in language models, 2) compressing biLSTM layers of ELMo evaluated in three downstream NLP tasks.