 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlack-box constructions for exchangeable sequences of random multisets
Aug 17, 2019We develop constructions for exchangeable sequences of point processes that are rendered conditionally-i.i.d. negative binomial processes by a (possibly unknown) random measure called the base measure. Negative binomial processes are useful in Bayesian nonparametrics as models for random multisets, and in applications we are often interested in cases when the base measure itself is difficult to construct (for example when it has countably infinite support). While a finitary construction for an important case (corresponding to a beta process base measure) has appeared in the literature, our constructions generalize to any random base measure, requiring only an exchangeable sequence of Bernoulli processes rendered conditionally-i.i.d. by the same underlying random base measure. Because finitary constructions for such Bernoulli processes are known for several different classes of random base measures--including generalizations of the beta process and hierarchies thereof--our results immediately provide constructions for negative binomial processes with a random base measure from any member of these classes.
Scalable Bayesian dynamic covariance modeling with variational Wishart and inverse Wishart processes
Jun 22, 2019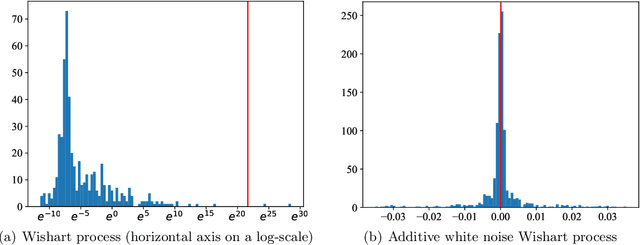
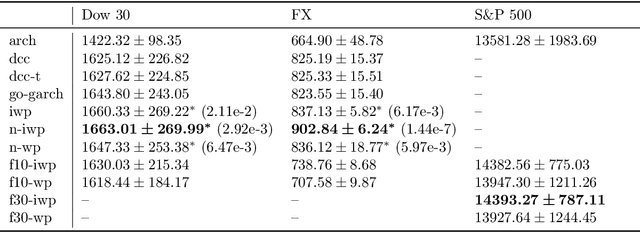
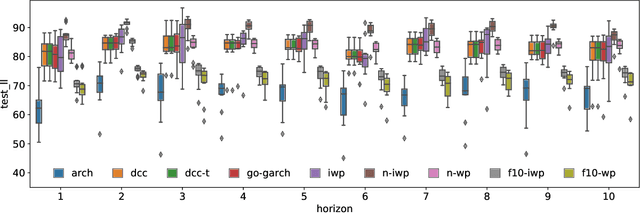
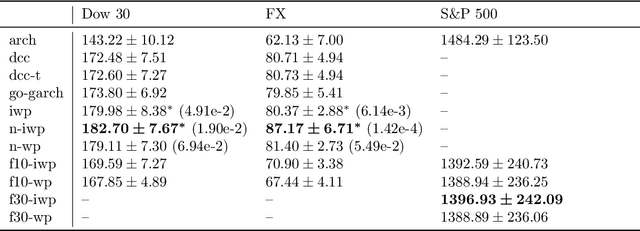
We implement gradient-based variational inference routines for Wishart and inverse Wishart processes, which we apply as Bayesian models for the dynamic, heteroskedastic covariance matrix of a multivariate time series. The Wishart and inverse Wishart processes are constructed from i.i.d. Gaussian processes, for which we apply existing black-box variational inference algorithms for approximate Gaussian process inference. These methods scale well with the length of the time series, however, they fail in the case of the Wishart process, an issue we resolve with a simple modification into an additive white noise parameterization of the model. This modification is also key to implementing a factored variant of the construction, allowing inference to additionally scale to high-dimensional covariance matrices. As with existing MCMC-based inference routines for the Wishart and inverse Wishart processes, we show that these variational alternatives significantly outperform multivariate GARCH baselines when forecasting the covariances of returns on financial instruments.
Variational inference for neural network matrix factorization and its application to stochastic blockmodeling
May 11, 2019

We consider the probabilistic analogue to neural network matrix factorization (Dziugaite & Roy, 2015), which we construct with Bayesian neural networks and fit with variational inference. We find that a linear model fit with variational inference can attain equivalent predictive performance to the neural network variants on the Movielens data sets. We discuss the implications of this result, which include some suggestions on the pros and cons of using the neural network construction, as well as the variational approach to inference. A probabilistic approach is required in some cases, however, such as when considering the important class of stochastic blockmodels. We describe a variational inference algorithm for a neural network matrix factorization model with nonparametric block structure and evaluate it on the NIPS co-authorship data set.
Bayesian inference on random simple graphs with power law degree distributions
Jun 18, 2017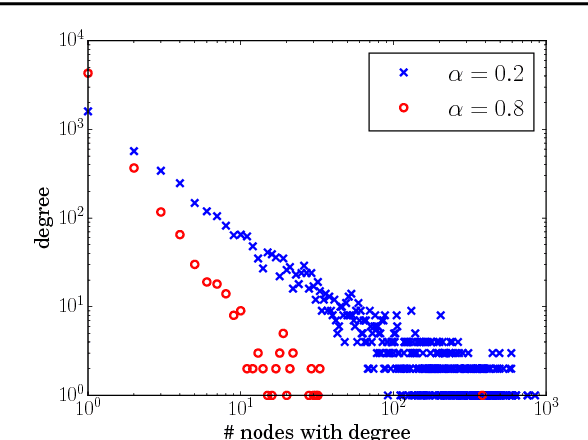

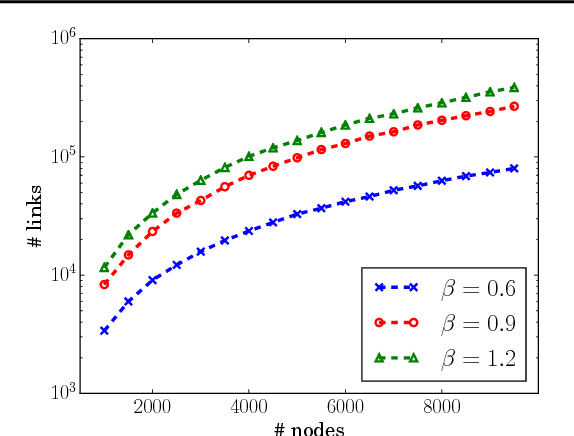
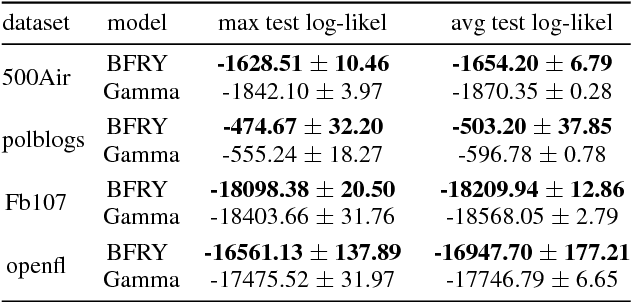
We present a model for random simple graphs with a degree distribution that obeys a power law (i.e., is heavy-tailed). To attain this behavior, the edge probabilities in the graph are constructed from Bertoin-Fujita-Roynette-Yor (BFRY) random variables, which have been recently utilized in Bayesian statistics for the construction of power law models in several applications. Our construction readily extends to capture the structure of latent factors, similarly to stochastic blockmodels, while maintaining its power law degree distribution. The BFRY random variables are well approximated by gamma random variables in a variational Bayesian inference routine, which we apply to several network datasets for which power law degree distributions are a natural assumption. By learning the parameters of the BFRY distribution via probabilistic inference, we are able to automatically select the appropriate power law behavior from the data. In order to further scale our inference procedure, we adopt stochastic gradient ascent routines where the gradients are computed on minibatches (i.e., subsets) of the edges in the graph.
The combinatorial structure of beta negative binomial processes
Jun 23, 2016We characterize the combinatorial structure of conditionally-i.i.d. sequences of negative binomial processes with a common beta process base measure. In Bayesian nonparametric applications, such processes have served as models for latent multisets of features underlying data. Analogously, random subsets arise from conditionally-i.i.d. sequences of Bernoulli processes with a common beta process base measure, in which case the combinatorial structure is described by the Indian buffet process. Our results give a count analogue of the Indian buffet process, which we call a negative binomial Indian buffet process. As an intermediate step toward this goal, we provide a construction for the beta negative binomial process that avoids a representation of the underlying beta process base measure. We describe the key Markov kernels needed to use a NB-IBP representation in a Markov Chain Monte Carlo algorithm targeting a posterior distribution.
* Published at http://dx.doi.org/10.3150/15-BEJ729 in the Bernoulli (http://isi.cbs.nl/bernoulli/) by the International Statistical Institute/Bernoulli Society (http://isi.cbs.nl/BS/bshome.htm)
Gibbs-type Indian buffet processes
Dec 08, 2015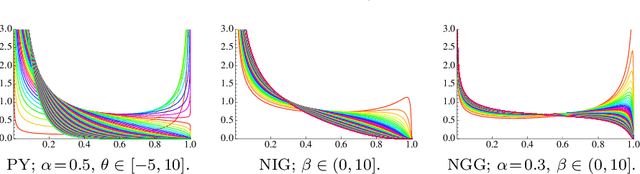
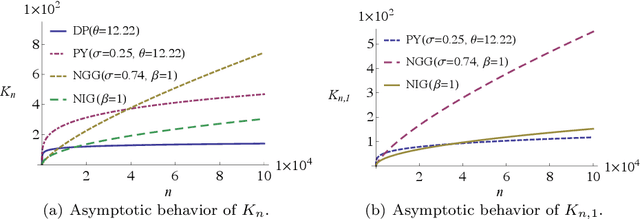
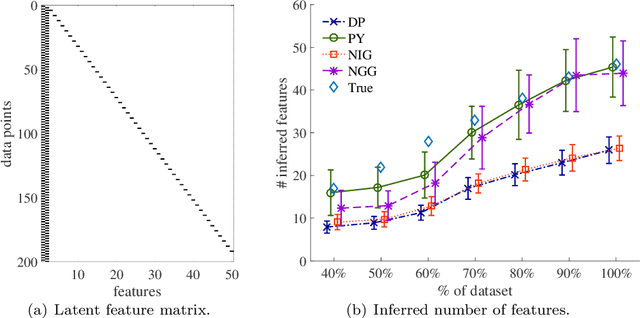
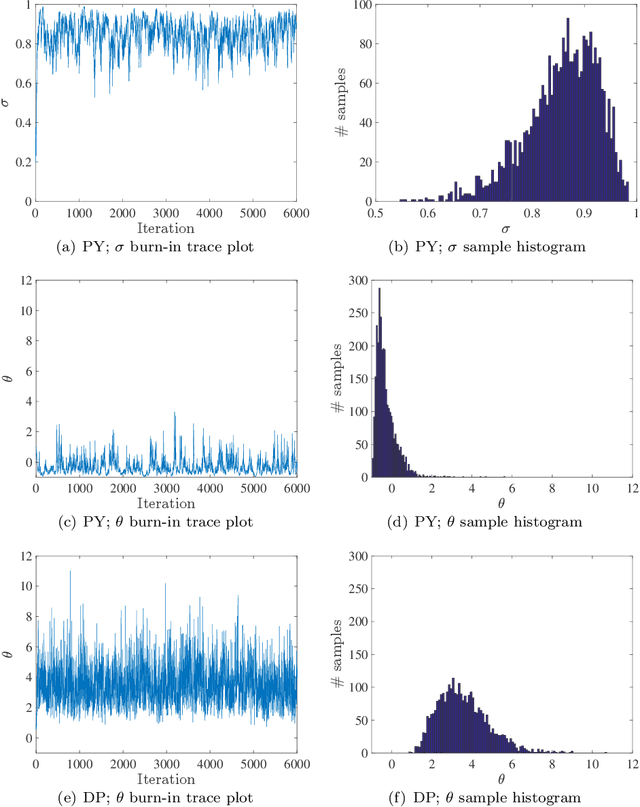
We investigate a class of feature allocation models that generalize the Indian buffet process and are parameterized by Gibbs-type random measures. Two existing classes are contained as special cases: the original two-parameter Indian buffet process, corresponding to the Dirichlet process, and the stable (or three-parameter) Indian buffet process, corresponding to the Pitman-Yor process. Asymptotic behavior of the Gibbs-type partitions, such as power laws holding for the number of latent clusters, translates into analogous characteristics for this class of Gibbs-type feature allocation models. Despite containing several different distinct subclasses, the properties of Gibbs-type partitions allow us to develop a black-box procedure for posterior inference within any subclass of models. Through numerical experiments, we compare and contrast a few of these subclasses and highlight the utility of varying power-law behaviors in the latent features.
Beta diffusion trees and hierarchical feature allocations
Apr 03, 2015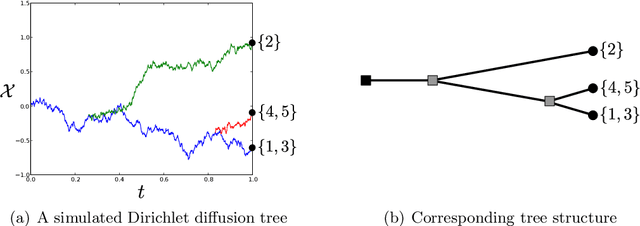
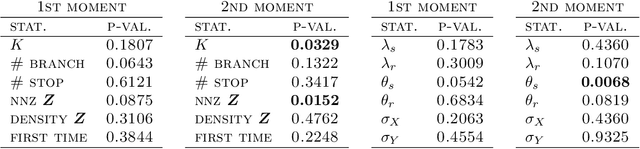
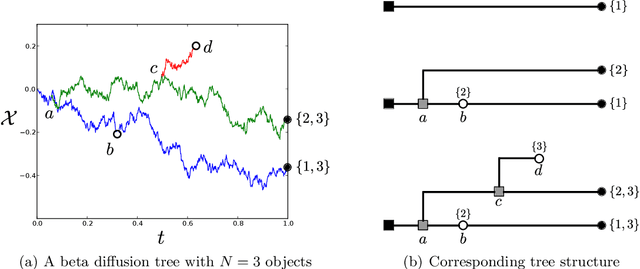
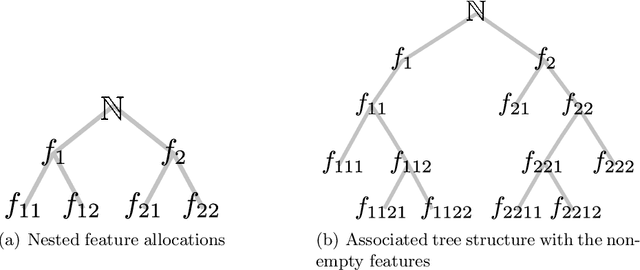
We define the beta diffusion tree, a random tree structure with a set of leaves that defines a collection of overlapping subsets of objects, known as a feature allocation. A generative process for the tree structure is defined in terms of particles (representing the objects) diffusing in some continuous space, analogously to the Dirichlet diffusion tree (Neal, 2003), which defines a tree structure over partitions (i.e., non-overlapping subsets) of the objects. Unlike in the Dirichlet diffusion tree, multiple copies of a particle may exist and diffuse along multiple branches in the beta diffusion tree, and an object may therefore belong to multiple subsets of particles. We demonstrate how to build a hierarchically-clustered factor analysis model with the beta diffusion tree and how to perform inference over the random tree structures with a Markov chain Monte Carlo algorithm. We conclude with several numerical experiments on missing data problems with data sets of gene expression microarrays, international development statistics, and intranational socioeconomic measurements.