 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeam Hitachi @ AutoMin 2021: Reference-free Automatic Minuting Pipeline with Argument Structure Construction over Topic-based Summarization
Dec 06, 2021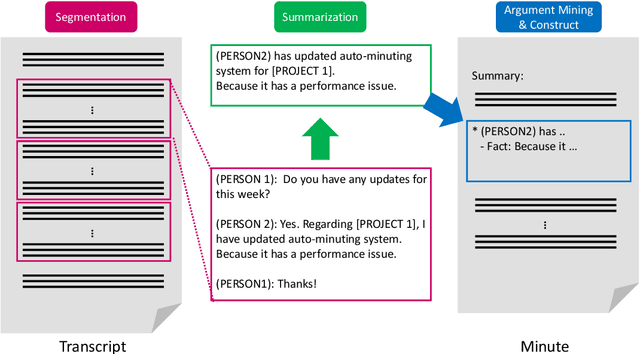


This paper introduces the proposed automatic minuting system of the Hitachi team for the First Shared Task on Automatic Minuting (AutoMin-2021). We utilize a reference-free approach (i.e., without using training minutes) for automatic minuting (Task A), which first splits a transcript into blocks on the basis of topics and subsequently summarizes those blocks with a pre-trained BART model fine-tuned on a summarization corpus of chat dialogue. In addition, we apply a technique of argument mining to the generated minutes, reorganizing them in a well-structured and coherent way. We utilize multiple relevance scores to determine whether or not a minute is derived from the same meeting when either a transcript or another minute is given (Task B and C). On top of those scores, we train a conventional machine learning model to bind them and to make final decisions. Consequently, our approach for Task A achieve the best adequacy score among all submissions and close performance to the best system in terms of grammatical correctness and fluency. For Task B and C, the proposed model successfully outperformed a majority vote baseline.
Emotional Speech Synthesis for Companion Robot to Imitate Professional Caregiver Speech
Sep 27, 2021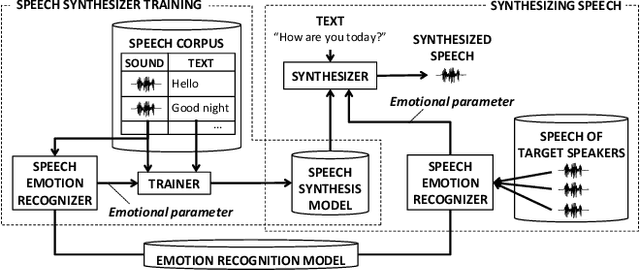
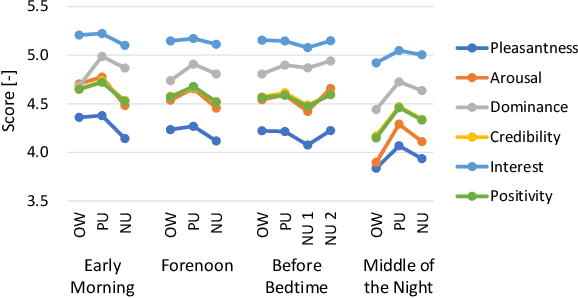


When people try to influence others to do something, they subconsciously adjust their speech to include appropriate emotional information. In order for a robot to influence people in the same way, the robot should be able to imitate the range of human emotions when speaking. To achieve this, we propose a speech synthesis method for imitating the emotional states in human speech. In contrast to previous methods, the advantage of our method is that it requires less manual effort to adjust the emotion of the synthesized speech. Our synthesizer receives an emotion vector to characterize the emotion of synthesized speech. The vector is automatically obtained from human utterances by using a speech emotion recognizer. We evaluated our method in a scenario when a robot tries to regulate an elderly person's circadian rhythm by speaking to the person using appropriate emotional states. For the target speech to imitate, we collected utterances from professional caregivers when they speak to elderly people at different times of the day. Then we conducted a subjective evaluation where the elderly participants listened to the speech samples generated by our method. The results showed that listening to the samples made the participants feel more active in the early morning and calmer in the middle of the night. This suggests that the robot may be able to adjust the participants' circadian rhythm and that the robot can potentially exert influence similarly to a person.
Semi-Supervised Training with Pseudo-Labeling for End-to-End Neural Diarization
Jun 09, 2021
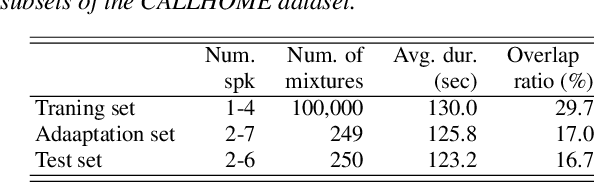
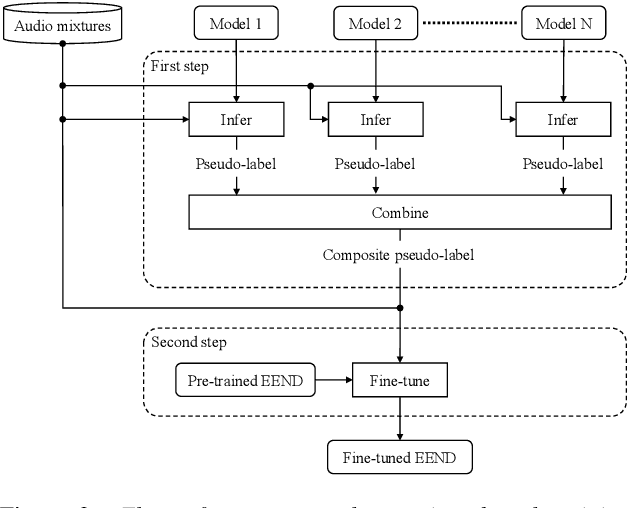
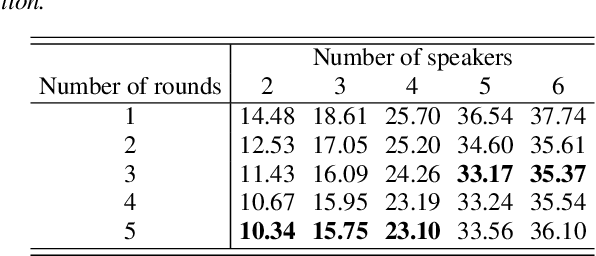
In this paper, we present a semi-supervised training technique using pseudo-labeling for end-to-end neural diarization (EEND). The EEND system has shown promising performance compared with traditional clustering-based methods, especially in the case of overlapping speech. However, to get a well-tuned model, EEND requires labeled data for all the joint speech activities of every speaker at each time frame in a recording. In this paper, we explore a pseudo-labeling approach that employs unlabeled data. First, we propose an iterative pseudo-label method for EEND, which trains the model using unlabeled data of a target condition. Then, we also propose a committee-based training method to improve the performance of EEND. To evaluate our proposed method, we conduct the experiments of model adaptation using labeled and unlabeled data. Experimental results on the CALLHOME dataset show that our proposed pseudo-label achieved a 37.4% relative diarization error rate reduction compared to a seed model. Moreover, we analyzed the results of semi-supervised adaptation with pseudo-labeling. We also show the effectiveness of our approach on the third DIHARD dataset.
End-to-End Speaker Diarization Conditioned on Speech Activity and Overlap Detection
Jun 08, 2021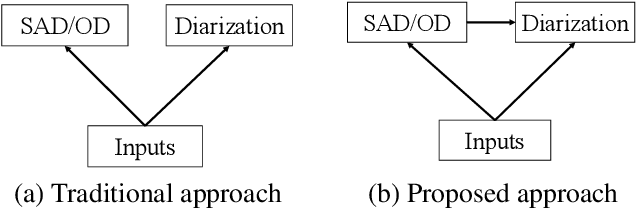
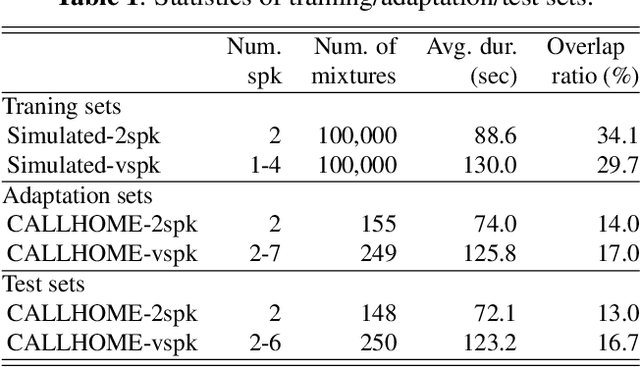
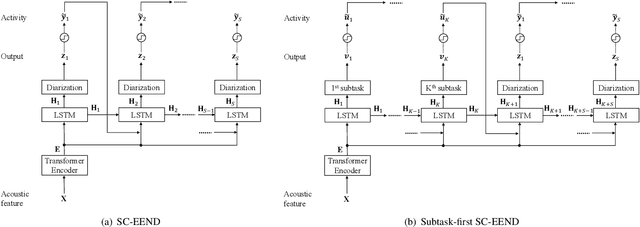
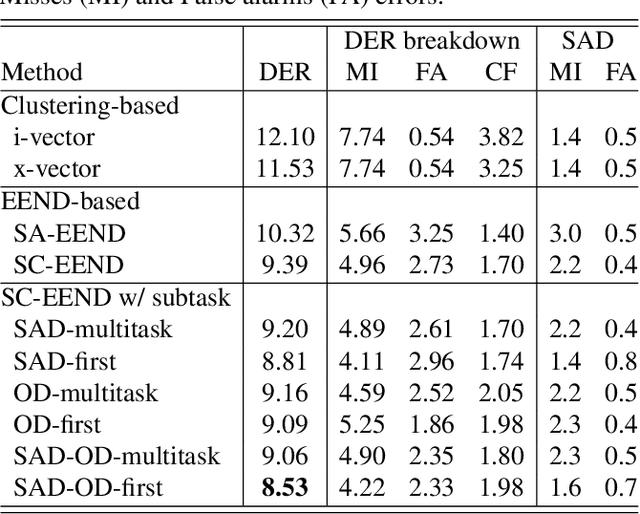
In this paper, we present a conditional multitask learning method for end-to-end neural speaker diarization (EEND). The EEND system has shown promising performance compared with traditional clustering-based methods, especially in the case of overlapping speech. In this paper, to further improve the performance of the EEND system, we propose a novel multitask learning framework that solves speaker diarization and a desired subtask while explicitly considering the task dependency. We optimize speaker diarization conditioned on speech activity and overlap detection that are subtasks of speaker diarization, based on the probabilistic chain rule. Experimental results show that our proposed method can leverage a subtask to effectively model speaker diarization, and outperforms conventional EEND systems in terms of diarization error rate.
* Accepted for SLT 2021
Online End-to-End Neural Diarization Handling Overlapping Speech and Flexible Numbers of Speakers
Jan 21, 2021
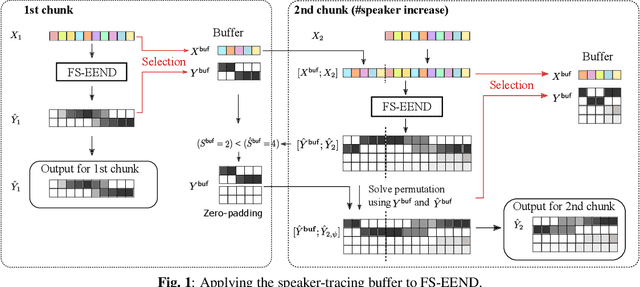


This paper proposes an online end-to-end diarization that can handle overlapping speech and flexible numbers of speakers. The end-to-end neural speaker diarization (EEND) model has already achieved significant improvement when compared with conventional clustering-based methods. However, the original EEND has two limitations: i) EEND does not perform well in online scenarios; ii) the number of speakers must be fixed in advance. This paper solves both problems by applying a modified extension of the speaker-tracing buffer method that deals with variable numbers of speakers. Experiments on CALLHOME and DIHARD II datasets show that the proposed online method achieves comparable performance to the offline EEND method. Compared with the state-of-the-art online method based on a fully supervised approach (UIS-RNN), the proposed method shows better performance on the DIHARD II dataset.
Building Multi lingual TTS using Cross Lingual Voice Conversion
Dec 28, 2020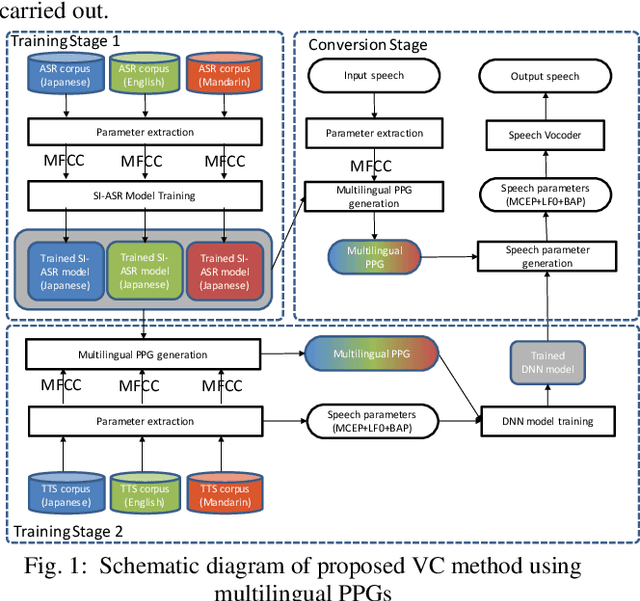
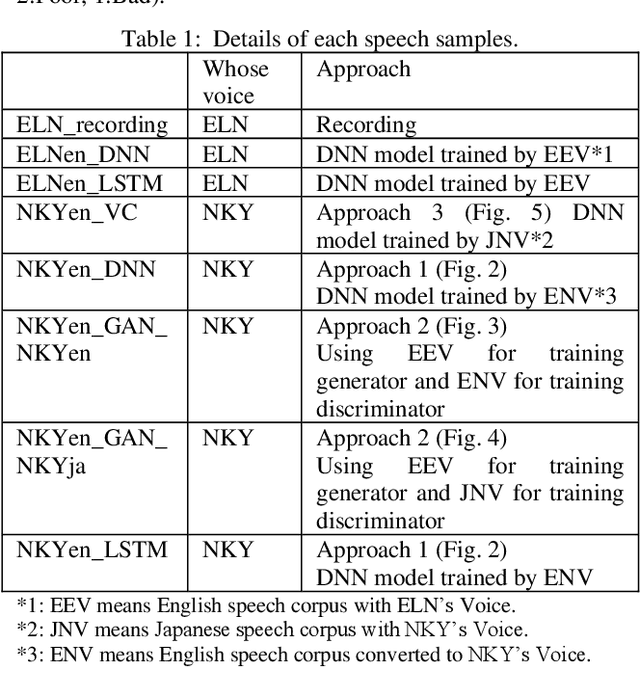
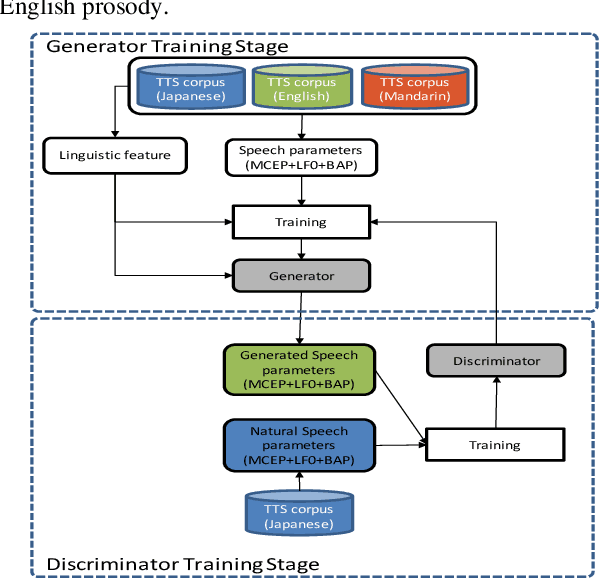
In this paper we propose a new cross-lingual Voice Conversion (VC) approach which can generate all speech parameters (MCEP, LF0, BAP) from one DNN model using PPGs (Phonetic PosteriorGrams) extracted from inputted speech using several ASR acoustic models. Using the proposed VC method, we tried three different approaches to build a multilingual TTS system without recording a multilingual speech corpus. A listening test was carried out to evaluate both speech quality (naturalness) and voice similarity between converted speech and target speech. The results show that Approach 1 achieved the highest level of naturalness (3.28 MOS on a 5-point scale) and similarity (2.77 MOS).
End-to-End Speaker Diarization as Post-Processing
Dec 23, 2020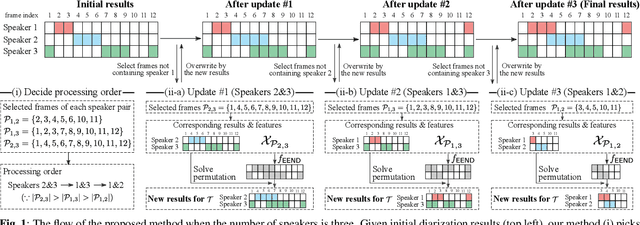

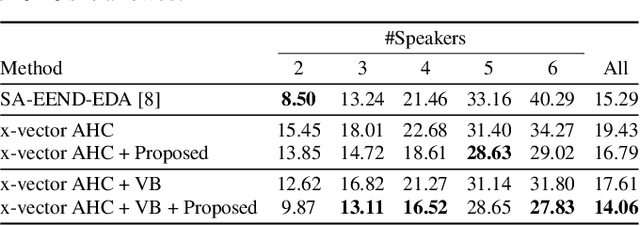
This paper investigates the utilization of an end-to-end diarization model as post-processing of conventional clustering-based diarization. Clustering-based diarization methods partition frames into clusters of the number of speakers; thus, they typically cannot handle overlapping speech because each frame is assigned to one speaker. On the other hand, some end-to-end diarization methods can handle overlapping speech by treating the problem as multi-label classification. Although some methods can treat a flexible number of speakers, they do not perform well when the number of speakers is large. To compensate for each other's weakness, we propose to use a two-speaker end-to-end diarization method as post-processing of the results obtained by a clustering-based method. We iteratively select two speakers from the results and update the results of the two speakers to improve the overlapped region. Experimental results show that the proposed algorithm consistently improved the performance of the state-of-the-art methods across CALLHOME, AMI, and DIHARD II datasets.
Utterance-Wise Meeting Transcription System Using Asynchronous Distributed Microphones
Jul 31, 2020
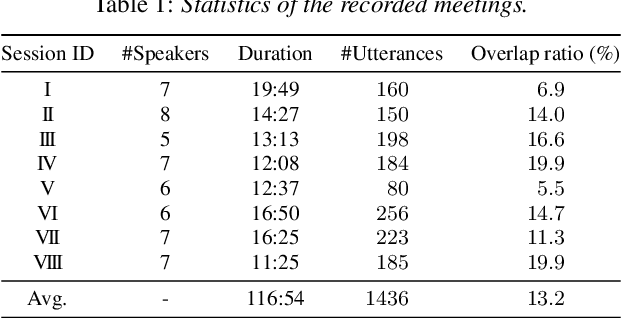
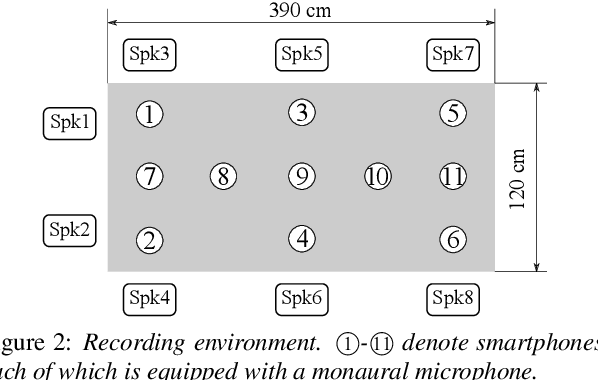
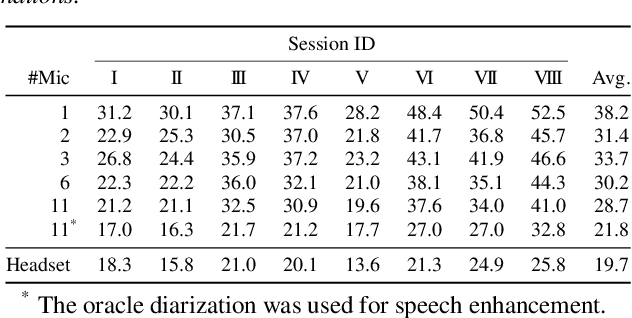
A novel framework for meeting transcription using asynchronous microphones is proposed in this paper. It consists of audio synchronization, speaker diarization, utterance-wise speech enhancement using guided source separation, automatic speech recognition, and duplication reduction. Doing speaker diarization before speech enhancement enables the system to deal with overlapped speech without considering sampling frequency mismatch between microphones. Evaluation on our real meeting datasets showed that our framework achieved a character error rate (CER) of 28.7 % by using 11 distributed microphones, while a monaural microphone placed on the center of the table had a CER of 38.2 %. We also showed that our framework achieved CER of 21.8 %, which is only 2.1 percentage points higher than the CER in headset microphone-based transcription.
Neural Speaker Diarization with Speaker-Wise Chain Rule
Jun 02, 2020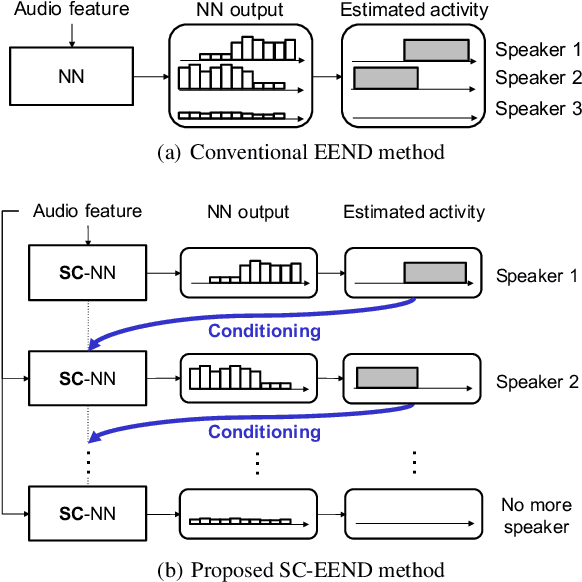
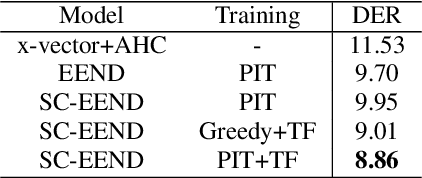
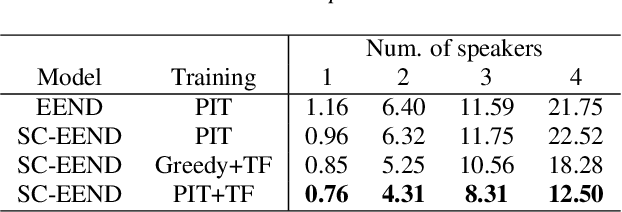
Speaker diarization is an essential step for processing multi-speaker audio. Although an end-to-end neural diarization (EEND) method achieved state-of-the-art performance, it is limited to a fixed number of speakers. In this paper, we solve this fixed number of speaker issue by a novel speaker-wise conditional inference method based on the probabilistic chain rule. In the proposed method, each speaker's speech activity is regarded as a single random variable, and is estimated sequentially conditioned on previously estimated other speakers' speech activities. Similar to other sequence-to-sequence models, the proposed method produces a variable number of speakers with a stop sequence condition. We evaluated the proposed method on multi-speaker audio recordings of a variable number of speakers. Experimental results show that the proposed method can correctly produce diarization results with a variable number of speakers and outperforms the state-of-the-art end-to-end speaker diarization methods in terms of diarization error rate.
End-to-End Speaker Diarization for an Unknown Number of Speakers with Encoder-Decoder Based Attractors
May 20, 2020
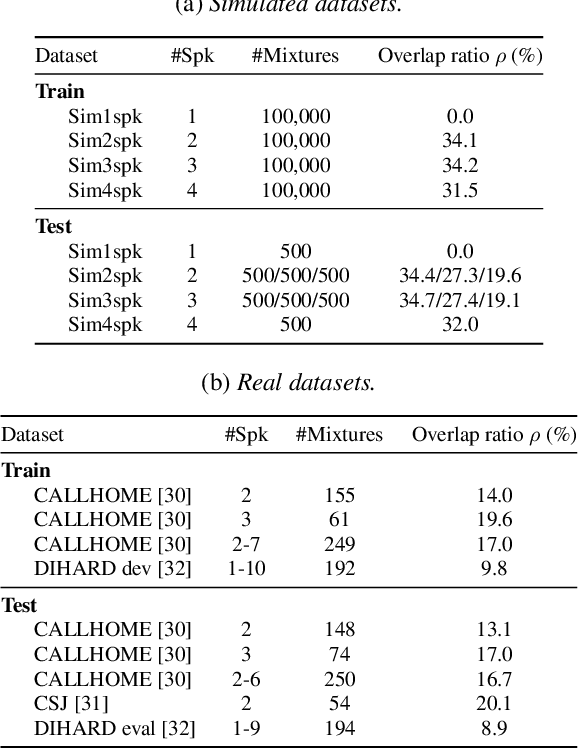
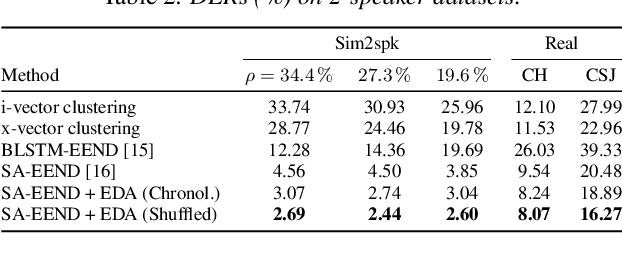

End-to-end speaker diarization for an unknown number of speakers is addressed in this paper. Recently proposed end-to-end speaker diarization outperformed conventional clustering-based speaker diarization, but it has one drawback: it is less flexible in terms of the number of speakers. This paper proposes a method for encoder-decoder based attractor calculation (EDA), which first generates a flexible number of attractors from a speech embedding sequence. Then, the generated multiple attractors are multiplied by the speech embedding sequence to produce the same number of speaker activities. The speech embedding sequence is extracted using the conventional self-attentive end-to-end neural speaker diarization (SA-EEND) network. In a two-speaker condition, our method achieved a 2.69 % diarization error rate (DER) on simulated mixtures and a 8.07 % DER on the two-speaker subset of CALLHOME, while vanilla SA-EEND attained 4.56 % and 9.54 %, respectively. In unknown numbers of speakers conditions, our method attained a 15.29 % DER on CALLHOME, while the x-vector-based clustering method achieved a 19.43 % DER.