 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Training with Pseudo-Labeling for End-to-End Neural Diarization
Paper and Code

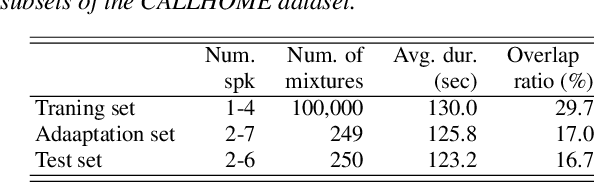
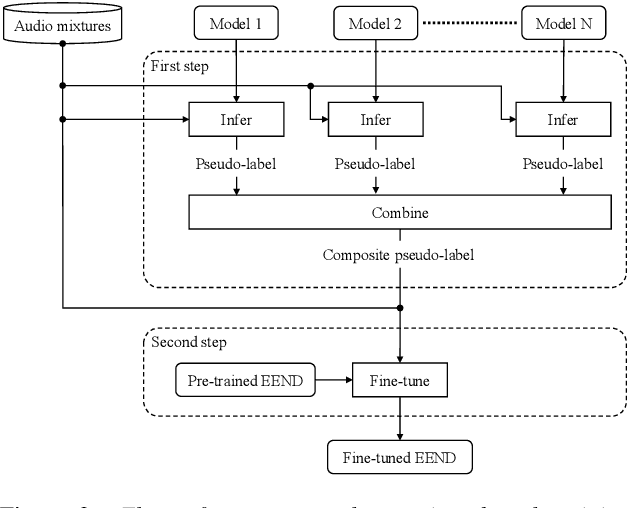
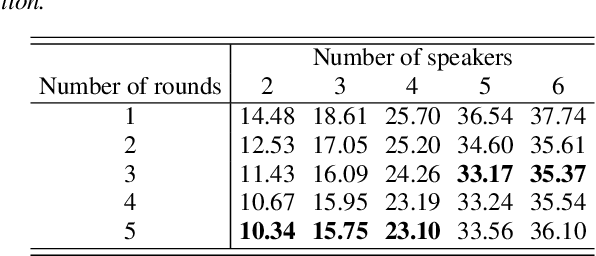
In this paper, we present a semi-supervised training technique using pseudo-labeling for end-to-end neural diarization (EEND). The EEND system has shown promising performance compared with traditional clustering-based methods, especially in the case of overlapping speech. However, to get a well-tuned model, EEND requires labeled data for all the joint speech activities of every speaker at each time frame in a recording. In this paper, we explore a pseudo-labeling approach that employs unlabeled data. First, we propose an iterative pseudo-label method for EEND, which trains the model using unlabeled data of a target condition. Then, we also propose a committee-based training method to improve the performance of EEND. To evaluate our proposed method, we conduct the experiments of model adaptation using labeled and unlabeled data. Experimental results on the CALLHOME dataset show that our proposed pseudo-label achieved a 37.4% relative diarization error rate reduction compared to a seed model. Moreover, we analyzed the results of semi-supervised adaptation with pseudo-labeling. We also show the effectiveness of our approach on the third DIHARD dataset.