 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMutual Learning of Single- and Multi-Channel End-to-End Neural Diarization
Oct 07, 2022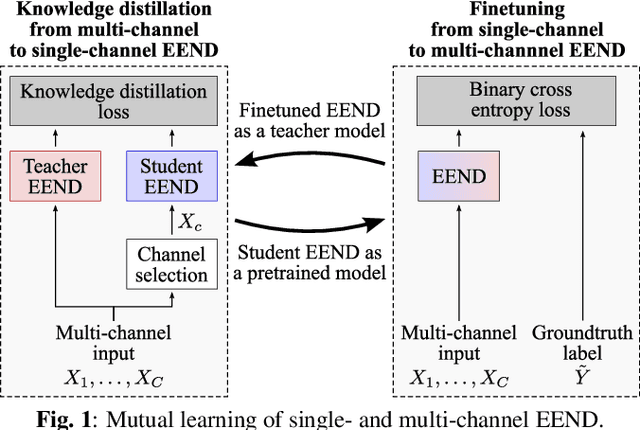
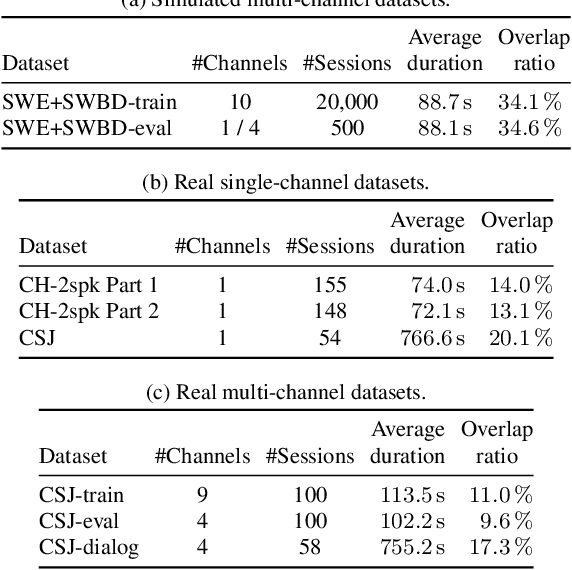
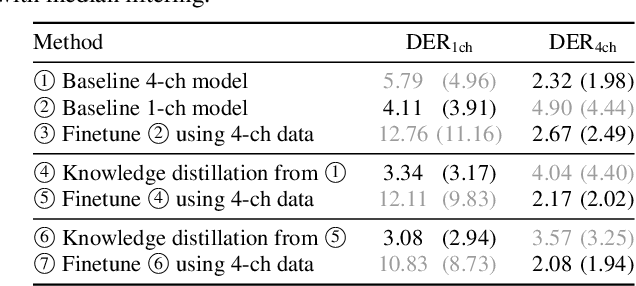
Due to the high performance of multi-channel speech processing, we can use the outputs from a multi-channel model as teacher labels when training a single-channel model with knowledge distillation. To the contrary, it is also known that single-channel speech data can benefit multi-channel models by mixing it with multi-channel speech data during training or by using it for model pretraining. This paper focuses on speaker diarization and proposes to conduct the above bi-directional knowledge transfer alternately. We first introduce an end-to-end neural diarization model that can handle both single- and multi-channel inputs. Using this model, we alternately conduct i) knowledge distillation from a multi-channel model to a single-channel model and ii) finetuning from the distilled single-channel model to a multi-channel model. Experimental results on two-speaker data show that the proposed method mutually improved single- and multi-channel speaker diarization performances.
Updating Only Encoders Prevents Catastrophic Forgetting of End-to-End ASR Models
Jul 01, 2022
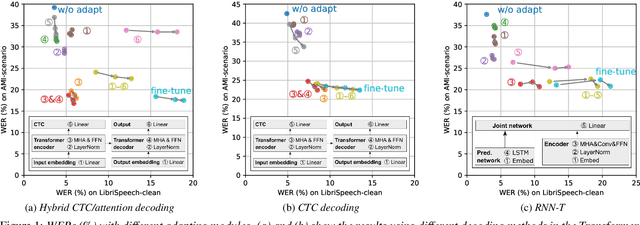
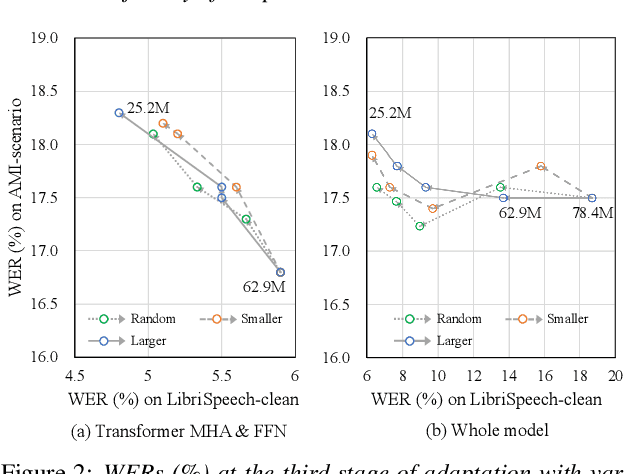
In this paper, we present an incremental domain adaptation technique to prevent catastrophic forgetting for an end-to-end automatic speech recognition (ASR) model. Conventional approaches require extra parameters of the same size as the model for optimization, and it is difficult to apply these approaches to end-to-end ASR models because they have a huge amount of parameters. To solve this problem, we first investigate which parts of end-to-end ASR models contribute to high accuracy in the target domain while preventing catastrophic forgetting. We conduct experiments on incremental domain adaptation from the LibriSpeech dataset to the AMI meeting corpus with two popular end-to-end ASR models and found that adapting only the linear layers of their encoders can prevent catastrophic forgetting. Then, on the basis of this finding, we develop an element-wise parameter selection focused on specific layers to further reduce the number of fine-tuning parameters. Experimental results show that our approach consistently prevents catastrophic forgetting compared to parameter selection from the whole model.
Online Neural Diarization of Unlimited Numbers of Speakers
Jun 06, 2022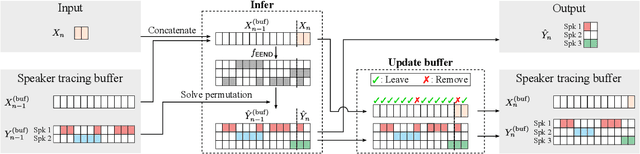
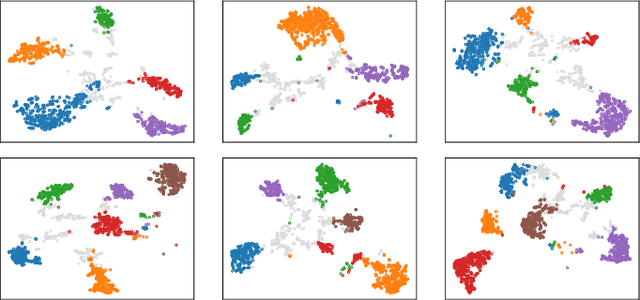
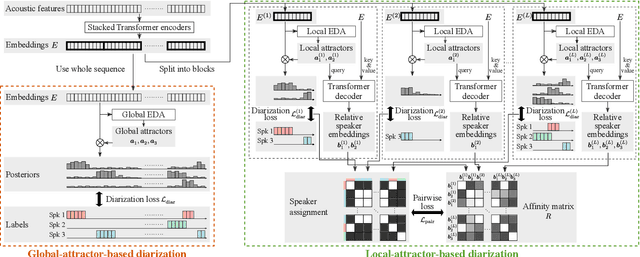
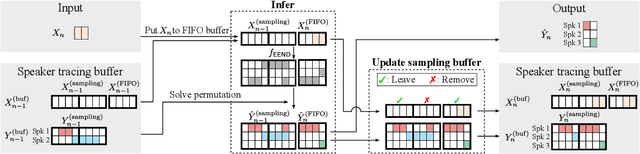
A method to perform offline and online speaker diarization for an unlimited number of speakers is described in this paper. End-to-end neural diarization (EEND) has achieved overlap-aware speaker diarization by formulating it as a multi-label classification problem. It has also been extended for a flexible number of speakers by introducing speaker-wise attractors. However, the output number of speakers of attractor-based EEND is empirically capped; it cannot deal with cases where the number of speakers appearing during inference is higher than that during training because its speaker counting is trained in a fully supervised manner. Our method, EEND-GLA, solves this problem by introducing unsupervised clustering into attractor-based EEND. In the method, the input audio is first divided into short blocks, then attractor-based diarization is performed for each block, and finally the results of each blocks are clustered on the basis of the similarity between locally-calculated attractors. While the number of output speakers is limited within each block, the total number of speakers estimated for the entire input can be higher than the limitation. To use EEND-GLA in an online manner, our method also extends the speaker-tracing buffer, which was originally proposed to enable online inference of conventional EEND. We introduces a block-wise buffer update to make the speaker-tracing buffer compatible with EEND-GLA. Finally, to improve online diarization, our method improves the buffer update method and revisits the variable chunk-size training of EEND. The experimental results demonstrate that EEND-GLA can perform speaker diarization of an unseen number of speakers in both offline and online inferences.
Multi-Channel End-to-End Neural Diarization with Distributed Microphones
Oct 10, 2021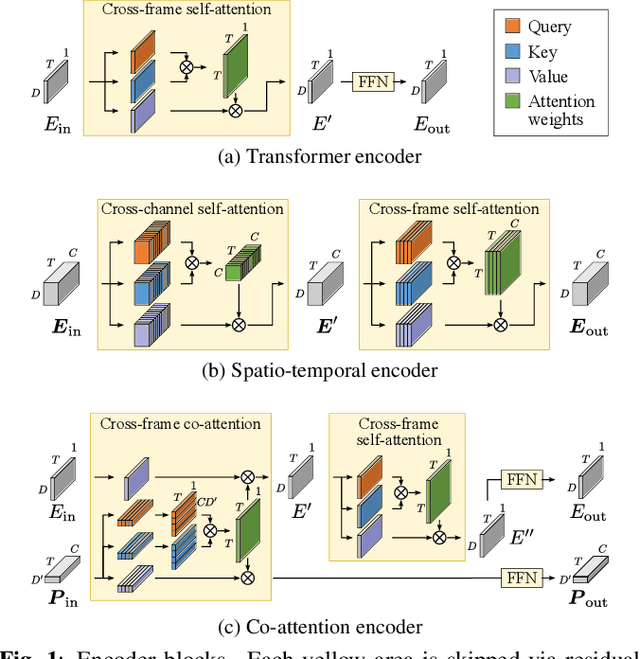
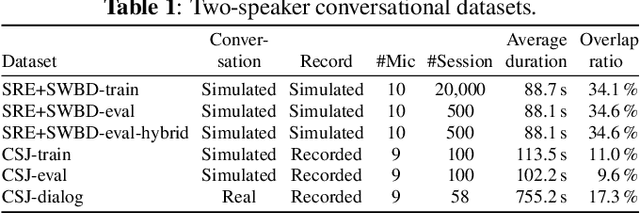

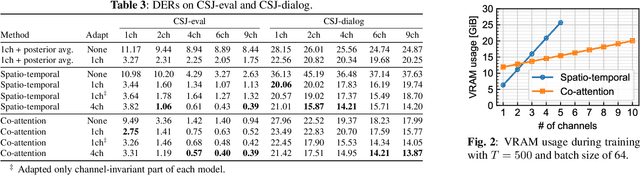
Recent progress on end-to-end neural diarization (EEND) has enabled overlap-aware speaker diarization with a single neural network. This paper proposes to enhance EEND by using multi-channel signals from distributed microphones. We replace Transformer encoders in EEND with two types of encoders that process a multi-channel input: spatio-temporal and co-attention encoders. Both are independent of the number and geometry of microphones and suitable for distributed microphone settings. We also propose a model adaptation method using only single-channel recordings. With simulated and real-recorded datasets, we demonstrated that the proposed method outperformed conventional EEND when a multi-channel input was given while maintaining comparable performance with a single-channel input. We also showed that the proposed method performed well even when spatial information is inoperative given multi-channel inputs, such as in hybrid meetings in which the utterances of multiple remote participants are played back from the same loudspeaker.
Towards Neural Diarization for Unlimited Numbers of Speakers Using Global and Local Attractors
Jul 04, 2021
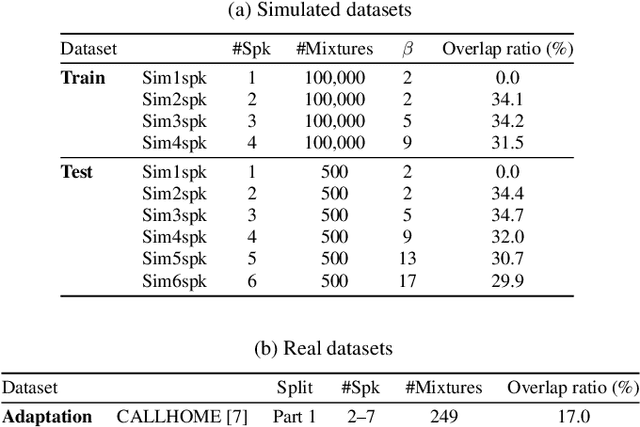
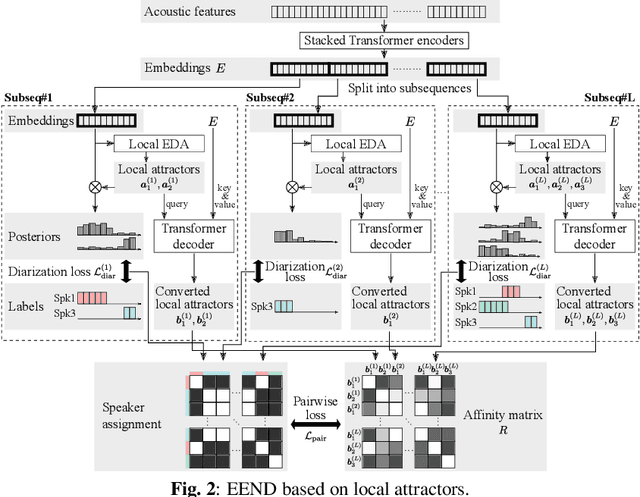
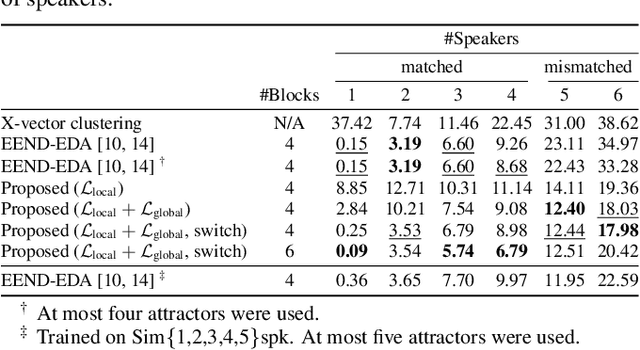
Attractor-based end-to-end diarization is achieving comparable accuracy to the carefully tuned conventional clustering-based methods on challenging datasets. However, the main drawback is that it cannot deal with the case where the number of speakers is larger than the one observed during training. This is because its speaker counting relies on supervised learning. In this work, we introduce an unsupervised clustering process embedded in the attractor-based end-to-end diarization. We first split a sequence of frame-wise embeddings into short subsequences and then perform attractor-based diarization for each subsequence. Given subsequence-wise diarization results, inter-subsequence speaker correspondence is obtained by unsupervised clustering of the vectors computed from the attractors from all the subsequences. This makes it possible to produce diarization results of a large number of speakers for the whole recording even if the number of output speakers for each subsequence is limited. Experimental results showed that our method could produce accurate diarization results of an unseen number of speakers. Our method achieved 11.84 %, 28.33 %, and 19.49 % on the CALLHOME, DIHARD II, and DIHARD III datasets, respectively, each of which is better than the conventional end-to-end diarization methods.
Semi-Supervised Training with Pseudo-Labeling for End-to-End Neural Diarization
Jun 09, 2021
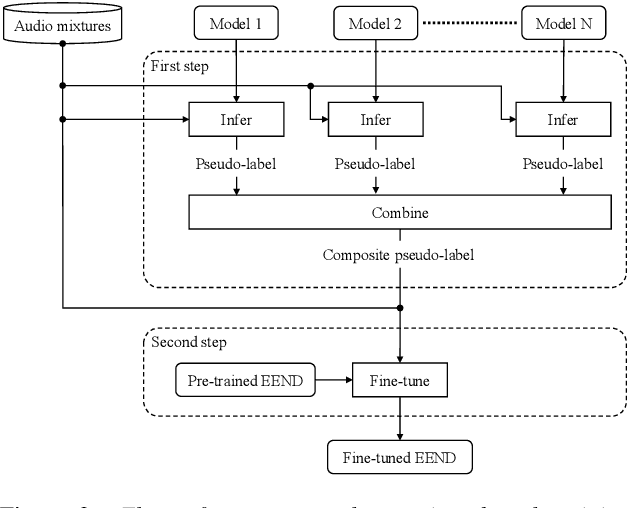
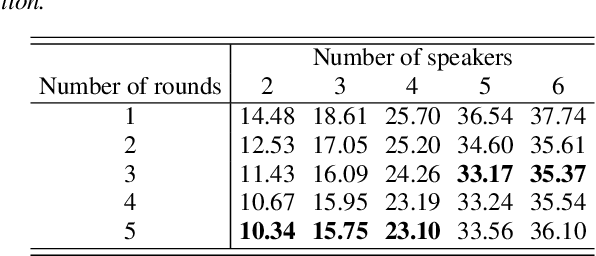
In this paper, we present a semi-supervised training technique using pseudo-labeling for end-to-end neural diarization (EEND). The EEND system has shown promising performance compared with traditional clustering-based methods, especially in the case of overlapping speech. However, to get a well-tuned model, EEND requires labeled data for all the joint speech activities of every speaker at each time frame in a recording. In this paper, we explore a pseudo-labeling approach that employs unlabeled data. First, we propose an iterative pseudo-label method for EEND, which trains the model using unlabeled data of a target condition. Then, we also propose a committee-based training method to improve the performance of EEND. To evaluate our proposed method, we conduct the experiments of model adaptation using labeled and unlabeled data. Experimental results on the CALLHOME dataset show that our proposed pseudo-label achieved a 37.4% relative diarization error rate reduction compared to a seed model. Moreover, we analyzed the results of semi-supervised adaptation with pseudo-labeling. We also show the effectiveness of our approach on the third DIHARD dataset.
End-to-End Speaker Diarization Conditioned on Speech Activity and Overlap Detection
Jun 08, 2021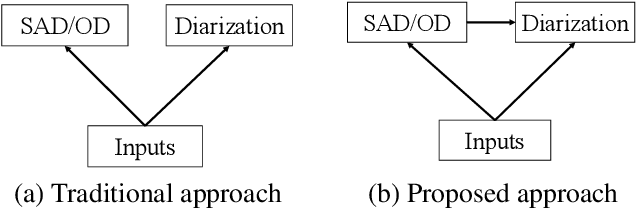
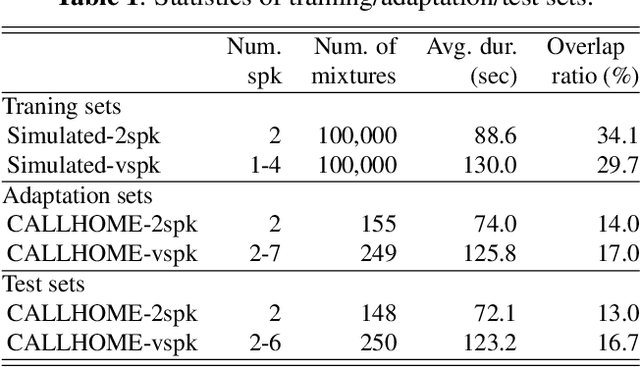
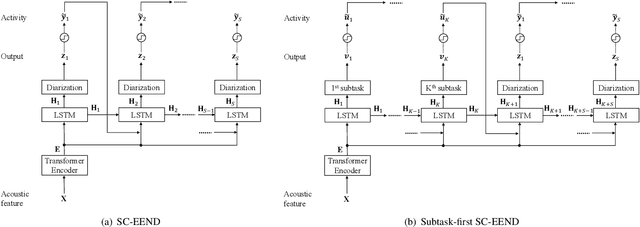
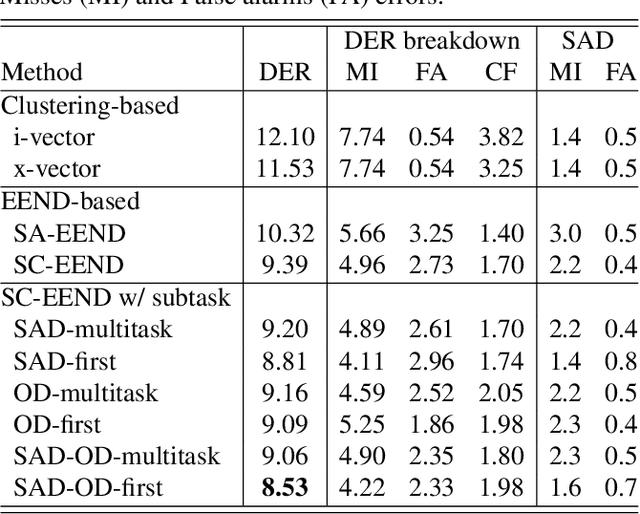
In this paper, we present a conditional multitask learning method for end-to-end neural speaker diarization (EEND). The EEND system has shown promising performance compared with traditional clustering-based methods, especially in the case of overlapping speech. In this paper, to further improve the performance of the EEND system, we propose a novel multitask learning framework that solves speaker diarization and a desired subtask while explicitly considering the task dependency. We optimize speaker diarization conditioned on speech activity and overlap detection that are subtasks of speaker diarization, based on the probabilistic chain rule. Experimental results show that our proposed method can leverage a subtask to effectively model speaker diarization, and outperforms conventional EEND systems in terms of diarization error rate.
* Accepted for SLT 2021
The Hitachi-JHU DIHARD III System: Competitive End-to-End Neural Diarization and X-Vector Clustering Systems Combined by DOVER-Lap
Feb 02, 2021
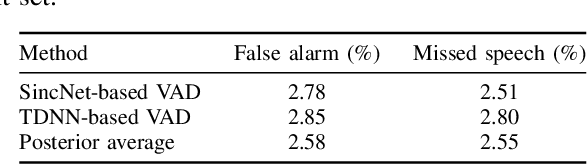


This paper provides a detailed description of the Hitachi-JHU system that was submitted to the Third DIHARD Speech Diarization Challenge. The system outputs the ensemble results of the five subsystems: two x-vector-based subsystems, two end-to-end neural diarization-based subsystems, and one hybrid subsystem. We refine each system and all five subsystems become competitive and complementary. After the DOVER-Lap based system combination, it achieved diarization error rates of 11.58 % and 14.09 % in Track 1 full and core, and 16.94 % and 20.01 % in Track 2 full and core, respectively. With their results, we won second place in all the tasks of the challenge.
Online End-to-End Neural Diarization Handling Overlapping Speech and Flexible Numbers of Speakers
Jan 21, 2021
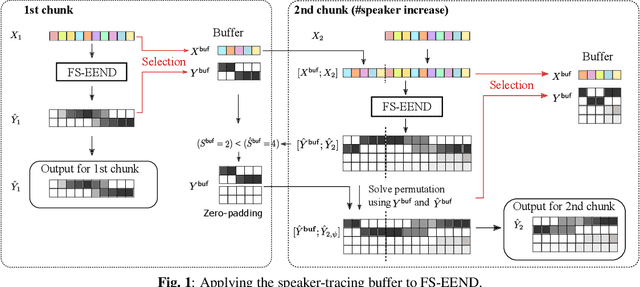


This paper proposes an online end-to-end diarization that can handle overlapping speech and flexible numbers of speakers. The end-to-end neural speaker diarization (EEND) model has already achieved significant improvement when compared with conventional clustering-based methods. However, the original EEND has two limitations: i) EEND does not perform well in online scenarios; ii) the number of speakers must be fixed in advance. This paper solves both problems by applying a modified extension of the speaker-tracing buffer method that deals with variable numbers of speakers. Experiments on CALLHOME and DIHARD II datasets show that the proposed online method achieves comparable performance to the offline EEND method. Compared with the state-of-the-art online method based on a fully supervised approach (UIS-RNN), the proposed method shows better performance on the DIHARD II dataset.