 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Channel End-to-End Neural Diarization with Distributed Microphones
Paper and Code
Oct 10, 2021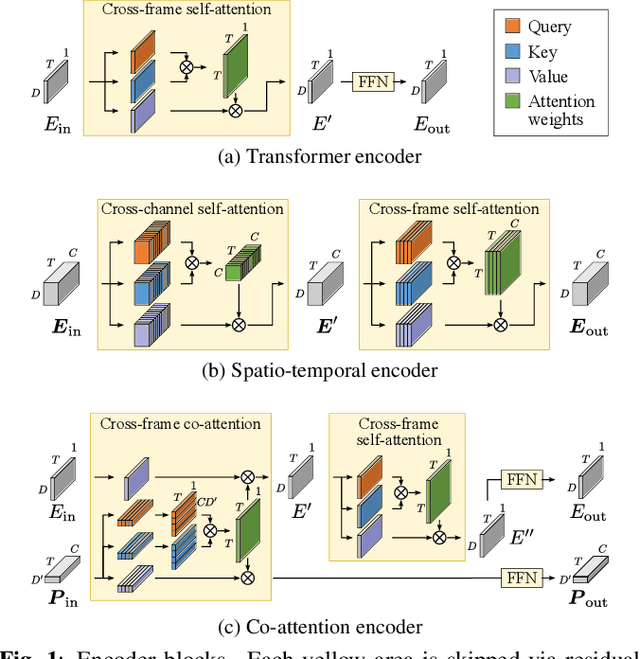

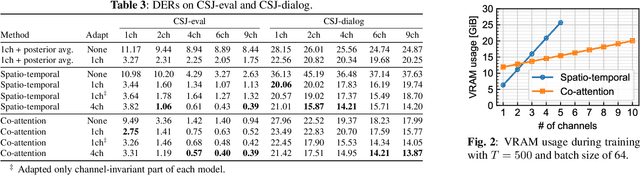
Recent progress on end-to-end neural diarization (EEND) has enabled overlap-aware speaker diarization with a single neural network. This paper proposes to enhance EEND by using multi-channel signals from distributed microphones. We replace Transformer encoders in EEND with two types of encoders that process a multi-channel input: spatio-temporal and co-attention encoders. Both are independent of the number and geometry of microphones and suitable for distributed microphone settings. We also propose a model adaptation method using only single-channel recordings. With simulated and real-recorded datasets, we demonstrated that the proposed method outperformed conventional EEND when a multi-channel input was given while maintaining comparable performance with a single-channel input. We also showed that the proposed method performed well even when spatial information is inoperative given multi-channel inputs, such as in hybrid meetings in which the utterances of multiple remote participants are played back from the same loudspeaker.