 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUpdating Only Encoders Prevents Catastrophic Forgetting of End-to-End ASR Models
Paper and Code
Jul 01, 2022
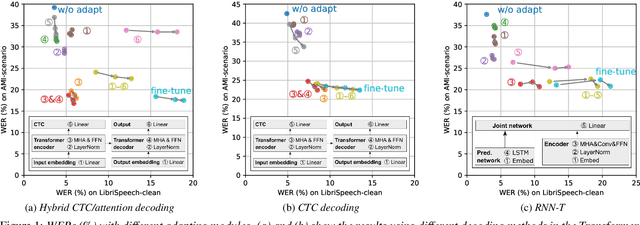
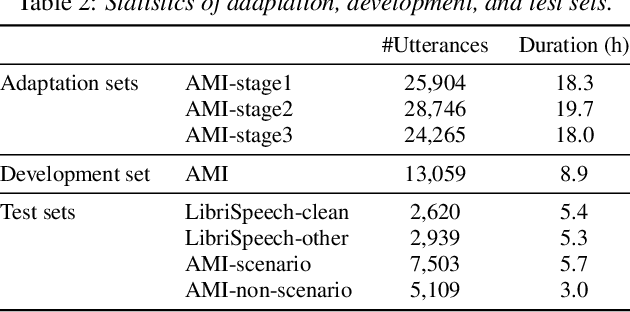
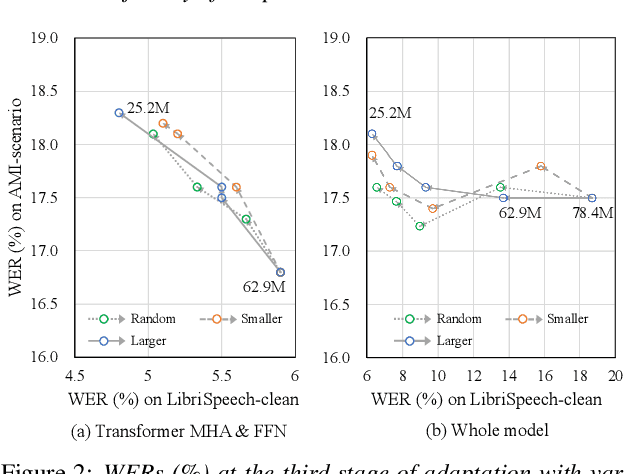
In this paper, we present an incremental domain adaptation technique to prevent catastrophic forgetting for an end-to-end automatic speech recognition (ASR) model. Conventional approaches require extra parameters of the same size as the model for optimization, and it is difficult to apply these approaches to end-to-end ASR models because they have a huge amount of parameters. To solve this problem, we first investigate which parts of end-to-end ASR models contribute to high accuracy in the target domain while preventing catastrophic forgetting. We conduct experiments on incremental domain adaptation from the LibriSpeech dataset to the AMI meeting corpus with two popular end-to-end ASR models and found that adapting only the linear layers of their encoders can prevent catastrophic forgetting. Then, on the basis of this finding, we develop an element-wise parameter selection focused on specific layers to further reduce the number of fine-tuning parameters. Experimental results show that our approach consistently prevents catastrophic forgetting compared to parameter selection from the whole model.