 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Hitachi-JHU DIHARD III System: Competitive End-to-End Neural Diarization and X-Vector Clustering Systems Combined by DOVER-Lap
Feb 02, 2021
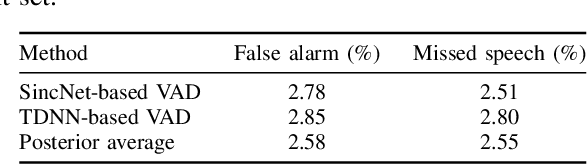


This paper provides a detailed description of the Hitachi-JHU system that was submitted to the Third DIHARD Speech Diarization Challenge. The system outputs the ensemble results of the five subsystems: two x-vector-based subsystems, two end-to-end neural diarization-based subsystems, and one hybrid subsystem. We refine each system and all five subsystems become competitive and complementary. After the DOVER-Lap based system combination, it achieved diarization error rates of 11.58 % and 14.09 % in Track 1 full and core, and 16.94 % and 20.01 % in Track 2 full and core, respectively. With their results, we won second place in all the tasks of the challenge.
HATSUKI : An anime character like robot figure platform with anime-style expressions and imitation learning based action generation
Mar 31, 2020


Japanese character figurines are popular and have pivot position in Otaku culture. Although numerous robots have been developed, less have focused on otaku-culture or on embodying the anime character figurine. Therefore, we take the first steps to bridge this gap by developing Hatsuki, which is a humanoid robot platform with anime based design. Hatsuki's novelty lies in aesthetic design, 2D facial expressions, and anime-style behaviors that allows it to deliver rich interaction experiences resembling anime-characters. We explain our design implementation process of Hatsuki, followed by our evaluations. In order to explore user impressions and opinions towards Hatsuki, we conducted a questionnaire in the world's largest anime-figurine event. The results indicate that participants were generally very satisfied with Hatsuki's design, and proposed various use case scenarios and deployment contexts for Hatsuki. The second evaluation focused on imitation learning, as such method can provide better interaction ability in the real world and generate rich, context-adaptive behavior in different situations. We made Hatsuki learn 11 actions, combining voice, facial expressions and motions, through neuron network based policy model with our proposed interface. Results show our approach was successfully able to generate the actions through self-organized contexts, which shows the potential for generalizing our approach in further actions under different contexts. Lastly, we present our future research direction for Hatsuki, and provide our conclusion.
CNN-based MultiChannel End-to-End Speech Recognition for everyday home environments
Nov 07, 2018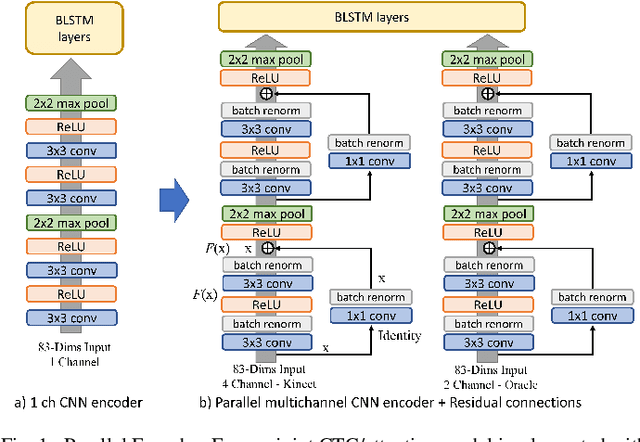

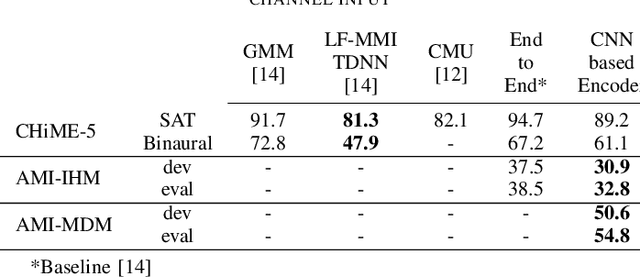
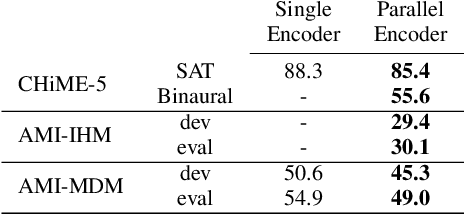
Casual conversations involving multiple speakers and noises from surrounding devices are part of everyday environments and pose challenges for automatic speech recognition systems. These challenges in speech recognition are target for the CHiME-5 challenge. In the present study, an attempt is made to overcome these challenges by employing a convolutional neural network (CNN)-based multichannel end-to-end speech recognition system. The system comprises an attention-based encoder-decoder neural network that directly generates a text as an output from a sound input. The mulitchannel CNN encoder, which uses residual connections and batch renormalization, is trained with augmented data, including white noise injection. The experimental results show that the word error rate (WER) was reduced by 11.9% absolute from the end-to-end baseline.
Weakly Supervised Deep Recurrent Neural Networks for Basic Dance Step Generation
Jul 03, 2018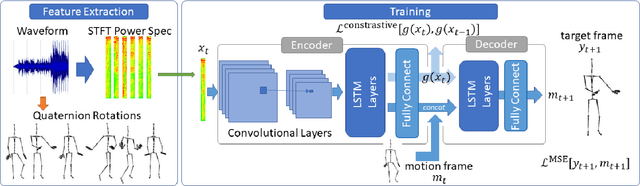
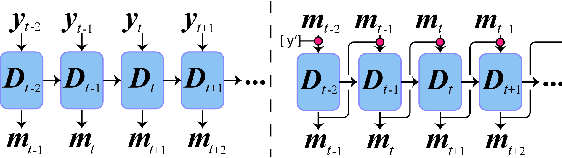
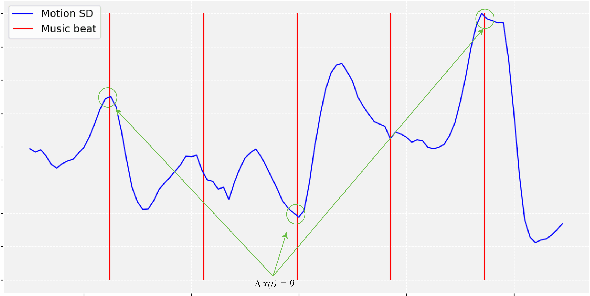
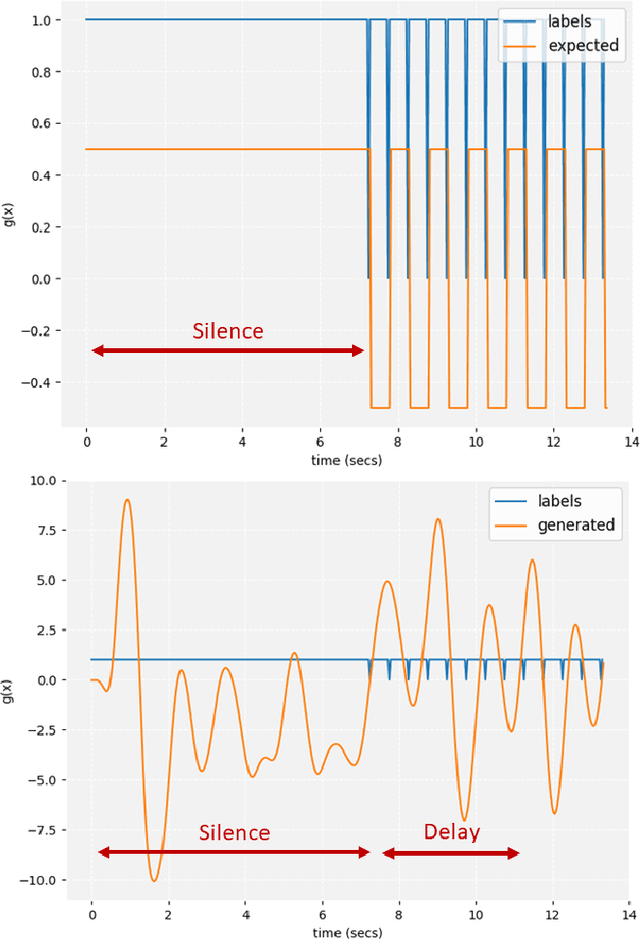
A deep recurrent neural network with audio input is applied to model basic dance steps. The proposed model employs multilayered Long Short-Term Memory (LSTM) layers and convolutional layers to process the audio power spectrum. Then, another deep LSTM layer decodes the target dance sequence. This end-to-end approach has an auto-conditioned decode configuration that reduces accumulation of feedback error. Experimental results demonstrate that, after training using a small dataset, the model generates basic dance steps with low cross entropy and maintains a motion beat F-measure score similar to that of a baseline dancer. In addition, we investigate the use of a contrastive cost function for music-motion regulation. This cost function targets motion direction and maps similarities between music frames. Experimental result demonstrate that the cost function improves the motion beat f-score.