 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEcologically-Constrained Task Arithmetic for Multi-Taxa Bioacoustic Classifiers Without Shared Data
May 05, 2026Training data for bioacoustics is scattered across taxa, regions, and institutions. Centralizing it all is often infeasible. We show that independently fine-tuned BEATs encoders can be composed into a unified 661-species classifier via task vector arithmetic without sharing data. We find that bioacoustic task vectors are near-orthogonal (cosine 0.01-0.09). Their separation aligns closely with spectral distribution distance, a gradient consistent with the acoustic niche hypothesis. This geometry makes simple averaging optimal while sign-conflict methods reduce accuracy by one to six percentage points. Composition also creates an asymmetric gap: species-rich groups lose accuracy relative to joint training while underrepresented taxa gain, a redistribution useful for equitable biodiversity monitoring. We verify linear mode connectivity across all taxonomic pairs, demonstrate zero-shot transfer to new regions, and identify domain negation as a boundary condition where composition fails. These results enable a collaborative paradigm for bioacoustics where institutions share only task vectors to assemble multi-taxa classifiers, preserving data privacy.
Unsupervised Single-Channel Audio Separation with Diffusion Source Priors
Dec 23, 2025Single-channel audio separation aims to separate individual sources from a single-channel mixture. Most existing methods rely on supervised learning with synthetically generated paired data. However, obtaining high-quality paired data in real-world scenarios is often difficult. This data scarcity can degrade model performance under unseen conditions and limit generalization ability. To this end, in this work, we approach this problem from an unsupervised perspective, framing it as a probabilistic inverse problem. Our method requires only diffusion priors trained on individual sources. Separation is then achieved by iteratively guiding an initial state toward the solution through reconstruction guidance. Importantly, we introduce an advanced inverse problem solver specifically designed for separation, which mitigates gradient conflicts caused by interference between the diffusion prior and reconstruction guidance during inverse denoising. This design ensures high-quality and balanced separation performance across individual sources. Additionally, we find that initializing the denoising process with an augmented mixture instead of pure Gaussian noise provides an informative starting point that significantly improves the final performance. To further enhance audio prior modeling, we design a novel time-frequency attention-based network architecture that demonstrates strong audio modeling capability. Collectively, these improvements lead to significant performance gains, as validated across speech-sound event, sound event, and speech separation tasks.
Observability-Aware Active Calibration of Multi-Sensor Extrinsics for Ground Robots via Online Trajectory Optimization
Jun 16, 2025Accurate calibration of sensor extrinsic parameters for ground robotic systems (i.e., relative poses) is crucial for ensuring spatial alignment and achieving high-performance perception. However, existing calibration methods typically require complex and often human-operated processes to collect data. Moreover, most frameworks neglect acoustic sensors, thereby limiting the associated systems' auditory perception capabilities. To alleviate these issues, we propose an observability-aware active calibration method for ground robots with multimodal sensors, including a microphone array, a LiDAR (exteroceptive sensors), and wheel encoders (proprioceptive sensors). Unlike traditional approaches, our method enables active trajectory optimization for online data collection and calibration, contributing to the development of more intelligent robotic systems. Specifically, we leverage the Fisher information matrix (FIM) to quantify parameter observability and adopt its minimum eigenvalue as an optimization metric for trajectory generation via B-spline curves. Through planning and replanning of robot trajectory online, the method enhances the observability of multi-sensor extrinsic parameters. The effectiveness and advantages of our method have been demonstrated through numerical simulations and real-world experiments. For the benefit of the community, we have also open-sourced our code and data at https://github.com/AISLAB-sustech/Multisensor-Calibration.
Multilingual Gloss-free Sign Language Translation: Towards Building a Sign Language Foundation Model
May 30, 2025Sign Language Translation (SLT) aims to convert sign language (SL) videos into spoken language text, thereby bridging the communication gap between the sign and the spoken community. While most existing works focus on translating a single sign language into a single spoken language (one-to-one SLT), leveraging multilingual resources could mitigate low-resource issues and enhance accessibility. However, multilingual SLT (MLSLT) remains unexplored due to language conflicts and alignment difficulties across SLs and spoken languages. To address these challenges, we propose a multilingual gloss-free model with dual CTC objectives for token-level SL identification and spoken text generation. Our model supports 10 SLs and handles one-to-one, many-to-one, and many-to-many SLT tasks, achieving competitive performance compared to state-of-the-art methods on three widely adopted benchmarks: multilingual SP-10, PHOENIX14T, and CSL-Daily.
Single-Channel Target Speech Extraction Utilizing Distance and Room Clues
May 20, 2025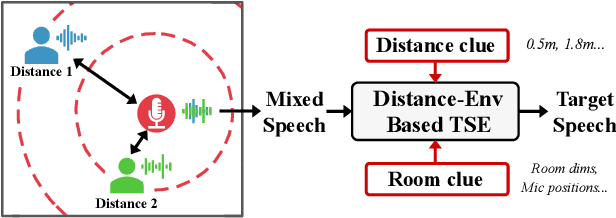
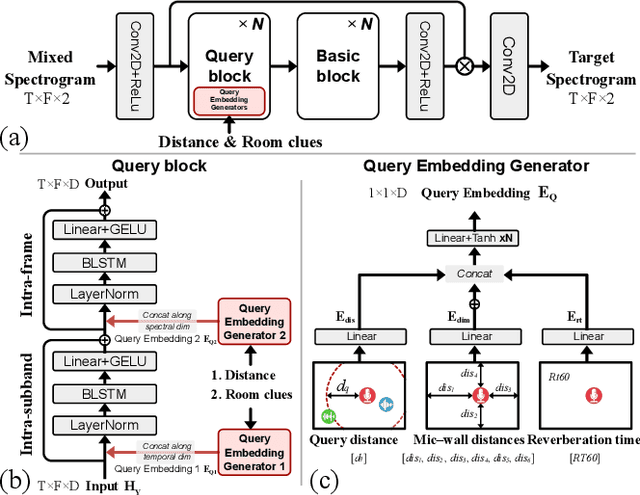
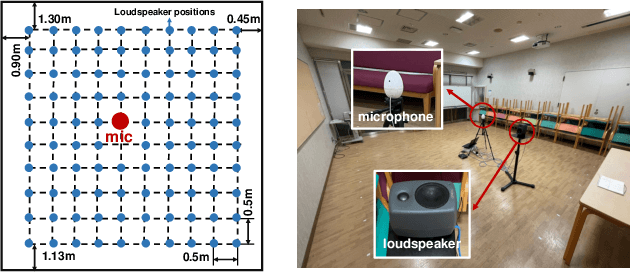
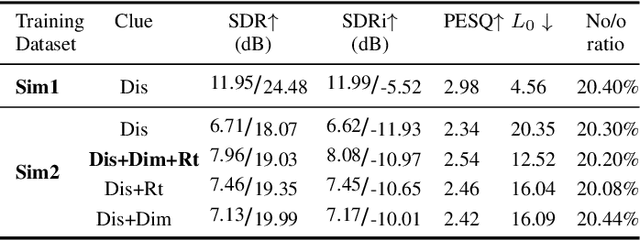
This paper aims to achieve single-channel target speech extraction (TSE) in enclosures utilizing distance clues and room information. Recent works have verified the feasibility of distance clues for the TSE task, which can imply the sound source's direct-to-reverberation ratio (DRR) and thus can be utilized for speech separation and TSE systems. However, such distance clue is significantly influenced by the room's acoustic characteristics, such as dimension and reverberation time, making it challenging for TSE systems that rely solely on distance clues to generalize across a variety of different rooms. To solve this, we suggest providing room environmental information (room dimensions and reverberation time) for distance-based TSE for better generalization capabilities. Especially, we propose a distance and environment-based TSE model in the time-frequency (TF) domain with learnable distance and room embedding. Results on both simulated and real collected datasets demonstrate its feasibility. Demonstration materials are available at https://runwushi.github.io/distance-room-demo-page/.
An Efficient GPU-based Implementation for Noise Robust Sound Source Localization
Apr 04, 2025



Robot audition, encompassing Sound Source Localization (SSL), Sound Source Separation (SSS), and Automatic Speech Recognition (ASR), enables robots and smart devices to acquire auditory capabilities similar to human hearing. Despite their wide applicability, processing multi-channel audio signals from microphone arrays in SSL involves computationally intensive matrix operations, which can hinder efficient deployment on Central Processing Units (CPUs), particularly in embedded systems with limited CPU resources. This paper introduces a GPU-based implementation of SSL for robot audition, utilizing the Generalized Singular Value Decomposition-based Multiple Signal Classification (GSVD-MUSIC), a noise-robust algorithm, within the HARK platform, an open-source software suite. For a 60-channel microphone array, the proposed implementation achieves significant performance improvements. On the Jetson AGX Orin, an embedded device powered by an NVIDIA GPU and ARM Cortex-A78AE v8.2 64-bit CPUs, we observe speedups of 4645.1x for GSVD calculations and 8.8x for the SSL module, while speedups of 2223.4x for GSVD calculation and 8.95x for the entire SSL module on a server configured with an NVIDIA A100 GPU and AMD EPYC 7352 CPUs, making real-time processing feasible for large-scale microphone arrays and providing ample capacity for real-time processing of potential subsequent machine learning or deep learning tasks.
Bird Vocalization Embedding Extraction Using Self-Supervised Disentangled Representation Learning
Dec 28, 2024



This paper addresses the extraction of the bird vocalization embedding from the whole song level using disentangled representation learning (DRL). Bird vocalization embeddings are necessary for large-scale bioacoustic tasks, and self-supervised methods such as Variational Autoencoder (VAE) have shown their performance in extracting such low-dimensional embeddings from vocalization segments on the note or syllable level. To extend the processing level to the entire song instead of cutting into segments, this paper regards each vocalization as the generalized and discriminative part and uses two encoders to learn these two parts. The proposed method is evaluated on the Great Tits dataset according to the clustering performance, and the results outperform the compared pre-trained models and vanilla VAE. Finally, this paper analyzes the informative part of the embedding, further compresses its dimension, and explains the disentangled performance of bird vocalizations.
Distance Based Single-Channel Target Speech Extraction
Dec 28, 2024



This paper aims to achieve single-channel target speech extraction (TSE) in enclosures by solely utilizing distance information. This is the first work that utilizes only distance cues without using speaker physiological information for single-channel TSE. Inspired by recent single-channel Distance-based separation and extraction methods, we introduce a novel model that efficiently fuses distance information with time-frequency (TF) bins for TSE. Experimental results in both single-room and multi-room scenarios demonstrate the feasibility and effectiveness of our approach. This method can also be employed to estimate the distances of different speakers in mixed speech. Online demos are available at https://runwushi.github.io/distance-demo-page.
Improvement in Sign Language Translation Using Text CTC Alignment
Dec 12, 2024
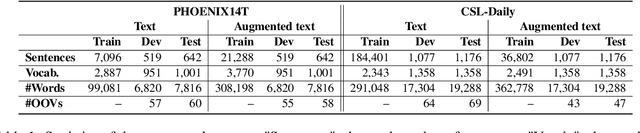
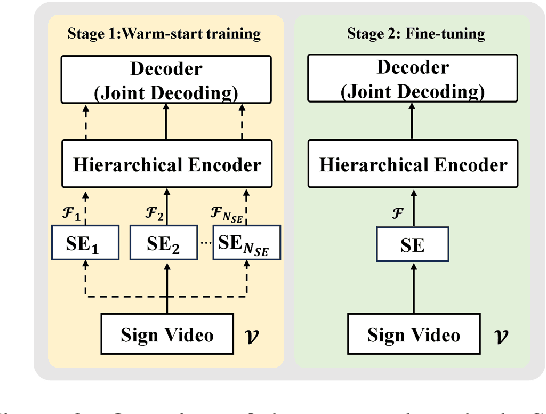
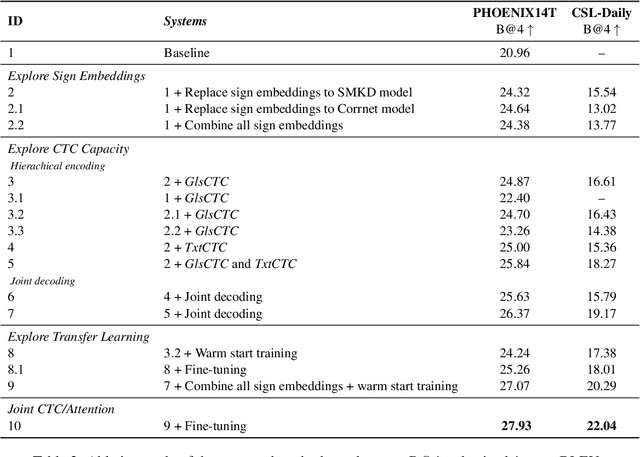
Current sign language translation (SLT) approaches often rely on gloss-based supervision with Connectionist Temporal Classification (CTC), limiting their ability to handle non-monotonic alignments between sign language video and spoken text. In this work, we propose a novel method combining joint CTC/Attention and transfer learning. The joint CTC/Attention introduces hierarchical encoding and integrates CTC with the attention mechanism during decoding, effectively managing both monotonic and non-monotonic alignments. Meanwhile, transfer learning helps bridge the modality gap between vision and language in SLT. Experimental results on two widely adopted benchmarks, RWTH-PHOENIX-Weather 2014 T and CSL-Daily, show that our method achieves results comparable to state-of-the-art and outperforms the pure-attention baseline. Additionally, this work opens a new door for future research into gloss-free SLT using text-based CTC alignment.
UAV-Enhanced Combination to Application: Comprehensive Analysis and Benchmarking of a Human Detection Dataset for Disaster Scenarios
Aug 09, 2024



Unmanned aerial vehicles (UAVs) have revolutionized search and rescue (SAR) operations, but the lack of specialized human detection datasets for training machine learning models poses a significant challenge.To address this gap, this paper introduces the Combination to Application (C2A) dataset, synthesized by overlaying human poses onto UAV-captured disaster scenes. Through extensive experimentation with state-of-the-art detection models, we demonstrate that models fine-tuned on the C2A dataset exhibit substantial performance improvements compared to those pre-trained on generic aerial datasets. Furthermore, we highlight the importance of combining the C2A dataset with general human datasets to achieve optimal performance and generalization across various scenarios. This points out the crucial need for a tailored dataset to enhance the effectiveness of SAR operations. Our contributions also include developing dataset creation pipeline and integrating diverse human poses and disaster scenes information to assess the severity of disaster scenarios. Our findings advocate for future developments, to ensure that SAR operations benefit from the most realistic and effective AI-assisted interventions possible.