 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEcologically-Constrained Task Arithmetic for Multi-Taxa Bioacoustic Classifiers Without Shared Data
May 05, 2026Training data for bioacoustics is scattered across taxa, regions, and institutions. Centralizing it all is often infeasible. We show that independently fine-tuned BEATs encoders can be composed into a unified 661-species classifier via task vector arithmetic without sharing data. We find that bioacoustic task vectors are near-orthogonal (cosine 0.01-0.09). Their separation aligns closely with spectral distribution distance, a gradient consistent with the acoustic niche hypothesis. This geometry makes simple averaging optimal while sign-conflict methods reduce accuracy by one to six percentage points. Composition also creates an asymmetric gap: species-rich groups lose accuracy relative to joint training while underrepresented taxa gain, a redistribution useful for equitable biodiversity monitoring. We verify linear mode connectivity across all taxonomic pairs, demonstrate zero-shot transfer to new regions, and identify domain negation as a boundary condition where composition fails. These results enable a collaborative paradigm for bioacoustics where institutions share only task vectors to assemble multi-taxa classifiers, preserving data privacy.
Unsupervised Single-Channel Audio Separation with Diffusion Source Priors
Dec 23, 2025Single-channel audio separation aims to separate individual sources from a single-channel mixture. Most existing methods rely on supervised learning with synthetically generated paired data. However, obtaining high-quality paired data in real-world scenarios is often difficult. This data scarcity can degrade model performance under unseen conditions and limit generalization ability. To this end, in this work, we approach this problem from an unsupervised perspective, framing it as a probabilistic inverse problem. Our method requires only diffusion priors trained on individual sources. Separation is then achieved by iteratively guiding an initial state toward the solution through reconstruction guidance. Importantly, we introduce an advanced inverse problem solver specifically designed for separation, which mitigates gradient conflicts caused by interference between the diffusion prior and reconstruction guidance during inverse denoising. This design ensures high-quality and balanced separation performance across individual sources. Additionally, we find that initializing the denoising process with an augmented mixture instead of pure Gaussian noise provides an informative starting point that significantly improves the final performance. To further enhance audio prior modeling, we design a novel time-frequency attention-based network architecture that demonstrates strong audio modeling capability. Collectively, these improvements lead to significant performance gains, as validated across speech-sound event, sound event, and speech separation tasks.
Single-Channel Target Speech Extraction Utilizing Distance and Room Clues
May 20, 2025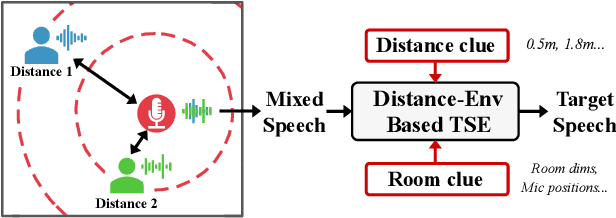
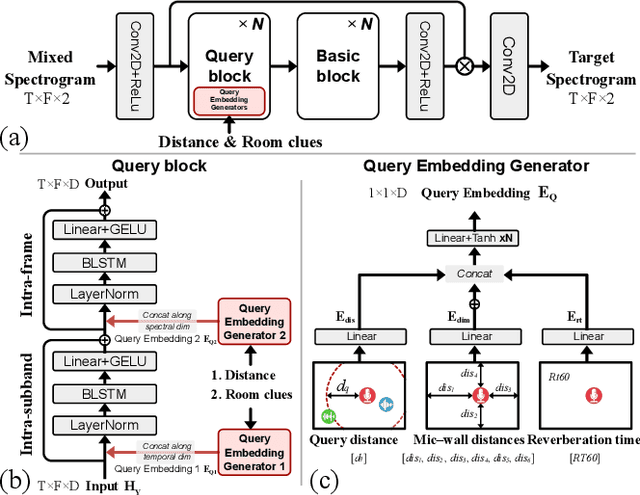
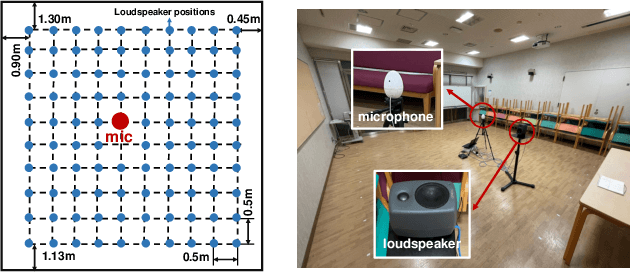
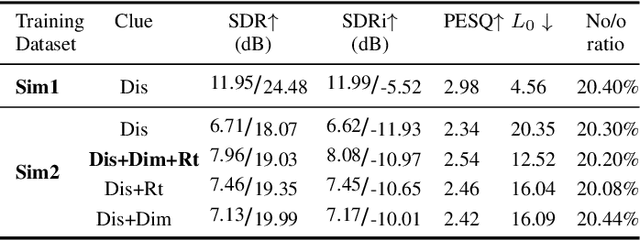
This paper aims to achieve single-channel target speech extraction (TSE) in enclosures utilizing distance clues and room information. Recent works have verified the feasibility of distance clues for the TSE task, which can imply the sound source's direct-to-reverberation ratio (DRR) and thus can be utilized for speech separation and TSE systems. However, such distance clue is significantly influenced by the room's acoustic characteristics, such as dimension and reverberation time, making it challenging for TSE systems that rely solely on distance clues to generalize across a variety of different rooms. To solve this, we suggest providing room environmental information (room dimensions and reverberation time) for distance-based TSE for better generalization capabilities. Especially, we propose a distance and environment-based TSE model in the time-frequency (TF) domain with learnable distance and room embedding. Results on both simulated and real collected datasets demonstrate its feasibility. Demonstration materials are available at https://runwushi.github.io/distance-room-demo-page/.
Distance Based Single-Channel Target Speech Extraction
Dec 28, 2024



This paper aims to achieve single-channel target speech extraction (TSE) in enclosures by solely utilizing distance information. This is the first work that utilizes only distance cues without using speaker physiological information for single-channel TSE. Inspired by recent single-channel Distance-based separation and extraction methods, we introduce a novel model that efficiently fuses distance information with time-frequency (TF) bins for TSE. Experimental results in both single-room and multi-room scenarios demonstrate the feasibility and effectiveness of our approach. This method can also be employed to estimate the distances of different speakers in mixed speech. Online demos are available at https://runwushi.github.io/distance-demo-page.
Bird Vocalization Embedding Extraction Using Self-Supervised Disentangled Representation Learning
Dec 28, 2024



This paper addresses the extraction of the bird vocalization embedding from the whole song level using disentangled representation learning (DRL). Bird vocalization embeddings are necessary for large-scale bioacoustic tasks, and self-supervised methods such as Variational Autoencoder (VAE) have shown their performance in extracting such low-dimensional embeddings from vocalization segments on the note or syllable level. To extend the processing level to the entire song instead of cutting into segments, this paper regards each vocalization as the generalized and discriminative part and uses two encoders to learn these two parts. The proposed method is evaluated on the Great Tits dataset according to the clustering performance, and the results outperform the compared pre-trained models and vanilla VAE. Finally, this paper analyzes the informative part of the embedding, further compresses its dimension, and explains the disentangled performance of bird vocalizations.