 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-Channel Target Speech Extraction Utilizing Distance and Room Clues
May 20, 2025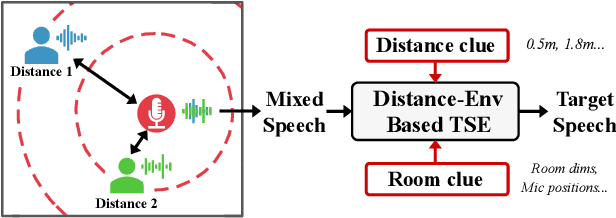
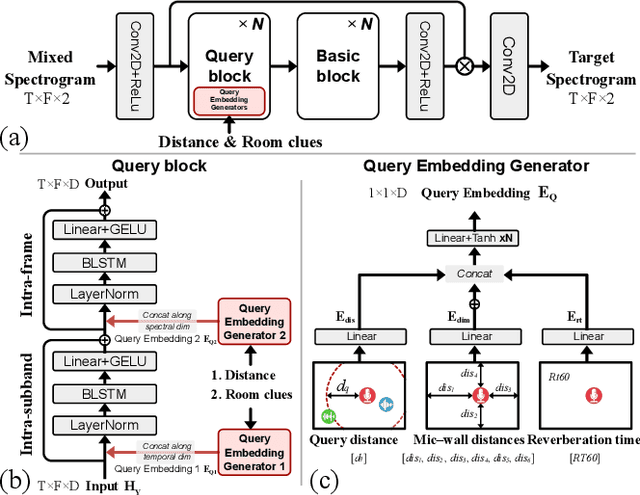
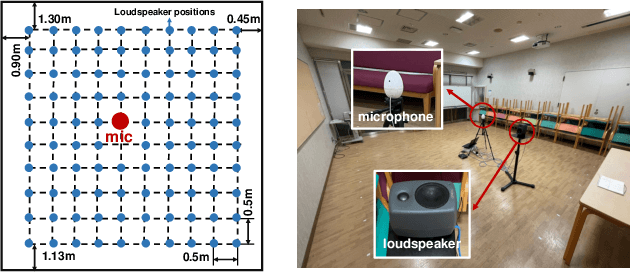
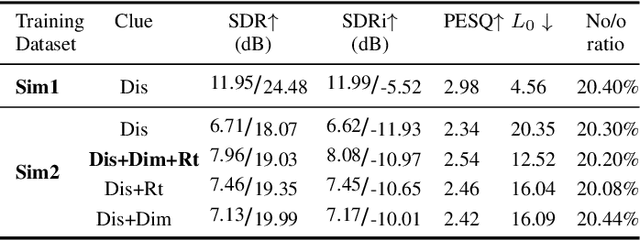
This paper aims to achieve single-channel target speech extraction (TSE) in enclosures utilizing distance clues and room information. Recent works have verified the feasibility of distance clues for the TSE task, which can imply the sound source's direct-to-reverberation ratio (DRR) and thus can be utilized for speech separation and TSE systems. However, such distance clue is significantly influenced by the room's acoustic characteristics, such as dimension and reverberation time, making it challenging for TSE systems that rely solely on distance clues to generalize across a variety of different rooms. To solve this, we suggest providing room environmental information (room dimensions and reverberation time) for distance-based TSE for better generalization capabilities. Especially, we propose a distance and environment-based TSE model in the time-frequency (TF) domain with learnable distance and room embedding. Results on both simulated and real collected datasets demonstrate its feasibility. Demonstration materials are available at https://runwushi.github.io/distance-room-demo-page/.
UAV-Enhanced Combination to Application: Comprehensive Analysis and Benchmarking of a Human Detection Dataset for Disaster Scenarios
Aug 09, 2024



Unmanned aerial vehicles (UAVs) have revolutionized search and rescue (SAR) operations, but the lack of specialized human detection datasets for training machine learning models poses a significant challenge.To address this gap, this paper introduces the Combination to Application (C2A) dataset, synthesized by overlaying human poses onto UAV-captured disaster scenes. Through extensive experimentation with state-of-the-art detection models, we demonstrate that models fine-tuned on the C2A dataset exhibit substantial performance improvements compared to those pre-trained on generic aerial datasets. Furthermore, we highlight the importance of combining the C2A dataset with general human datasets to achieve optimal performance and generalization across various scenarios. This points out the crucial need for a tailored dataset to enhance the effectiveness of SAR operations. Our contributions also include developing dataset creation pipeline and integrating diverse human poses and disaster scenes information to assess the severity of disaster scenarios. Our findings advocate for future developments, to ensure that SAR operations benefit from the most realistic and effective AI-assisted interventions possible.
SALAD: Smart AI Language Assistant Daily
Feb 13, 2024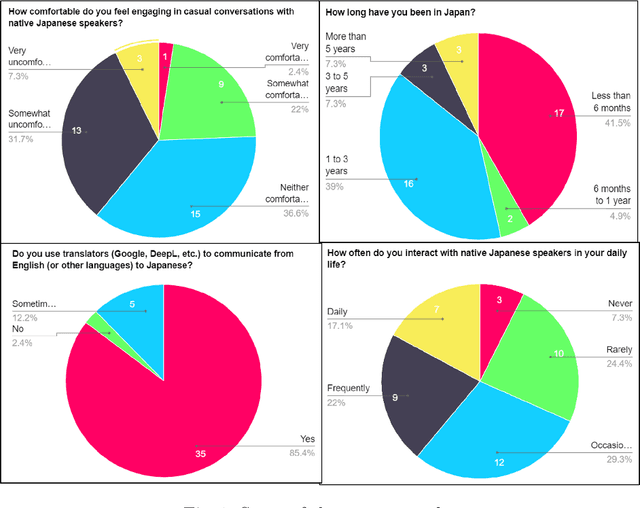
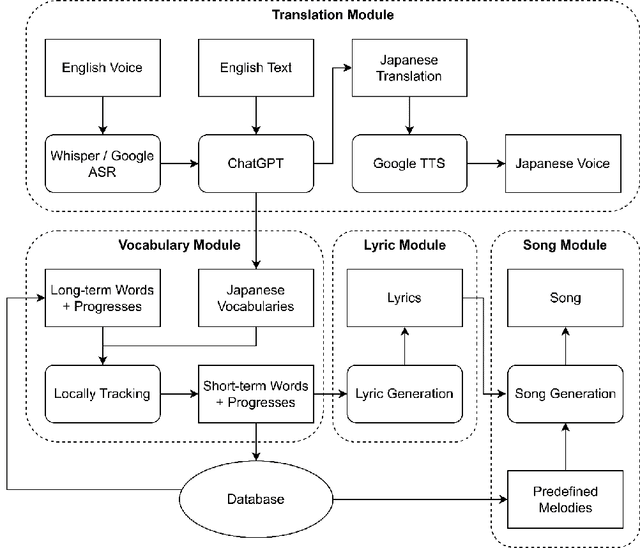

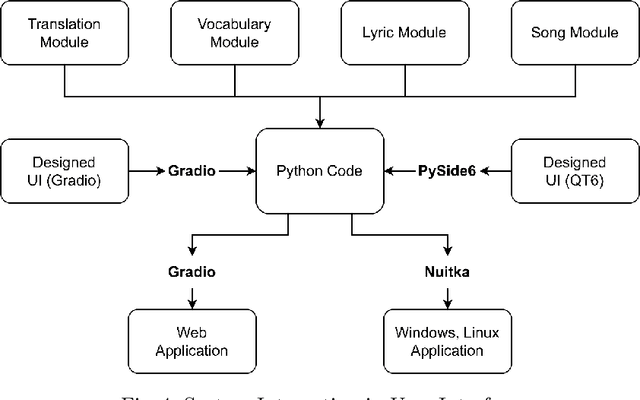
SALAD is an AI-driven language-learning application designed to help foreigners learn Japanese. It offers translations in Kanji-Kana-Romaji, speech recognition, translated audio, vocabulary tracking, grammar explanations, and songs generated from newly learned words. The app targets beginners and intermediate learners, aiming to make language acquisition more accessible and enjoyable. SALAD uses daily translations to enhance fluency and comfort in communication with native speakers. The primary objectives include effective Japanese language learning, user engagement, and progress tracking. A survey by us found that 39% of foreigners in Japan face discomfort in conversations with Japanese speakers. Over 60% of foreigners expressed confidence in SALAD's ability to enhance their Japanese language skills. The app uses large language models, speech recognition, and diffusion models to bridge the language gap and foster a more inclusive community in Japan.
From Blurry to Brilliant Detection: YOLOv5-Based Aerial Object Detection with Super Resolution
Jan 26, 2024The demand for accurate object detection in aerial imagery has surged with the widespread use of drones and satellite technology. Traditional object detection models, trained on datasets biased towards large objects, struggle to perform optimally in aerial scenarios where small, densely clustered objects are prevalent. To address this challenge, we present an innovative approach that combines super-resolution and an adapted lightweight YOLOv5 architecture. We employ a range of datasets, including VisDrone-2023, SeaDroneSee, VEDAI, and NWPU VHR-10, to evaluate our model's performance. Our Super Resolved YOLOv5 architecture features Transformer encoder blocks, allowing the model to capture global context and context information, leading to improved detection results, especially in high-density, occluded conditions. This lightweight model not only delivers improved accuracy but also ensures efficient resource utilization, making it well-suited for real-time applications. Our experimental results demonstrate the model's superior performance in detecting small and densely clustered objects, underlining the significance of dataset choice and architectural adaptation for this specific task. In particular, the method achieves 52.5% mAP on VisDrone, exceeding top prior works. This approach promises to significantly advance object detection in aerial imagery, contributing to more accurate and reliable results in a variety of real-world applications.