 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan all variations within the unified mask-based beamformer framework achieve identical peak extraction performance?
Jul 22, 2024This study investigates mask-based beamformers (BFs), which estimate filters for target sound extraction (TSE) using time-frequency masks. Although multiple mask-based BFs have been proposed, no consensus has been established on the best one for target-extracting performance. Previously, we found that maximum signal-to-noise ratio and minimum mean square error (MSE) BFs can achieve the same extraction performance as the theoretical upper-bound performance, with each BF containing a different optimal mask. However, these remarkable findings left two issues unsolved: only two BFs were covered, excluding the minimum variance distortionless response BF; and ideal scaling (IS) was employed to ideally adjust the output scale, which is not applicable to realistic scenarios. To address these coverage and scaling issues, this study proposes a unified framework for mask-based BFs comprising two processes: filter estimation that can cover all BFs and scaling applicable to realistic scenarios by employing a mask to generate a scaling reference. We also propose a methodology to enumerate all possible BFs and derive 12 variations. Optimal masks for both processes are obtained by minimizing the MSE between the target and BF output. The experimental results using the CHiME-4 dataset suggested that 1) all 12 variations can achieve the theoretical upper-bound performance, and 2) mask-based scaling can behave as IS. These results can be explained by considering the practical parameter count of the masks. These findings contribute to 1) designing a TSE system, 2) estimating the extraction performance of a BF, and 3) improving scaling accuracy combined with mask-based scaling. The contributions also apply to TSE methods based on independent component analysis, as the unified framework covers them too.
Online Similarity-and-Independence-Aware Beamformer for Low-latency Target Sound Extraction
Dec 27, 2023



This study describes an online target sound extraction (TSE) process, derived from the iterative batch algorithm using the similarity-and-independence-aware beamformer (SIBF), to achieve both latency reduction and extraction accuracy maintenance. The SIBF is a linear method that estimates the target more accurately compared with a reference, an approximate magnitude spectrogram of the target. Evidently, deriving the online algorithm from the iterative batch algorithm reduces the latency of the SIBF; however, this process presents two challenges: 1) the derivation may degrade the accuracy, and 2) the conventional post-process, meant for scaling the estimated target, may increase the accuracy gap between the two algorithms. To maintain the best possible accuracy, herein, an approach that minimizes this gap during post-processing is adopted, and a novel scaling method based on the single-channel Wiener filter (SWF-based scaling) is proposed. To improve the accuracy further, the time-frequency-varying variance generalized Gaussian (TV GG) distribution is employed as a source model to represent the joint probability between the target and reference. Thus, experiments using the CHiME-3 dataset confirm that 1) the online algorithm reduces latency; 2) SWF-based scaling eliminates the gap between the two algorithms while improving the accuracy; 3) TV GG model achieves the best accuracy when it corresponds to the Laplacian model; and 4) our online SIBF outperforms the conventional linear TSE, including the minimum mean square error beamformer. These findings can contribute to the fields of beamforming and blind source separation.
Is the Ideal Ratio Mask Really the Best? -- Exploring the Best Extraction Performance and Optimal Mask of Mask-based Beamformers
Sep 21, 2023This study investigates mask-based beamformers (BFs), which estimate filters to extract target speech using time-frequency masks. Although several BF methods have been proposed, the following aspects are yet to be comprehensively investigated. 1) Which BF can provide the best extraction performance in terms of the closeness of the BF output to the target speech? 2) Is the optimal mask for the best performance common for all BFs? 3) Is the ideal ratio mask (IRM) identical to the optimal mask? Accordingly, we investigate these issues considering four mask-based BFs: the maximum signal-to-noise ratio BF, two variants of this, and the multichannel Wiener filter (MWF) BF. To obtain the optimal mask corresponding to the peak performance for each BF, we employ an approach that minimizes the mean square error between the BF output and target speech for each utterance. Via the experiments with the CHiME-3 dataset, we verify that the four BFs have the same peak performance as the upper bound provided by the ideal MWF BF, whereas the optimal mask depends on the adopted BF and differs from the IRM. These observations differ from the conventional idea that the optimal mask is common for all BFs and that peak performance differs for each BF. Hence, this study contributes to the design of mask-based BFs.
Similarity-and-Independence-Aware Beamformer with Iterative Casting and Boost Start for Target Source Extraction Using Reference
Oct 18, 2021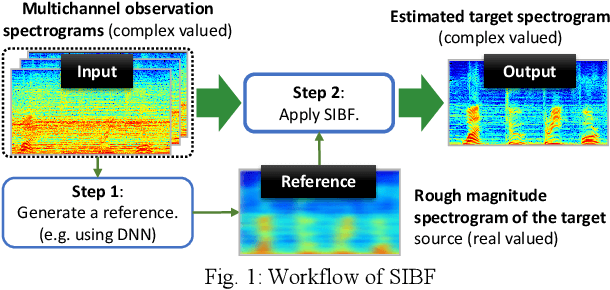
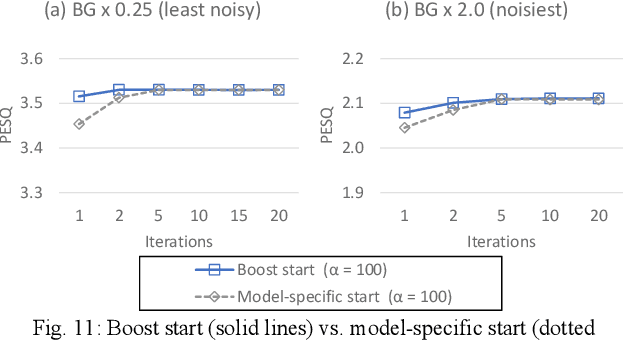

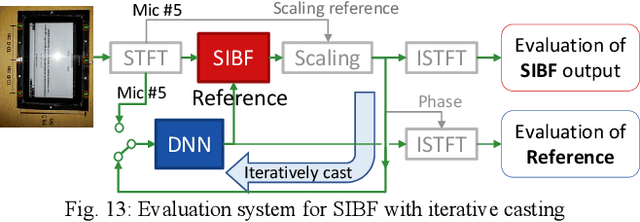
Target source extraction is significant for improving human speech intelligibility and the speech recognition performance of computers. This study describes a method for target source extraction, called the similarity-and-independence-aware beamformer (SIBF). The SIBF extracts the target source using a rough magnitude spectrogram as the reference signal. The advantage of the SIBF is that it can obtain a more accurate signal than the spectrogram generated by target-enhancing methods such as speech enhancement based on deep neural networks. For the extraction, we extend the framework of deflationary independent component analysis (ICA) by considering the similarities between the reference and extracted target sources, in addition to the mutual independence of all the potential sources. To solve the extraction problem by maximum-likelihood estimation, we introduce three source models that can reflect the similarities. The major contributions of this study are as follows. First, the extraction performance is improved using two methods, namely boost start for faster convergence and iterative casting for generating a more accurate reference. The effectiveness of these methods is verified through experiments using the CHiME3 dataset. Second, a concept of a fixed point pertaining to accuracy is developed. This concept facilitates understanding the relationship between the reference and SIBF output in terms of accuracy. Third, a unified formulation of the SIBF and mask-based beamformer is realized to apply the expertise of conventional BFs to the SIBF. The findings of this study can also improve the performance of the SIBF and promote research on ICA and conventional beamformers. Index Terms: beamformer, independent component analysis, source separation, speech enhancement, target source extraction