 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimilarity-and-Independence-Aware Beamformer with Iterative Casting and Boost Start for Target Source Extraction Using Reference
Paper and Code
Oct 18, 2021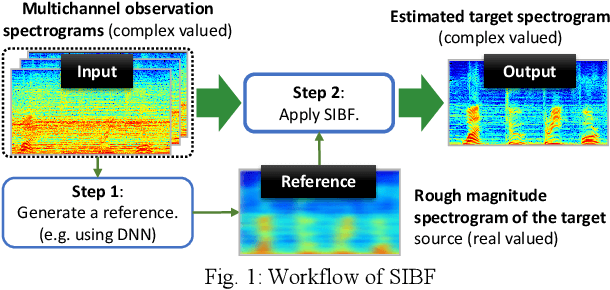
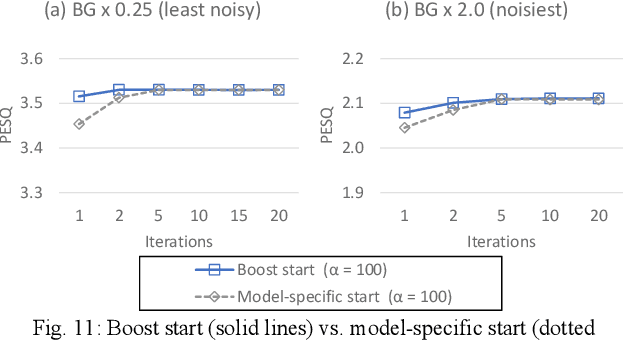

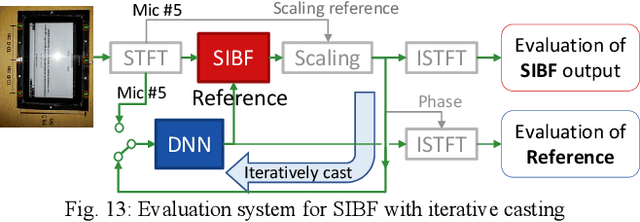
Target source extraction is significant for improving human speech intelligibility and the speech recognition performance of computers. This study describes a method for target source extraction, called the similarity-and-independence-aware beamformer (SIBF). The SIBF extracts the target source using a rough magnitude spectrogram as the reference signal. The advantage of the SIBF is that it can obtain a more accurate signal than the spectrogram generated by target-enhancing methods such as speech enhancement based on deep neural networks. For the extraction, we extend the framework of deflationary independent component analysis (ICA) by considering the similarities between the reference and extracted target sources, in addition to the mutual independence of all the potential sources. To solve the extraction problem by maximum-likelihood estimation, we introduce three source models that can reflect the similarities. The major contributions of this study are as follows. First, the extraction performance is improved using two methods, namely boost start for faster convergence and iterative casting for generating a more accurate reference. The effectiveness of these methods is verified through experiments using the CHiME3 dataset. Second, a concept of a fixed point pertaining to accuracy is developed. This concept facilitates understanding the relationship between the reference and SIBF output in terms of accuracy. Third, a unified formulation of the SIBF and mask-based beamformer is realized to apply the expertise of conventional BFs to the SIBF. The findings of this study can also improve the performance of the SIBF and promote research on ICA and conventional beamformers. Index Terms: beamformer, independent component analysis, source separation, speech enhancement, target source extraction