 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient GPU-based Implementation for Noise Robust Sound Source Localization
Apr 04, 2025



Robot audition, encompassing Sound Source Localization (SSL), Sound Source Separation (SSS), and Automatic Speech Recognition (ASR), enables robots and smart devices to acquire auditory capabilities similar to human hearing. Despite their wide applicability, processing multi-channel audio signals from microphone arrays in SSL involves computationally intensive matrix operations, which can hinder efficient deployment on Central Processing Units (CPUs), particularly in embedded systems with limited CPU resources. This paper introduces a GPU-based implementation of SSL for robot audition, utilizing the Generalized Singular Value Decomposition-based Multiple Signal Classification (GSVD-MUSIC), a noise-robust algorithm, within the HARK platform, an open-source software suite. For a 60-channel microphone array, the proposed implementation achieves significant performance improvements. On the Jetson AGX Orin, an embedded device powered by an NVIDIA GPU and ARM Cortex-A78AE v8.2 64-bit CPUs, we observe speedups of 4645.1x for GSVD calculations and 8.8x for the SSL module, while speedups of 2223.4x for GSVD calculation and 8.95x for the entire SSL module on a server configured with an NVIDIA A100 GPU and AMD EPYC 7352 CPUs, making real-time processing feasible for large-scale microphone arrays and providing ample capacity for real-time processing of potential subsequent machine learning or deep learning tasks.
Inter-Feature-Map Differential Coding of Surveillance Video
Nov 01, 2024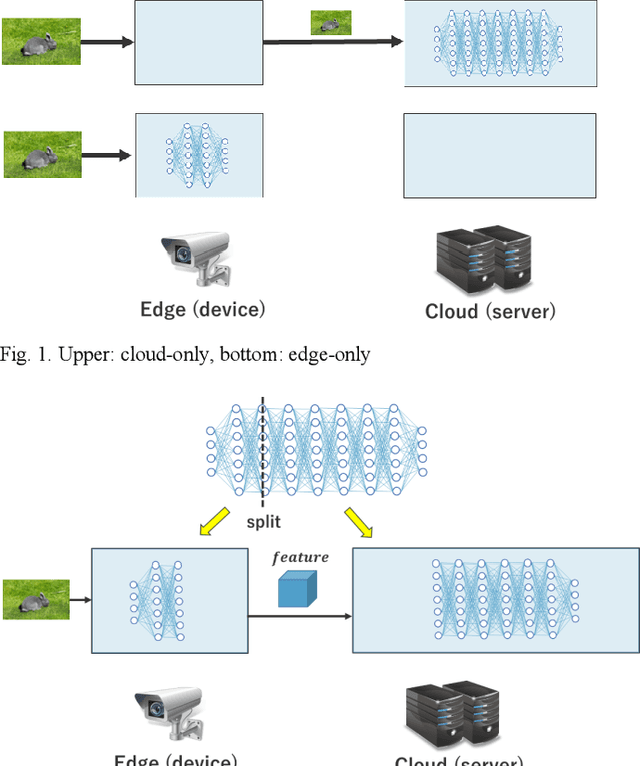
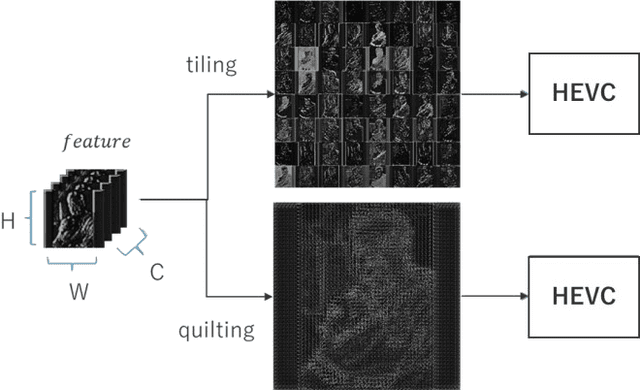
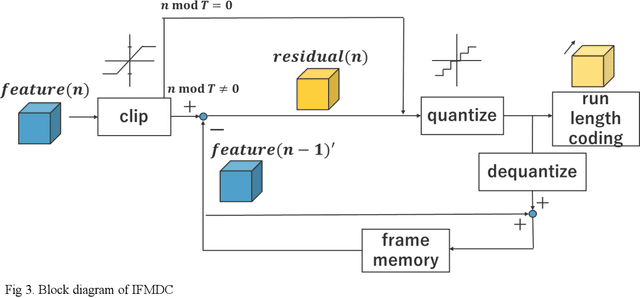
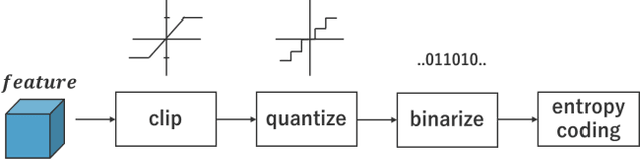
In Collaborative Intelligence, a deep neural network (DNN) is partitioned and deployed at the edge and the cloud for bandwidth saving and system optimization. When a model input is an image, it has been confirmed that the intermediate feature map, the output from the edge, can be smaller than the input data size. However, its effectiveness has not been reported when the input is a video. In this study, we propose a method to compress the feature map of surveillance videos by applying inter-feature-map differential coding (IFMDC). IFMDC shows a compression ratio comparable to, or better than, HEVC to the input video in the case of small accuracy reduction. Our method is especially effective for videos that are sensitive to image quality degradation when HEVC is applied
* \c{opyright} 2022 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
Test-time Adaptation Meets Image Enhancement: Improving Accuracy via Uncertainty-aware Logit Switching
Mar 26, 2024



Deep neural networks have achieved remarkable success in a variety of computer vision applications. However, there is a problem of degrading accuracy when the data distribution shifts between training and testing. As a solution of this problem, Test-time Adaptation~(TTA) has been well studied because of its practicality. Although TTA methods increase accuracy under distribution shift by updating the model at test time, using high-uncertainty predictions is known to degrade accuracy. Since the input image is the root of the distribution shift, we incorporate a new perspective on enhancing the input image into TTA methods to reduce the prediction's uncertainty. We hypothesize that enhancing the input image reduces prediction's uncertainty and increase the accuracy of TTA methods. On the basis of our hypothesis, we propose a novel method: Test-time Enhancer and Classifier Adaptation~(TECA). In TECA, the classification model is combined with the image enhancement model that transforms input images into recognition-friendly ones, and these models are updated by existing TTA methods. Furthermore, we found that the prediction from the enhanced image does not always have lower uncertainty than the prediction from the original image. Thus, we propose logit switching, which compares the uncertainty measure of these predictions and outputs the lower one. In our experiments, we evaluate TECA with various TTA methods and show that TECA reduces prediction's uncertainty and increases accuracy of TTA methods despite having no hyperparameters and little parameter overhead.
Improving Image Coding for Machines through Optimizing Encoder via Auxiliary Loss
Feb 13, 2024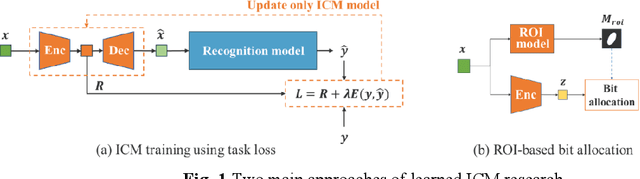

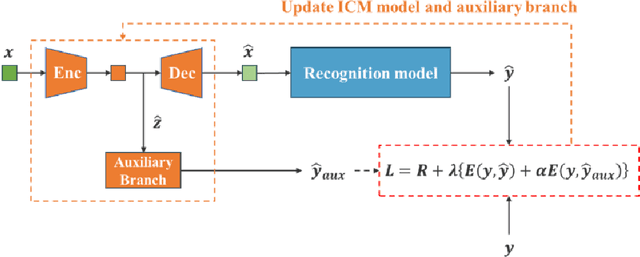
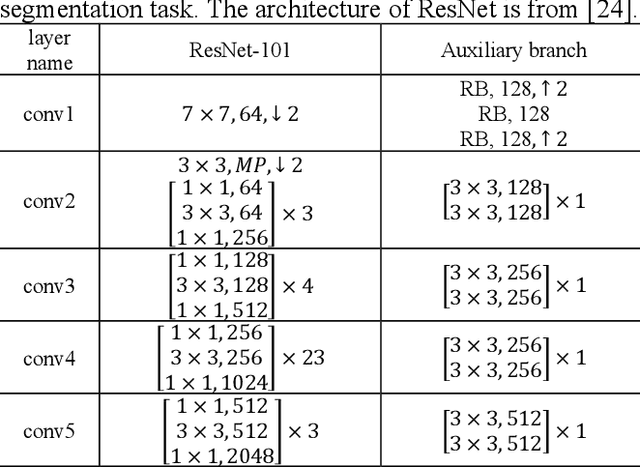
Image coding for machines (ICM) aims to compress images for machine analysis using recognition models rather than human vision. Hence, in ICM, it is important for the encoder to recognize and compress the information necessary for the machine recognition task. There are two main approaches in learned ICM; optimization of the compression model based on task loss, and Region of Interest (ROI) based bit allocation. These approaches provide the encoder with the recognition capability. However, optimization with task loss becomes difficult when the recognition model is deep, and ROI-based methods often involve extra overhead during evaluation. In this study, we propose a novel training method for learned ICM models that applies auxiliary loss to the encoder to improve its recognition capability and rate-distortion performance. Our method achieves Bjontegaard Delta rate improvements of 27.7% and 20.3% in object detection and semantic segmentation tasks, compared to the conventional training method.
Incorporating Supervised Domain Generalization into Data Augmentation
Oct 02, 2023



With the increasing utilization of deep learning in outdoor settings, its robustness needs to be enhanced to preserve accuracy in the face of distribution shifts, such as compression artifacts. Data augmentation is a widely used technique to improve robustness, thanks to its ease of use and numerous benefits. However, it requires more training epochs, making it difficult to train large models with limited computational resources. To address this problem, we treat data augmentation as supervised domain generalization~(SDG) and benefit from the SDG method, contrastive semantic alignment~(CSA) loss, to improve the robustness and training efficiency of data augmentation. The proposed method only adds loss during model training and can be used as a plug-in for existing data augmentation methods. Experiments on the CIFAR-100 and CUB datasets show that the proposed method improves the robustness and training efficiency of typical data augmentations.
AugNet: Dynamic Test-Time Augmentation via Differentiable Functions
Dec 09, 2022



Distribution shifts, which often occur in the real world, degrade the accuracy of deep learning systems, and thus improving robustness is essential for practical applications. To improve robustness, we study an image enhancement method that generates recognition-friendly images without retraining the recognition model. We propose a novel image enhancement method, AugNet, which is based on differentiable data augmentation techniques and generates a blended image from many augmented images to improve the recognition accuracy under distribution shifts. In addition to standard data augmentations, AugNet can also incorporate deep neural network-based image transformation, which further improves the robustness. Because AugNet is composed of differentiable functions, AugNet can be directly trained with the classification loss of the recognition model. AugNet is evaluated on widely used image recognition datasets using various classification models, including Vision Transformer and MLP-Mixer. AugNet improves the robustness with almost no reduction in classification accuracy for clean images, which is a better result than the existing methods. Furthermore, we show that interpretation of distribution shifts using AugNet and retraining based on that interpretation can greatly improve robustness.
Learning to Cascade: Confidence Calibration for Improving the Accuracy and Computational Cost of Cascade Inference Systems
Apr 15, 2021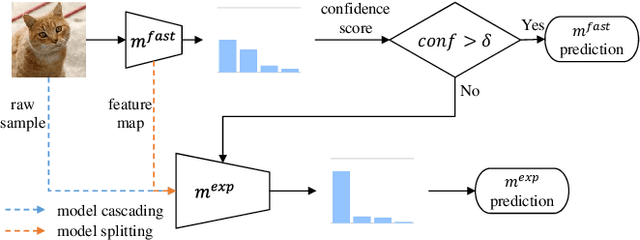
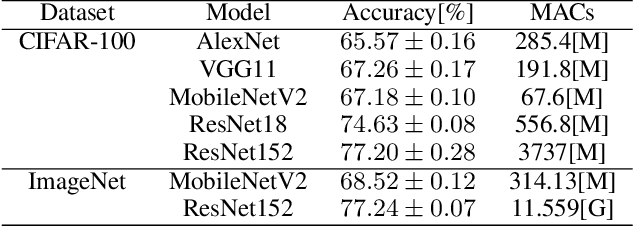
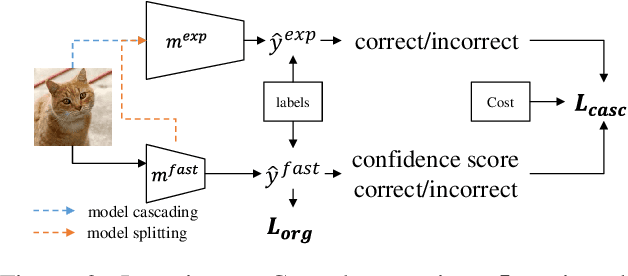

Recently, deep neural networks have become to be used in a variety of applications. While the accuracy of deep neural networks is increasing, the confidence score, which indicates the reliability of the prediction results, is becoming more important. Deep neural networks are seen as highly accurate but known to be overconfident, making it important to calibrate the confidence score. Many studies have been conducted on confidence calibration. They calibrate the confidence score of the model to match its accuracy, but it is not clear whether these confidence scores can improve the performance of systems that use confidence scores. This paper focuses on cascade inference systems, one kind of systems using confidence scores, and discusses the desired confidence score to improve system performance in terms of inference accuracy and computational cost. Based on the discussion, we propose a new confidence calibration method, Learning to Cascade. Learning to Cascade is a simple but novel method that optimizes the loss term for confidence calibration simultaneously with the original loss term. Experiments are conducted using two datasets, CIFAR-100 and ImageNet, in two system settings, and show that naive application of existing calibration methods to cascade inference systems sometimes performs worse. However, Learning to Cascade always achieves a better trade-off between inference accuracy and computational cost. The simplicity of Learning to Cascade allows it to be easily applied to improve the performance of existing systems.
Effective Data Augmentation with Multi-Domain Learning GANs
Dec 25, 2019



For deep learning applications, the massive data development (e.g., collecting, labeling), which is an essential process in building practical applications, still incurs seriously high costs. In this work, we propose an effective data augmentation method based on generative adversarial networks (GANs), called Domain Fusion. Our key idea is to import the knowledge contained in an outer dataset to a target model by using a multi-domain learning GAN. The multi-domain learning GAN simultaneously learns the outer and target dataset and generates new samples for the target tasks. The simultaneous learning process makes GANs generate the target samples with high fidelity and variety. As a result, we can obtain accurate models for the target tasks by using these generated samples even if we only have an extremely low volume target dataset. We experimentally evaluate the advantages of Domain Fusion in image classification tasks on 3 target datasets: CIFAR-100, FGVC-Aircraft, and Indoor Scene Recognition. When trained on each target dataset reduced the samples to 5,000 images, Domain Fusion achieves better classification accuracy than the data augmentation using fine-tuned GANs. Furthermore, we show that Domain Fusion improves the quality of generated samples, and the improvements can contribute to higher accuracy.