 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiplicative Logit Adjustment Approximates Neural-Collapse-Aware Decision Boundary Adjustment
Sep 26, 2024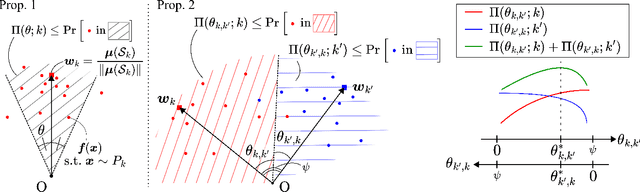

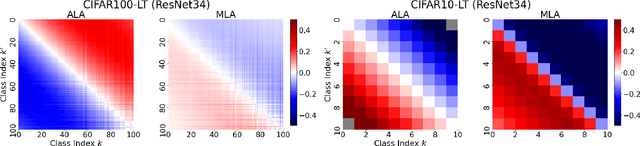

Real-world data distributions are often highly skewed. This has spurred a growing body of research on long-tailed recognition to address this imbalance in training classification models. Among the methods studied, multiplicative logit adjustment (MLA) stands out as a simple and effective method. However, it lacks theoretical guarantees, which raises concerns about the optimality of its adjustment method. We provide a theoretical justification for the effectiveness of MLA with the following two-step theory. First, we develop a theory that adjusts optimal decision boundaries by estimating feature spread on the basis of neural collapse. Then, we demonstrate that MLA approximates this optimal method. Additionally, through experiments on long-tailed datasets, we illustrate the practical usefulness of MLA under more realistic conditions. We also offer experimental insights to guide the tuning of MLA's hyperparameters.
Test-time Adaptation Meets Image Enhancement: Improving Accuracy via Uncertainty-aware Logit Switching
Mar 26, 2024



Deep neural networks have achieved remarkable success in a variety of computer vision applications. However, there is a problem of degrading accuracy when the data distribution shifts between training and testing. As a solution of this problem, Test-time Adaptation~(TTA) has been well studied because of its practicality. Although TTA methods increase accuracy under distribution shift by updating the model at test time, using high-uncertainty predictions is known to degrade accuracy. Since the input image is the root of the distribution shift, we incorporate a new perspective on enhancing the input image into TTA methods to reduce the prediction's uncertainty. We hypothesize that enhancing the input image reduces prediction's uncertainty and increase the accuracy of TTA methods. On the basis of our hypothesis, we propose a novel method: Test-time Enhancer and Classifier Adaptation~(TECA). In TECA, the classification model is combined with the image enhancement model that transforms input images into recognition-friendly ones, and these models are updated by existing TTA methods. Furthermore, we found that the prediction from the enhanced image does not always have lower uncertainty than the prediction from the original image. Thus, we propose logit switching, which compares the uncertainty measure of these predictions and outputs the lower one. In our experiments, we evaluate TECA with various TTA methods and show that TECA reduces prediction's uncertainty and increases accuracy of TTA methods despite having no hyperparameters and little parameter overhead.
Exploring Weight Balancing on Long-Tailed Recognition Problem
May 29, 2023

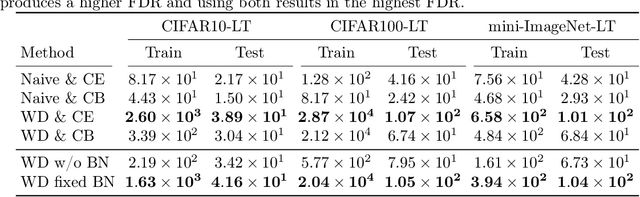

Recognition problems in long-tailed data, where the sample size per class is heavily skewed, have recently gained importance because the distribution of the sample size per class in a dataset is generally exponential unless the sample size is intentionally adjusted. Various approaches have been devised to address these problems. Recently, weight balancing, which combines well-known classical regularization techniques with two-stage training, has been proposed. Despite its simplicity, it is known for its high performance against existing methods devised in various ways. However, there is a lack of understanding as to why this approach is effective for long-tailed data. In this study, we analyze the method focusing on neural collapse and cone effect at each training stage and find that it can be decomposed into the increase in Fisher's discriminant ratio of the feature extractor caused by weight decay and cross entropy loss and implicit logit adjustment caused by weight decay and class-balanced loss. Our analysis shows that the training method can be further simplified by reducing the number of training stages to one while increasing accuracy.