 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiModal Fine-tuning with Synthetic Captions
Jan 29, 2026In this paper, we address a fundamental gap between pre-training and fine-tuning of deep neural networks: while pre-training has shifted from unimodal to multimodal learning with enhanced visual understanding, fine-tuning predominantly remains unimodal, limiting the benefits of rich pre-trained representations. To bridge this gap, we propose a novel approach that transforms unimodal datasets into multimodal ones using Multimodal Large Language Models (MLLMs) to generate synthetic image captions for fine-tuning models with a multimodal objective. Our method employs carefully designed prompts incorporating class labels and domain context to produce high-quality captions tailored for classification tasks. Furthermore, we introduce a supervised contrastive loss function that explicitly encourages clustering of same-class representations during fine-tuning, along with a new inference technique that leverages class-averaged text embeddings from multiple synthetic captions per image. Extensive experiments across 13 image classification benchmarks demonstrate that our approach outperforms baseline methods, with particularly significant improvements in few-shot learning scenarios. Our work establishes a new paradigm for dataset enhancement that effectively bridges the gap between multimodal pre-training and fine-tuning. Our code is available at https://github.com/s-enmt/MMFT.
Enhancing Visual Prompting through Expanded Transformation Space and Overfitting Mitigation
Oct 09, 2025Visual prompting (VP) has emerged as a promising parameter-efficient fine-tuning approach for adapting pre-trained vision models to downstream tasks without modifying model parameters. Despite offering advantages like negligible computational overhead and compatibility with black-box models, conventional VP methods typically achieve lower accuracy than other adaptation approaches. Our analysis reveals two critical limitations: the restricted expressivity of simple additive transformation and a tendency toward overfitting when the parameter count increases. To address these challenges, we propose ACAVP (Affine, Color, and Additive Visual Prompting), which enhances VP's expressive power by introducing complementary transformation operations: affine transformation for creating task-specific prompt regions while preserving original image information, and color transformation for emphasizing task-relevant visual features. Additionally, we identify that overfitting is a critical issue in VP training and introduce TrivialAugment as an effective data augmentation, which not only benefits our approach but also significantly improves existing VP methods, with performance gains of up to 12 percentage points on certain datasets. This demonstrates that appropriate data augmentation is universally beneficial for VP training. Extensive experiments across twelve diverse image classification datasets with two different model architectures demonstrate that ACAVP achieves state-of-the-art accuracy among VP methods, surpasses linear probing in average accuracy, and exhibits superior robustness to distribution shifts, all while maintaining minimal computational overhead during inference.
Pseudo Multi-Source Domain Generalization: Bridging the Gap Between Single and Multi-Source Domain Generalization
May 29, 2025Deep learning models often struggle to maintain performance when deployed on data distributions different from their training data, particularly in real-world applications where environmental conditions frequently change. While Multi-source Domain Generalization (MDG) has shown promise in addressing this challenge by leveraging multiple source domains during training, its practical application is limited by the significant costs and difficulties associated with creating multi-domain datasets. To address this limitation, we propose Pseudo Multi-source Domain Generalization (PMDG), a novel framework that enables the application of sophisticated MDG algorithms in more practical Single-source Domain Generalization (SDG) settings. PMDG generates multiple pseudo-domains from a single source domain through style transfer and data augmentation techniques, creating a synthetic multi-domain dataset that can be used with existing MDG algorithms. Through extensive experiments with PseudoDomainBed, our modified version of the DomainBed benchmark, we analyze the effectiveness of PMDG across multiple datasets and architectures. Our analysis reveals several key findings, including a positive correlation between MDG and PMDG performance and the potential of pseudo-domains to match or exceed actual multi-domain performance with sufficient data. These comprehensive empirical results provide valuable insights for future research in domain generalization. Our code is available at https://github.com/s-enmt/PseudoDomainBed.
Inter-Feature-Map Differential Coding of Surveillance Video
Nov 01, 2024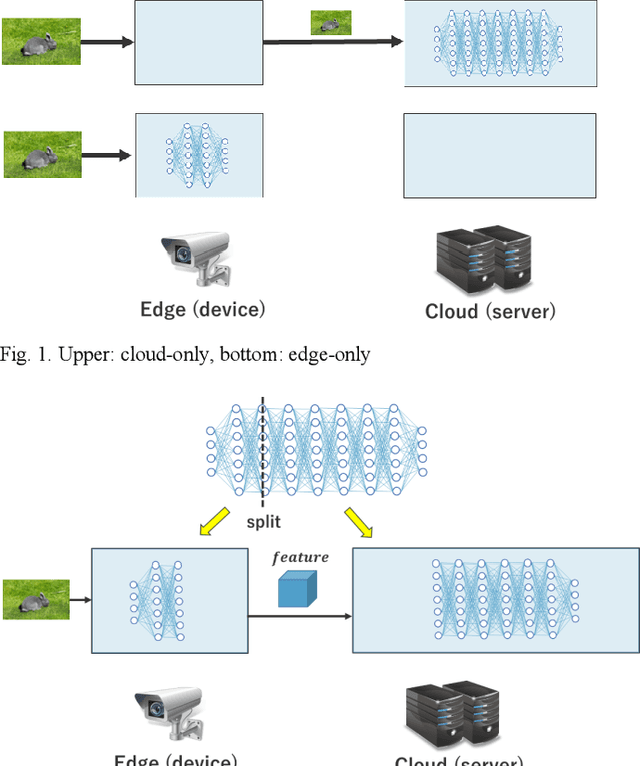
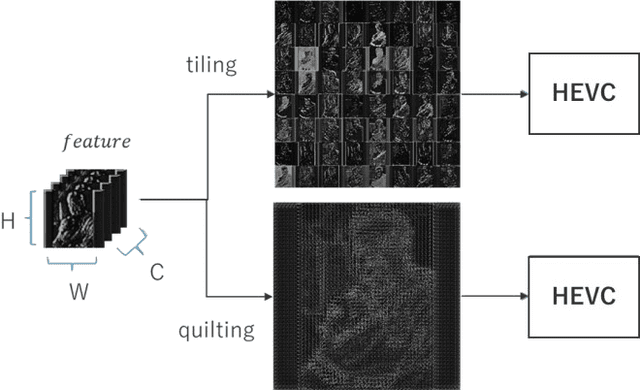
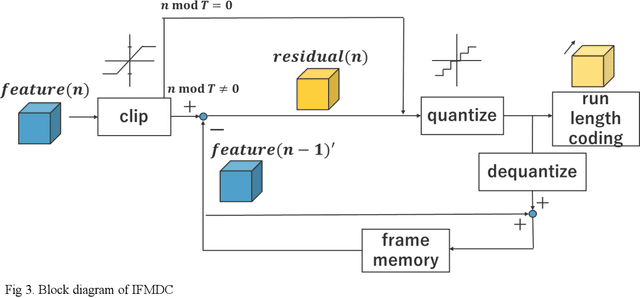
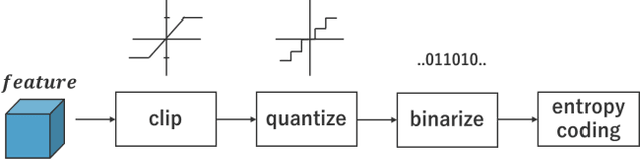
In Collaborative Intelligence, a deep neural network (DNN) is partitioned and deployed at the edge and the cloud for bandwidth saving and system optimization. When a model input is an image, it has been confirmed that the intermediate feature map, the output from the edge, can be smaller than the input data size. However, its effectiveness has not been reported when the input is a video. In this study, we propose a method to compress the feature map of surveillance videos by applying inter-feature-map differential coding (IFMDC). IFMDC shows a compression ratio comparable to, or better than, HEVC to the input video in the case of small accuracy reduction. Our method is especially effective for videos that are sensitive to image quality degradation when HEVC is applied
* \c{opyright} 2022 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
EntProp: High Entropy Propagation for Improving Accuracy and Robustness
May 29, 2024Deep neural networks (DNNs) struggle to generalize to out-of-distribution domains that are different from those in training despite their impressive performance. In practical applications, it is important for DNNs to have both high standard accuracy and robustness against out-of-distribution domains. One technique that achieves both of these improvements is disentangled learning with mixture distribution via auxiliary batch normalization layers (ABNs). This technique treats clean and transformed samples as different domains, allowing a DNN to learn better features from mixed domains. However, if we distinguish the domains of the samples based on entropy, we find that some transformed samples are drawn from the same domain as clean samples, and these samples are not completely different domains. To generate samples drawn from a completely different domain than clean samples, we hypothesize that transforming clean high-entropy samples to further increase the entropy generates out-of-distribution samples that are much further away from the in-distribution domain. On the basis of the hypothesis, we propose high entropy propagation~(EntProp), which feeds high-entropy samples to the network that uses ABNs. We introduce two techniques, data augmentation and free adversarial training, that increase entropy and bring the sample further away from the in-distribution domain. These techniques do not require additional training costs. Our experimental results show that EntProp achieves higher standard accuracy and robustness with a lower training cost than the baseline methods. In particular, EntProp is highly effective at training on small datasets.
Test-time Adaptation Meets Image Enhancement: Improving Accuracy via Uncertainty-aware Logit Switching
Mar 26, 2024



Deep neural networks have achieved remarkable success in a variety of computer vision applications. However, there is a problem of degrading accuracy when the data distribution shifts between training and testing. As a solution of this problem, Test-time Adaptation~(TTA) has been well studied because of its practicality. Although TTA methods increase accuracy under distribution shift by updating the model at test time, using high-uncertainty predictions is known to degrade accuracy. Since the input image is the root of the distribution shift, we incorporate a new perspective on enhancing the input image into TTA methods to reduce the prediction's uncertainty. We hypothesize that enhancing the input image reduces prediction's uncertainty and increase the accuracy of TTA methods. On the basis of our hypothesis, we propose a novel method: Test-time Enhancer and Classifier Adaptation~(TECA). In TECA, the classification model is combined with the image enhancement model that transforms input images into recognition-friendly ones, and these models are updated by existing TTA methods. Furthermore, we found that the prediction from the enhanced image does not always have lower uncertainty than the prediction from the original image. Thus, we propose logit switching, which compares the uncertainty measure of these predictions and outputs the lower one. In our experiments, we evaluate TECA with various TTA methods and show that TECA reduces prediction's uncertainty and increases accuracy of TTA methods despite having no hyperparameters and little parameter overhead.
Test-time Similarity Modification for Person Re-identification toward Temporal Distribution Shift
Mar 21, 2024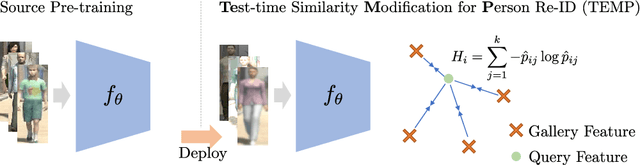

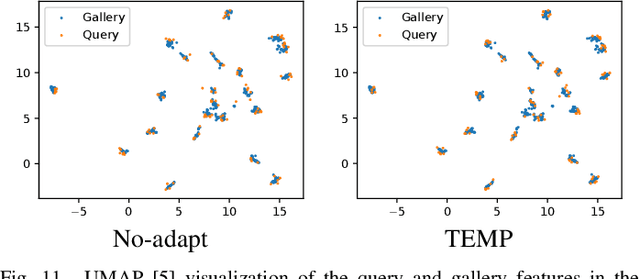

Person re-identification (re-id), which aims to retrieve images of the same person in a given image from a database, is one of the most practical image recognition applications. In the real world, however, the environments that the images are taken from change over time. This causes a distribution shift between training and testing and degrades the performance of re-id. To maintain re-id performance, models should continue adapting to the test environment's temporal changes. Test-time adaptation (TTA), which aims to adapt models to the test environment with only unlabeled test data, is a promising way to handle this problem because TTA can adapt models instantly in the test environment. However, the previous TTA methods are designed for classification and cannot be directly applied to re-id. This is because the set of people's identities in the dataset differs between training and testing in re-id, whereas the set of classes is fixed in the current TTA methods designed for classification. To improve re-id performance in changing test environments, we propose TEst-time similarity Modification for Person re-identification (TEMP), a novel TTA method for re-id. TEMP is the first fully TTA method for re-id, which does not require any modification to pre-training. Inspired by TTA methods that refine the prediction uncertainty in classification, we aim to refine the uncertainty in re-id. However, the uncertainty cannot be computed in the same way as classification in re-id since it is an open-set task, which does not share person labels between training and testing. Hence, we propose re-id entropy, an alternative uncertainty measure for re-id computed based on the similarity between the feature vectors. Experiments show that the re-id entropy can measure the uncertainty on re-id and TEMP improves the performance of re-id in online settings where the distribution changes over time.
Improving Image Coding for Machines through Optimizing Encoder via Auxiliary Loss
Feb 13, 2024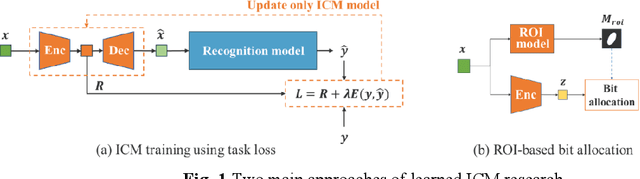

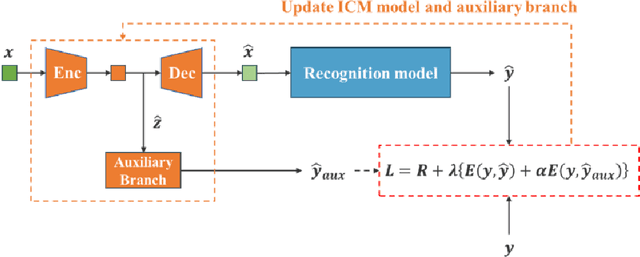
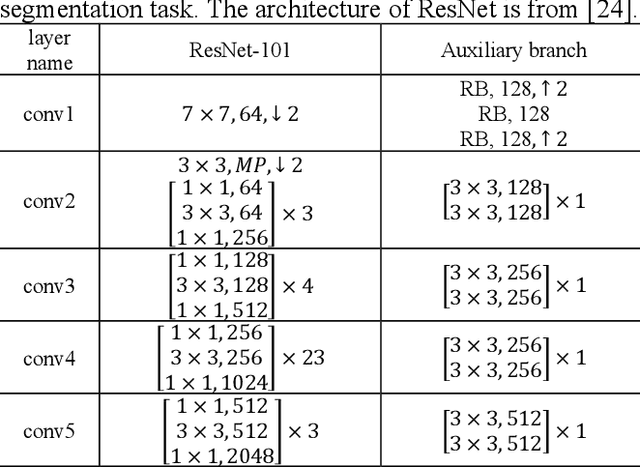
Image coding for machines (ICM) aims to compress images for machine analysis using recognition models rather than human vision. Hence, in ICM, it is important for the encoder to recognize and compress the information necessary for the machine recognition task. There are two main approaches in learned ICM; optimization of the compression model based on task loss, and Region of Interest (ROI) based bit allocation. These approaches provide the encoder with the recognition capability. However, optimization with task loss becomes difficult when the recognition model is deep, and ROI-based methods often involve extra overhead during evaluation. In this study, we propose a novel training method for learned ICM models that applies auxiliary loss to the encoder to improve its recognition capability and rate-distortion performance. Our method achieves Bjontegaard Delta rate improvements of 27.7% and 20.3% in object detection and semantic segmentation tasks, compared to the conventional training method.
Incorporating Supervised Domain Generalization into Data Augmentation
Oct 02, 2023



With the increasing utilization of deep learning in outdoor settings, its robustness needs to be enhanced to preserve accuracy in the face of distribution shifts, such as compression artifacts. Data augmentation is a widely used technique to improve robustness, thanks to its ease of use and numerous benefits. However, it requires more training epochs, making it difficult to train large models with limited computational resources. To address this problem, we treat data augmentation as supervised domain generalization~(SDG) and benefit from the SDG method, contrastive semantic alignment~(CSA) loss, to improve the robustness and training efficiency of data augmentation. The proposed method only adds loss during model training and can be used as a plug-in for existing data augmentation methods. Experiments on the CIFAR-100 and CUB datasets show that the proposed method improves the robustness and training efficiency of typical data augmentations.
AugNet: Dynamic Test-Time Augmentation via Differentiable Functions
Dec 09, 2022



Distribution shifts, which often occur in the real world, degrade the accuracy of deep learning systems, and thus improving robustness is essential for practical applications. To improve robustness, we study an image enhancement method that generates recognition-friendly images without retraining the recognition model. We propose a novel image enhancement method, AugNet, which is based on differentiable data augmentation techniques and generates a blended image from many augmented images to improve the recognition accuracy under distribution shifts. In addition to standard data augmentations, AugNet can also incorporate deep neural network-based image transformation, which further improves the robustness. Because AugNet is composed of differentiable functions, AugNet can be directly trained with the classification loss of the recognition model. AugNet is evaluated on widely used image recognition datasets using various classification models, including Vision Transformer and MLP-Mixer. AugNet improves the robustness with almost no reduction in classification accuracy for clean images, which is a better result than the existing methods. Furthermore, we show that interpretation of distribution shifts using AugNet and retraining based on that interpretation can greatly improve robustness.