 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInter-Feature-Map Differential Coding of Surveillance Video
Nov 01, 2024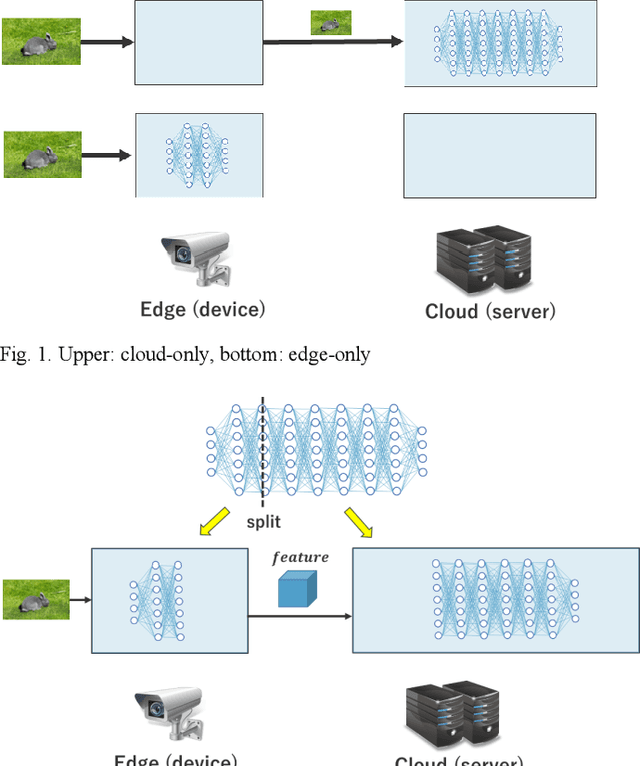
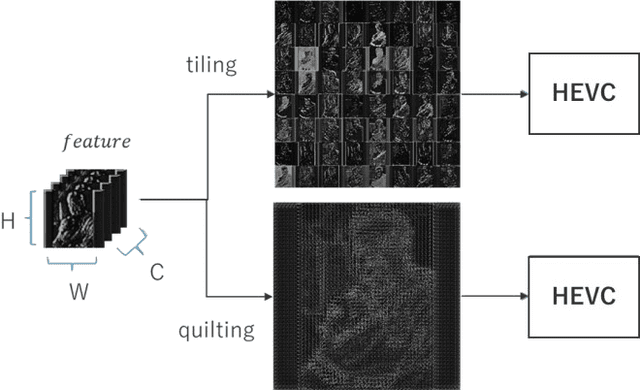
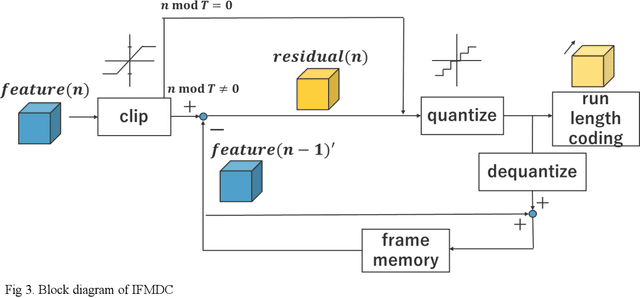
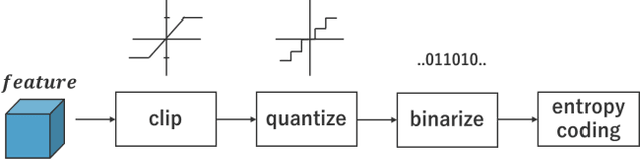
In Collaborative Intelligence, a deep neural network (DNN) is partitioned and deployed at the edge and the cloud for bandwidth saving and system optimization. When a model input is an image, it has been confirmed that the intermediate feature map, the output from the edge, can be smaller than the input data size. However, its effectiveness has not been reported when the input is a video. In this study, we propose a method to compress the feature map of surveillance videos by applying inter-feature-map differential coding (IFMDC). IFMDC shows a compression ratio comparable to, or better than, HEVC to the input video in the case of small accuracy reduction. Our method is especially effective for videos that are sensitive to image quality degradation when HEVC is applied
* \c{opyright} 2022 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
Improving Image Coding for Machines through Optimizing Encoder via Auxiliary Loss
Feb 13, 2024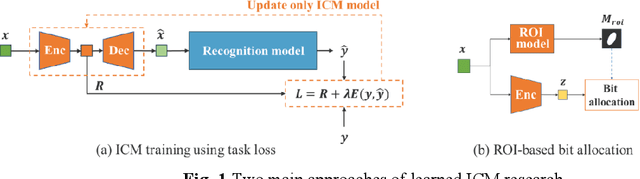

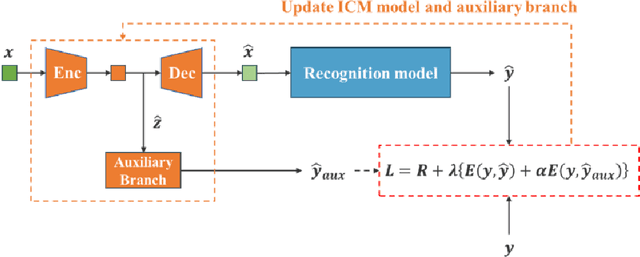
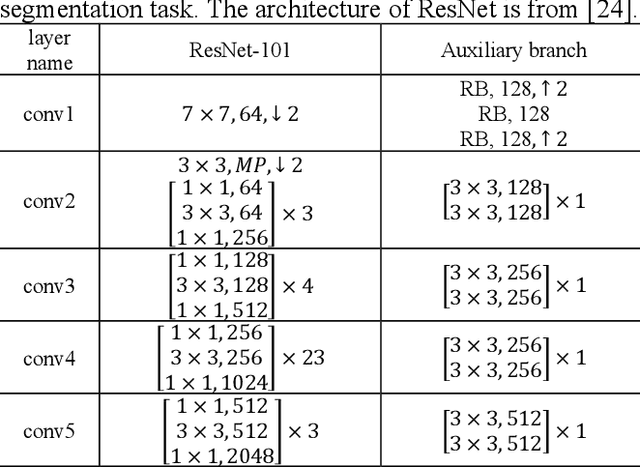
Image coding for machines (ICM) aims to compress images for machine analysis using recognition models rather than human vision. Hence, in ICM, it is important for the encoder to recognize and compress the information necessary for the machine recognition task. There are two main approaches in learned ICM; optimization of the compression model based on task loss, and Region of Interest (ROI) based bit allocation. These approaches provide the encoder with the recognition capability. However, optimization with task loss becomes difficult when the recognition model is deep, and ROI-based methods often involve extra overhead during evaluation. In this study, we propose a novel training method for learned ICM models that applies auxiliary loss to the encoder to improve its recognition capability and rate-distortion performance. Our method achieves Bjontegaard Delta rate improvements of 27.7% and 20.3% in object detection and semantic segmentation tasks, compared to the conventional training method.