 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternVLA-A1: Unifying Understanding, Generation and Action for Robotic Manipulation
Jan 05, 2026Prevalent Vision-Language-Action (VLA) models are typically built upon Multimodal Large Language Models (MLLMs) and demonstrate exceptional proficiency in semantic understanding, but they inherently lack the capability to deduce physical world dynamics. Consequently, recent approaches have shifted toward World Models, typically formulated via video prediction; however, these methods often suffer from a lack of semantic grounding and exhibit brittleness when handling prediction errors. To synergize semantic understanding with dynamic predictive capabilities, we present InternVLA-A1. This model employs a unified Mixture-of-Transformers architecture, coordinating three experts for scene understanding, visual foresight generation, and action execution. These components interact seamlessly through a unified masked self-attention mechanism. Building upon InternVL3 and Qwen3-VL, we instantiate InternVLA-A1 at 2B and 3B parameter scales. We pre-train these models on hybrid synthetic-real datasets spanning InternData-A1 and Agibot-World, covering over 533M frames. This hybrid training strategy effectively harnesses the diversity of synthetic simulation data while minimizing the sim-to-real gap. We evaluated InternVLA-A1 across 12 real-world robotic tasks and simulation benchmark. It significantly outperforms leading models like pi0 and GR00T N1.5, achieving a 14.5\% improvement in daily tasks and a 40\%-73.3\% boost in dynamic settings, such as conveyor belt sorting.
RSMA-Assited and Transceiver-Coordinated ICI Management for MIMO-OFDM System
Dec 19, 2025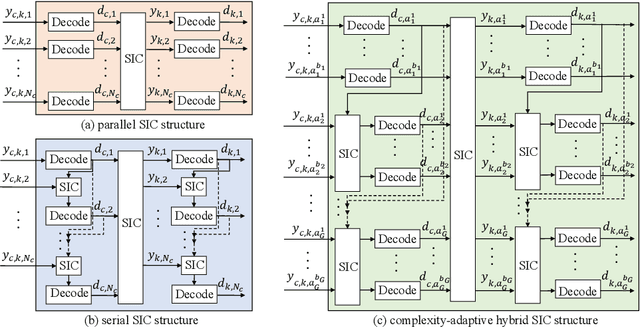
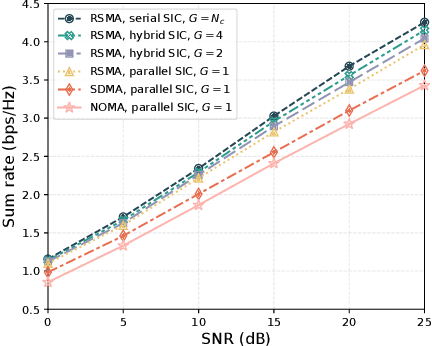
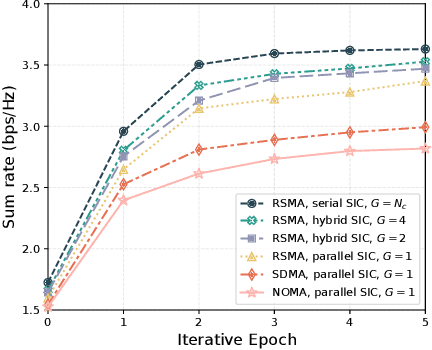
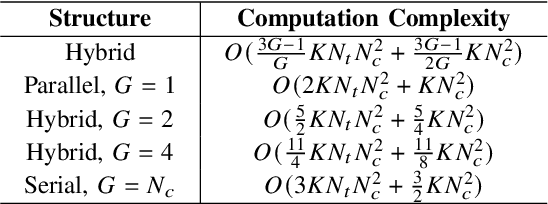
High-mobility scenarios are becoming increasingly critical in next-generation communication systems. While multiple-input multiple-output orthogonal frequency division multiplexing (MIMO-OFDM) stands as a prominent technology, its performance in such scenarios is fundamentally limited by Doppler-induced inter-carrier interference (ICI). Rate splitting multiple access (RSMA), recognized as a key multiple access technique for future communications, demonstrates superior interference management capabilities that we leverage to address this challenge. In specific, we propose a novel RSMA-assisted and transceiver-coordinated transmission scheme for ICI management in MIMO-OFDM system: (1) At the receiver side, we develop a hybrid successive interference cancellation (SIC) architecture with dynamic subcarrier clustering, which enables parallel intra-cluster and serial inter-cluster processing to balance complexity and performance. (2) At the transmitter~side, we design a matched hybrid precoding through formulated sum-rate maximization, solved via our proposed augmented boundary-compressed particle swarm optimization (ABC-PSO) algorithm for analog phase optimization and weighted minimum mean-square error (WMMSE)-based digital precoding iteration. Simulation results show that our scheme brings effective ICI suppression and enhanced system capacity with controlled complexity.
Beamforming-Codebook-Aware Channel Knowledge Map Construction for Multi-Antenna Systems
May 22, 2025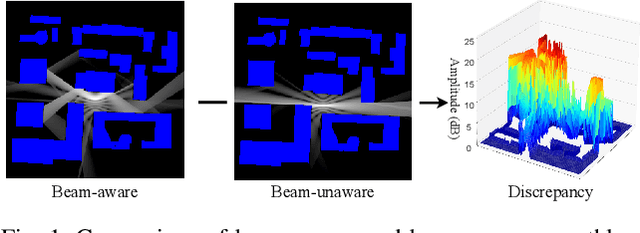
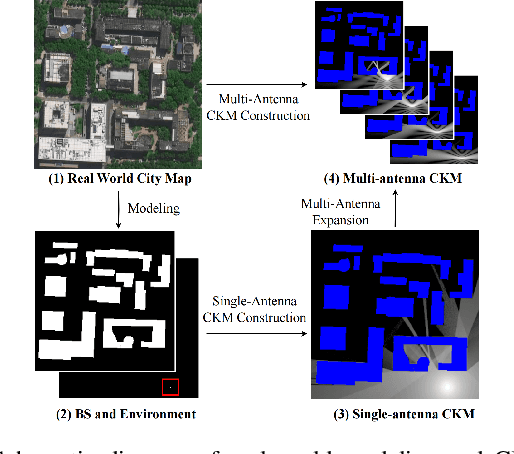
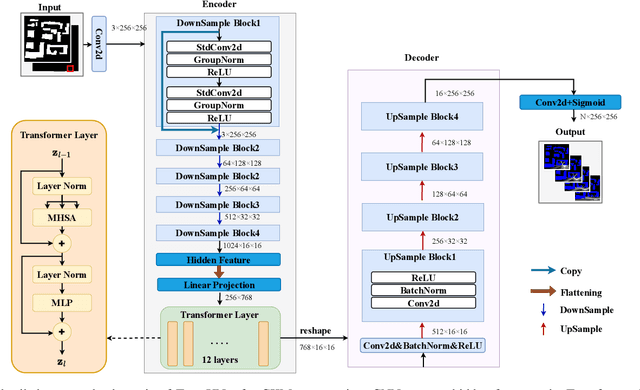

Channel knowledge map (CKM) has emerged as a crucial technology for next-generation communication, enabling the construction of high-fidelity mappings between spatial environments and channel parameters via electromagnetic information analysis. Traditional CKM construction methods like ray tracing are computationally intensive. Recent studies utilizing neural networks (NNs) have achieved efficient CKM generation with reduced computational complexity and real-time processing capabilities. Nevertheless, existing research predominantly focuses on single-antenna systems, failing to address the beamforming requirements inherent to MIMO configurations. Given that appropriate precoding vector selection in MIMO systems can substantially enhance user communication rates, this paper presents a TransUNet-based framework for constructing CKM, which effectively incorporates discrete Fourier transform (DFT) precoding vectors. The proposed architecture combines a UNet backbone for multiscale feature extraction with a Transformer module to capture global dependencies among encoded linear vectors. Experimental results demonstrate that the proposed method outperforms state-of-the-art (SOTA) deep learning (DL) approaches, yielding a 17\% improvement in RMSE compared to RadioWNet. The code is publicly accessible at https://github.com/github-whh/TransUNet.
Lightweight and Self-Evolving Channel Twinning: An Ensemble DMD-Assisted Approach
Apr 23, 2025



Traditional channel acquisition faces significant limitations due to ideal model assumptions and scalability challenges. A novel environment-aware paradigm, known as channel twinning, tackles these issues by constructing radio propagation environment semantics using a data-driven approach. In the spotlight of channel twinning technology, a radio map is recognized as an effective region-specific model for learning the spatial distribution of channel information. However, most studies focus on static channel map construction, with only a few collecting numerous channel samples and using deep learning for radio map prediction. In this paper, we develop a novel dynamic radio map twinning framework with a substantially small dataset. Specifically, we present an innovative approach that employs dynamic mode decomposition (DMD) to model the evolution of the dynamic channel gain map as a dynamical system. We first interpret dynamic channel gain maps as spatio-temporal video stream data. The coarse-grained and fine-grained evolving modes are extracted from the stream data using a new ensemble DMD (Ens-DMD) algorithm. To mitigate the impact of noisy data, we design a median-based threshold mask technique to filter the noise artifacts of the twin maps. With the proposed DMD-based radio map twinning framework, numerical results are provided to demonstrate the low-complexity reproduction and evolution of the channel gain maps. Furthermore, we consider four radio map twin performance metrics to confirm the superiority of our framework compared to the baselines.
Generating Synthetic Electronic Health Record (EHR) Data: A Review with Benchmarking
Nov 06, 2024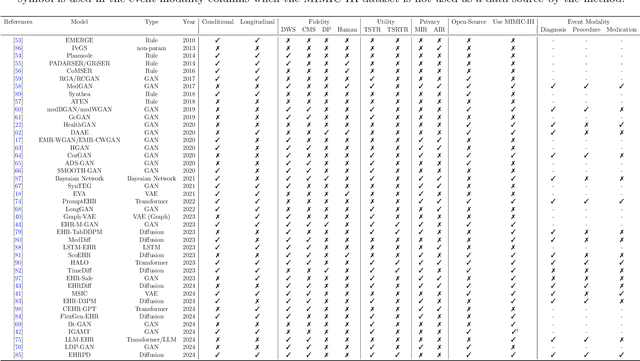
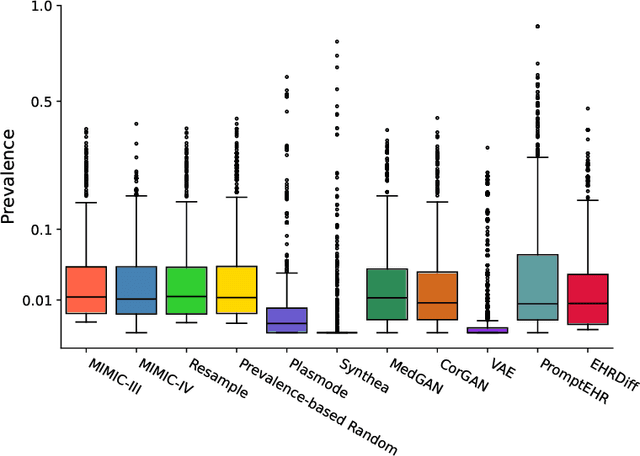
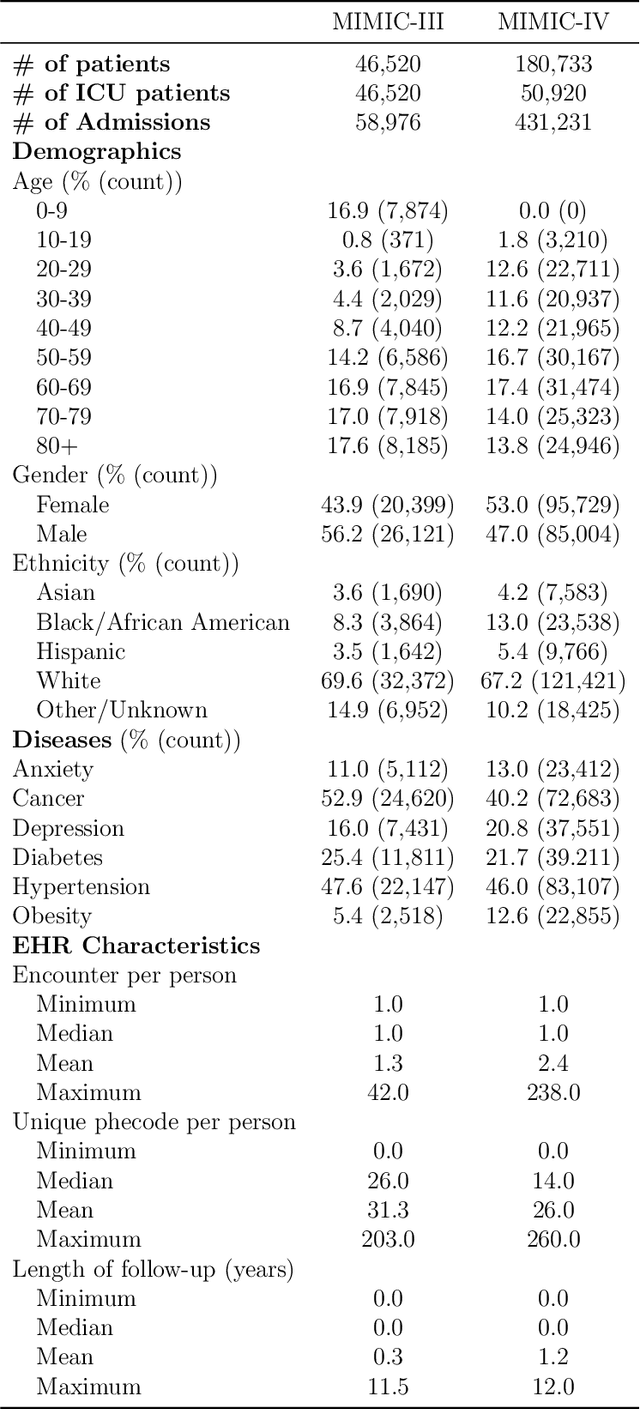
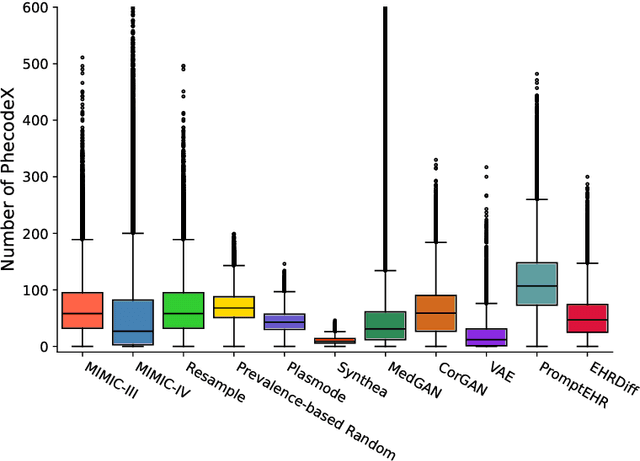
We conduct a scoping review of existing approaches for synthetic EHR data generation, and benchmark major methods with proposed open-source software to offer recommendations for practitioners. We search three academic databases for our scoping review. Methods are benchmarked on open-source EHR datasets, MIMIC-III/IV. Seven existing methods covering major categories and two baseline methods are implemented and compared. Evaluation metrics concern data fidelity, downstream utility, privacy protection, and computational cost. 42 studies are identified and classified into five categories. Seven open-source methods covering all categories are selected, trained on MIMIC-III, and evaluated on MIMIC-III or MIMIC-IV for transportability considerations. Among them, GAN-based methods demonstrate competitive performance in fidelity and utility on MIMIC-III; rule-based methods excel in privacy protection. Similar findings are observed on MIMIC-IV, except that GAN-based methods further outperform the baseline methods in preserving fidelity. A Python package, ``SynthEHRella'', is provided to integrate various choices of approaches and evaluation metrics, enabling more streamlined exploration and evaluation of multiple methods. We found that method choice is governed by the relative importance of the evaluation metrics in downstream use cases. We provide a decision tree to guide the choice among the benchmarked methods. Based on the decision tree, GAN-based methods excel when distributional shifts exist between the training and testing populations. Otherwise, CorGAN and MedGAN are most suitable for association modeling and predictive modeling, respectively. Future research should prioritize enhancing fidelity of the synthetic data while controlling privacy exposure, and comprehensive benchmarking of longitudinal or conditional generation methods.
Inter-Feature-Map Differential Coding of Surveillance Video
Nov 01, 2024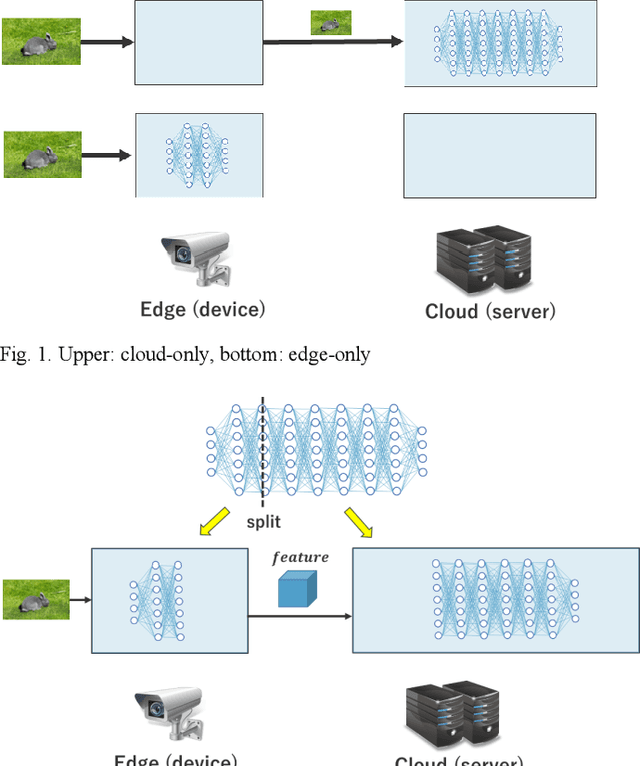
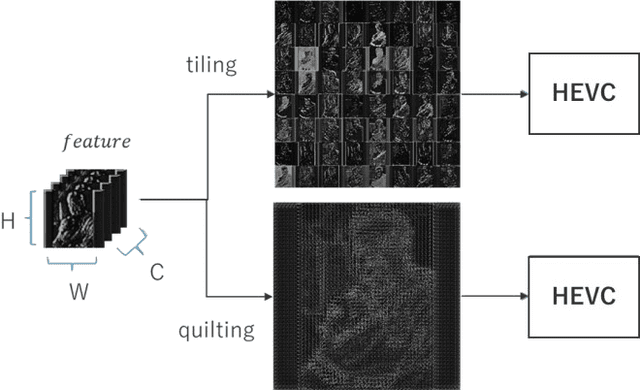
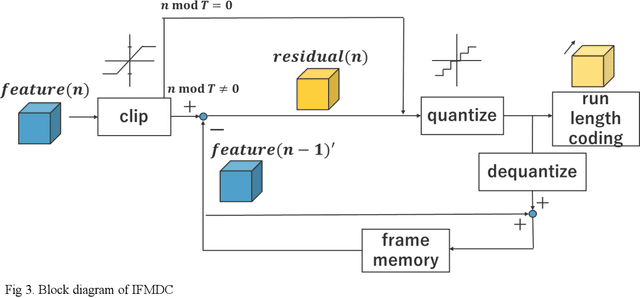
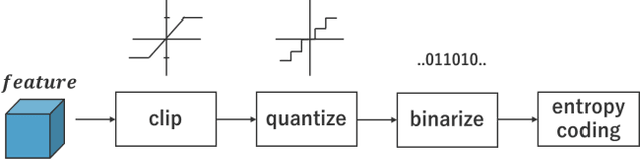
In Collaborative Intelligence, a deep neural network (DNN) is partitioned and deployed at the edge and the cloud for bandwidth saving and system optimization. When a model input is an image, it has been confirmed that the intermediate feature map, the output from the edge, can be smaller than the input data size. However, its effectiveness has not been reported when the input is a video. In this study, we propose a method to compress the feature map of surveillance videos by applying inter-feature-map differential coding (IFMDC). IFMDC shows a compression ratio comparable to, or better than, HEVC to the input video in the case of small accuracy reduction. Our method is especially effective for videos that are sensitive to image quality degradation when HEVC is applied
* \c{opyright} 2022 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
ECLIPSE: Semantic Entropy-LCS for Cross-Lingual Industrial Log Parsing
May 22, 2024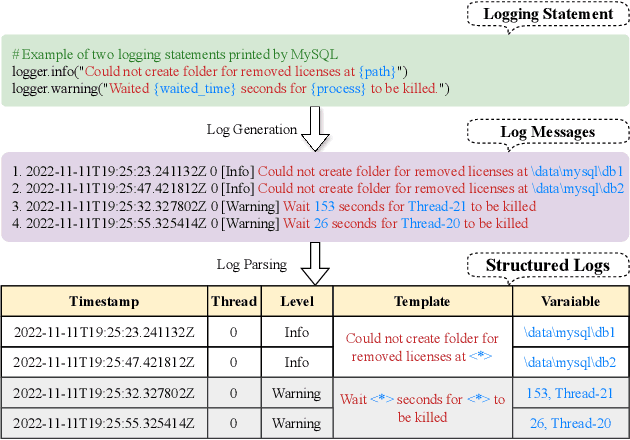


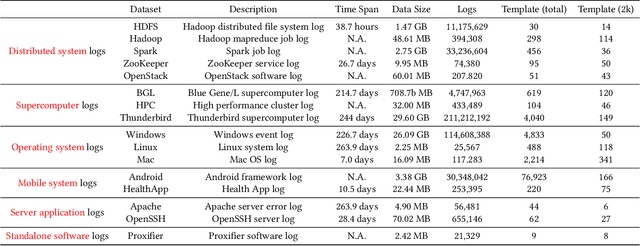
Log parsing, a vital task for interpreting the vast and complex data produced within software architectures faces significant challenges in the transition from academic benchmarks to the industrial domain. Existing log parsers, while highly effective on standardized public datasets, struggle to maintain performance and efficiency when confronted with the sheer scale and diversity of real-world industrial logs. These challenges are two-fold: 1) massive log templates: The performance and efficiency of most existing parsers will be significantly reduced when logs of growing quantities and different lengths; 2) Complex and changeable semantics: Traditional template-matching algorithms cannot accurately match the log templates of complicated industrial logs because they cannot utilize cross-language logs with similar semantics. To address these issues, we propose ECLIPSE, Enhanced Cross-Lingual Industrial log Parsing with Semantic Entropy-LCS, since cross-language logs can robustly parse industrial logs. On the one hand, it integrates two efficient data-driven template-matching algorithms and Faiss indexing. On the other hand, driven by the powerful semantic understanding ability of the Large Language Model (LLM), the semantics of log keywords were accurately extracted, and the retrieval space was effectively reduced. It is worth noting that we launched a Chinese and English cross-platform industrial log parsing benchmark ECLIPSE-Bench to evaluate the performance of mainstream parsers in industrial scenarios. Our experimental results, conducted across public benchmarks and the proprietary ECLIPSE-Bench dataset, underscore the superior performance and robustness of our proposed ECLIPSE. Notably, ECLIPSE delivers state-of-the-art performance when compared to strong baselines on diverse datasets and preserves a significant edge in processing efficiency.
Sparse Estimation for XL-MIMO with Unified LoS/NLoS Representation
Mar 19, 2024

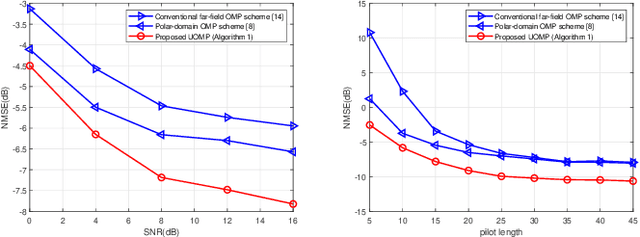
Extremely large-scale antenna array (ELAA) is promising as one of the key ingredients for the sixth generation (6G) of wireless communications. The electromagnetic propagation of spherical wavefronts introduces an additional distance-dependent dimension beyond conventional beamspace. In this paper, we first present one concise closed-form channel formulation for extremely large-scale multiple-input multiple-output (XL-MIMO). All line-of-sight (LoS) and non-line-of-sight (NLoS) paths, far-field and near-field scenarios, and XL-MIMO and XL-MISO channels are unified under the framework, where additional Vandermonde windowing matrix is exclusively considered for LoS path. Under this framework, we further propose one low-complexity unified LoS/NLoS orthogonal matching pursuit (XL-UOMP) algorithm for XL-MIMO channel estimation. The simulation results demonstrate the superiority of the proposed algorithm on both estimation accuracy and pilot consumption.
MLAD: A Unified Model for Multi-system Log Anomaly Detection
Jan 15, 2024In spite of the rapid advancements in unsupervised log anomaly detection techniques, the current mainstream models still necessitate specific training for individual system datasets, resulting in costly procedures and limited scalability due to dataset size, thereby leading to performance bottlenecks. Furthermore, numerous models lack cognitive reasoning capabilities, posing challenges in direct transferability to similar systems for effective anomaly detection. Additionally, akin to reconstruction networks, these models often encounter the "identical shortcut" predicament, wherein the majority of system logs are classified as normal, erroneously predicting normal classes when confronted with rare anomaly logs due to reconstruction errors. To address the aforementioned issues, we propose MLAD, a novel anomaly detection model that incorporates semantic relational reasoning across multiple systems. Specifically, we employ Sentence-bert to capture the similarities between log sequences and convert them into highly-dimensional learnable semantic vectors. Subsequently, we revamp the formulas of the Attention layer to discern the significance of each keyword in the sequence and model the overall distribution of the multi-system dataset through appropriate vector space diffusion. Lastly, we employ a Gaussian mixture model to highlight the uncertainty of rare words pertaining to the "identical shortcut" problem, optimizing the vector space of the samples using the maximum expectation model. Experiments on three real-world datasets demonstrate the superiority of MLAD.
Generating Fine-Grained Human Motions Using ChatGPT-Refined Descriptions
Dec 05, 2023



Recently, significant progress has been made in text-based motion generation, enabling the generation of diverse and high-quality human motions that conform to textual descriptions. However, it remains challenging to generate fine-grained or stylized motions due to the lack of datasets annotated with detailed textual descriptions. By adopting a divide-and-conquer strategy, we propose a new framework named Fine-Grained Human Motion Diffusion Model (FG-MDM) for human motion generation. Specifically, we first parse previous vague textual annotation into fine-grained description of different body parts by leveraging a large language model (GPT-3.5). We then use these fine-grained descriptions to guide a transformer-based diffusion model. FG-MDM can generate fine-grained and stylized motions even outside of the distribution of the training data. Our experimental results demonstrate the superiority of FG-MDM over previous methods, especially the strong generalization capability. We will release our fine-grained textual annotations for HumanML3D and KIT.