 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Rebuilding" Statistics in the Age of AI: A Town Hall Discussion on Culture, Infrastructure, and Training
Jan 24, 2026This article presents the full, original record of the 2024 Joint Statistical Meetings (JSM) town hall, "Statistics in the Age of AI," which convened leading statisticians to discuss how the field is evolving in response to advances in artificial intelligence, foundation models, large-scale empirical modeling, and data-intensive infrastructures. The town hall was structured around open panel discussion and extensive audience Q&A, with the aim of eliciting candid, experience-driven perspectives rather than formal presentations or prepared statements. This document preserves the extended exchanges among panelists and audience members, with minimal editorial intervention, and organizes the conversation around five recurring questions concerning disciplinary culture and practices, data curation and "data work," engagement with modern empirical modeling, training for large-scale AI applications, and partnerships with key AI stakeholders. By providing an archival record of this discussion, the preprint aims to support transparency, community reflection, and ongoing dialogue about the evolving role of statistics in the data- and AI-centric future.
A Unified Framework for Inference with General Missingness Patterns and Machine Learning Imputation
Aug 21, 2025

Pre-trained machine learning (ML) predictions have been increasingly used to complement incomplete data to enable downstream scientific inquiries, but their naive integration risks biased inferences. Recently, multiple methods have been developed to provide valid inference with ML imputations regardless of prediction quality and to enhance efficiency relative to complete-case analyses. However, existing approaches are often limited to missing outcomes under a missing-completely-at-random (MCAR) assumption, failing to handle general missingness patterns under the more realistic missing-at-random (MAR) assumption. This paper develops a novel method which delivers valid statistical inference framework for general Z-estimation problems using ML imputations under the MAR assumption and for general missingness patterns. The core technical idea is to stratify observations by distinct missingness patterns and construct an estimator by appropriately weighting and aggregating pattern-specific information through a masking-and-imputation procedure on the complete cases. We provide theoretical guarantees of asymptotic normality of the proposed estimator and efficiency dominance over weighted complete-case analyses. Practically, the method affords simple implementations by leveraging existing weighted complete-case analysis software. Extensive simulations are carried out to validate theoretical results. The paper concludes with a brief discussion on practical implications, limitations, and potential future directions.
Generating Synthetic Electronic Health Record (EHR) Data: A Review with Benchmarking
Nov 06, 2024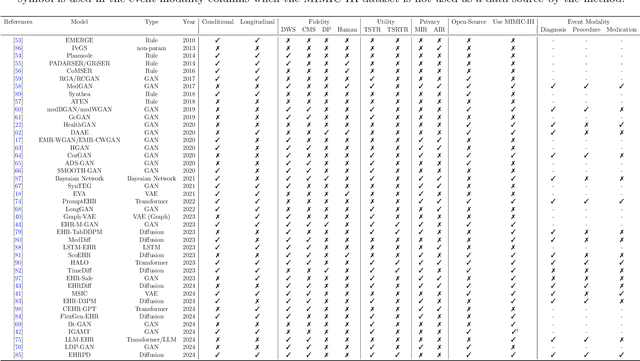
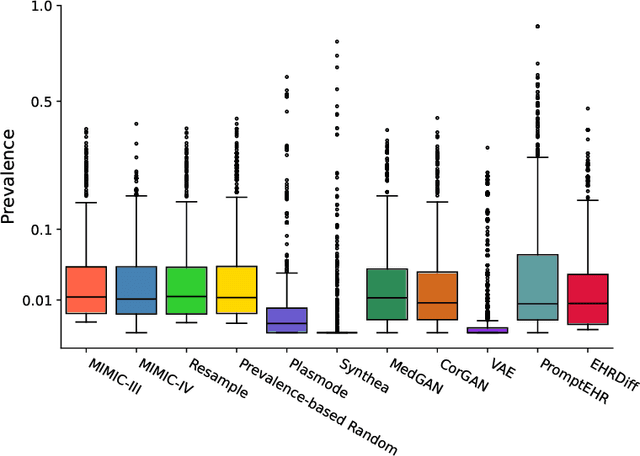
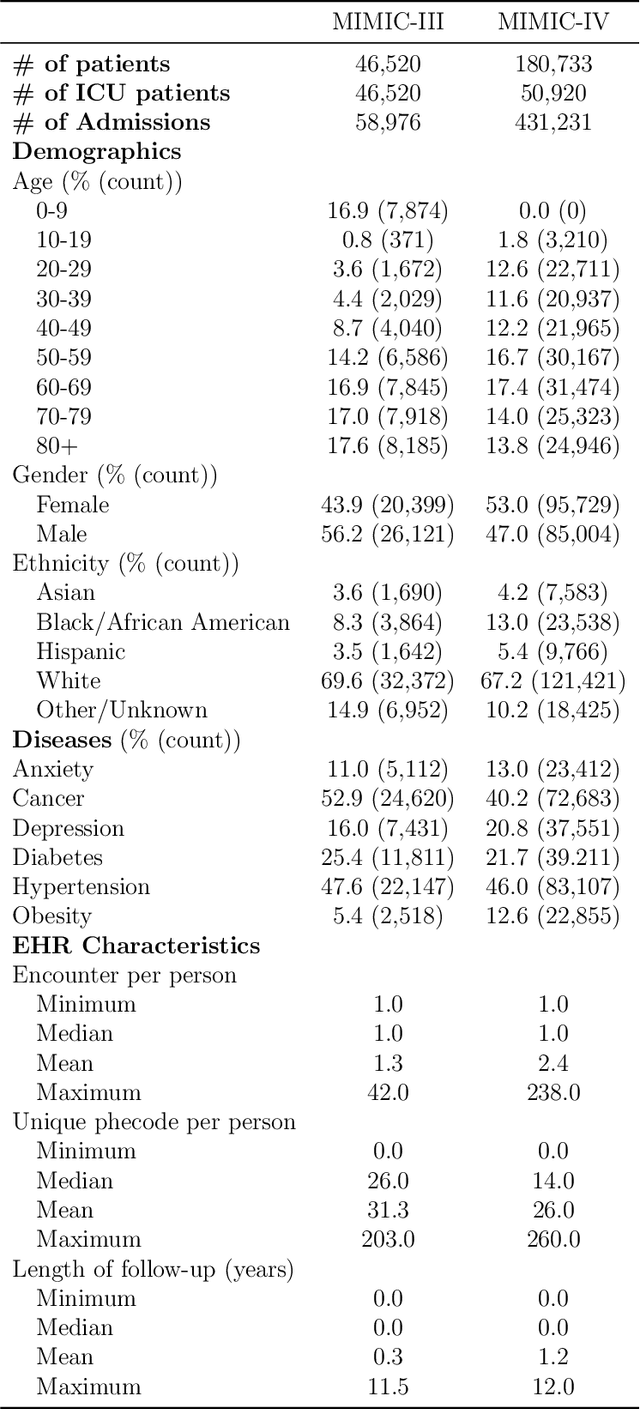
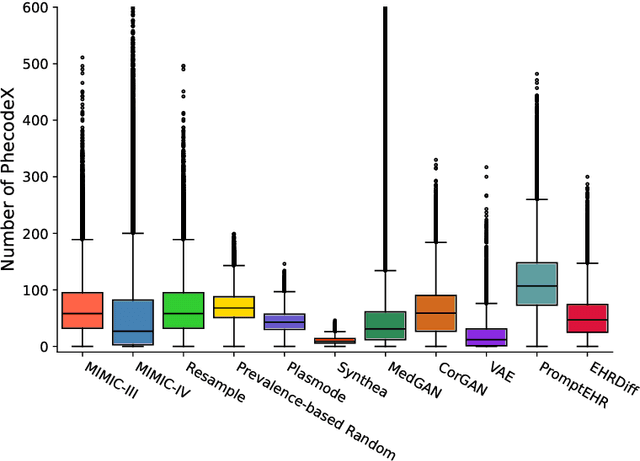
We conduct a scoping review of existing approaches for synthetic EHR data generation, and benchmark major methods with proposed open-source software to offer recommendations for practitioners. We search three academic databases for our scoping review. Methods are benchmarked on open-source EHR datasets, MIMIC-III/IV. Seven existing methods covering major categories and two baseline methods are implemented and compared. Evaluation metrics concern data fidelity, downstream utility, privacy protection, and computational cost. 42 studies are identified and classified into five categories. Seven open-source methods covering all categories are selected, trained on MIMIC-III, and evaluated on MIMIC-III or MIMIC-IV for transportability considerations. Among them, GAN-based methods demonstrate competitive performance in fidelity and utility on MIMIC-III; rule-based methods excel in privacy protection. Similar findings are observed on MIMIC-IV, except that GAN-based methods further outperform the baseline methods in preserving fidelity. A Python package, ``SynthEHRella'', is provided to integrate various choices of approaches and evaluation metrics, enabling more streamlined exploration and evaluation of multiple methods. We found that method choice is governed by the relative importance of the evaluation metrics in downstream use cases. We provide a decision tree to guide the choice among the benchmarked methods. Based on the decision tree, GAN-based methods excel when distributional shifts exist between the training and testing populations. Otherwise, CorGAN and MedGAN are most suitable for association modeling and predictive modeling, respectively. Future research should prioritize enhancing fidelity of the synthetic data while controlling privacy exposure, and comprehensive benchmarking of longitudinal or conditional generation methods.