 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyCFRL: A Python library for counterfactually fair offline reinforcement learning via sequential data preprocessing
Oct 08, 2025Reinforcement learning (RL) aims to learn and evaluate a sequential decision rule, often referred to as a "policy", that maximizes the population-level benefit in an environment across possibly infinitely many time steps. However, the sequential decisions made by an RL algorithm, while optimized to maximize overall population benefits, may disadvantage certain individuals who are in minority or socioeconomically disadvantaged groups. To address this problem, we introduce PyCFRL, a Python library for ensuring counterfactual fairness in offline RL. PyCFRL implements a novel data preprocessing algorithm for learning counterfactually fair RL policies from offline datasets and provides tools to evaluate the values and counterfactual unfairness levels of RL policies. We describe the high-level functionalities of PyCFRL and demonstrate one of its major use cases through a data example. The library is publicly available on PyPI and Github (https://github.com/JianhanZhang/PyCFRL), and detailed tutorials can be found in the PyCFRL documentation (https://pycfrl-documentation.netlify.app).
A Unified Framework for Inference with General Missingness Patterns and Machine Learning Imputation
Aug 21, 2025

Pre-trained machine learning (ML) predictions have been increasingly used to complement incomplete data to enable downstream scientific inquiries, but their naive integration risks biased inferences. Recently, multiple methods have been developed to provide valid inference with ML imputations regardless of prediction quality and to enhance efficiency relative to complete-case analyses. However, existing approaches are often limited to missing outcomes under a missing-completely-at-random (MCAR) assumption, failing to handle general missingness patterns under the more realistic missing-at-random (MAR) assumption. This paper develops a novel method which delivers valid statistical inference framework for general Z-estimation problems using ML imputations under the MAR assumption and for general missingness patterns. The core technical idea is to stratify observations by distinct missingness patterns and construct an estimator by appropriately weighting and aggregating pattern-specific information through a masking-and-imputation procedure on the complete cases. We provide theoretical guarantees of asymptotic normality of the proposed estimator and efficiency dominance over weighted complete-case analyses. Practically, the method affords simple implementations by leveraging existing weighted complete-case analysis software. Extensive simulations are carried out to validate theoretical results. The paper concludes with a brief discussion on practical implications, limitations, and potential future directions.
Counterfactually Fair Reinforcement Learning via Sequential Data Preprocessing
Jan 14, 2025

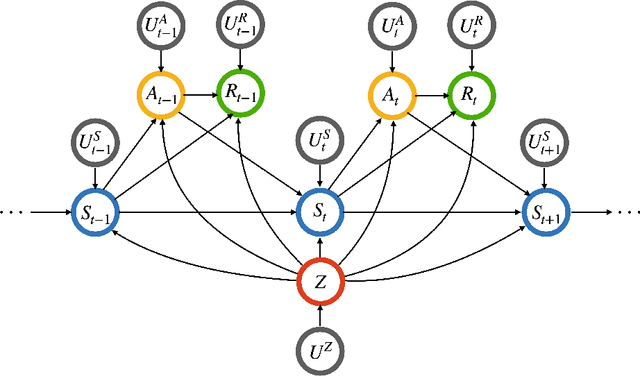

When applied in healthcare, reinforcement learning (RL) seeks to dynamically match the right interventions to subjects to maximize population benefit. However, the learned policy may disproportionately allocate efficacious actions to one subpopulation, creating or exacerbating disparities in other socioeconomically-disadvantaged subgroups. These biases tend to occur in multi-stage decision making and can be self-perpetuating, which if unaccounted for could cause serious unintended consequences that limit access to care or treatment benefit. Counterfactual fairness (CF) offers a promising statistical tool grounded in causal inference to formulate and study fairness. In this paper, we propose a general framework for fair sequential decision making. We theoretically characterize the optimal CF policy and prove its stationarity, which greatly simplifies the search for optimal CF policies by leveraging existing RL algorithms. The theory also motivates a sequential data preprocessing algorithm to achieve CF decision making under an additive noise assumption. We prove and then validate our policy learning approach in controlling unfairness and attaining optimal value through simulations. Analysis of a digital health dataset designed to reduce opioid misuse shows that our proposal greatly enhances fair access to counseling.
Generating Synthetic Electronic Health Record (EHR) Data: A Review with Benchmarking
Nov 06, 2024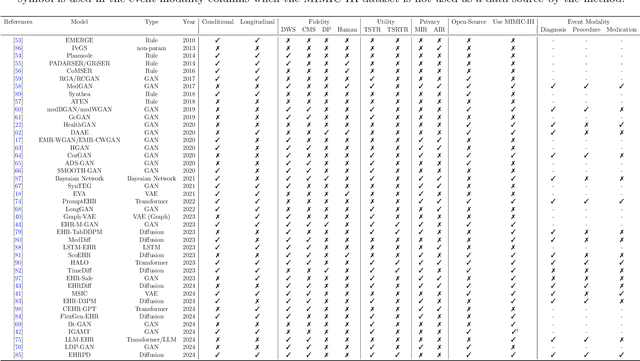
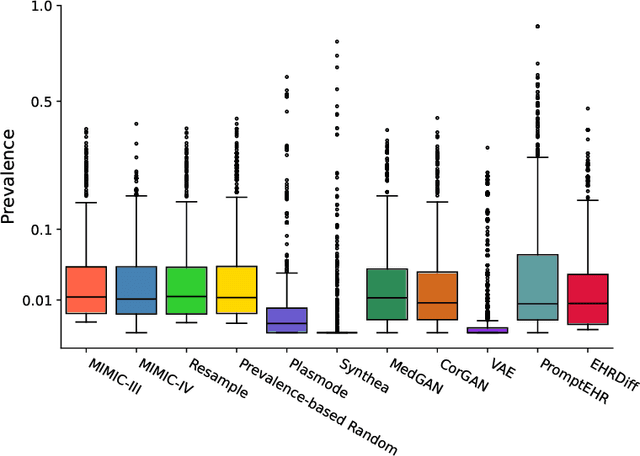
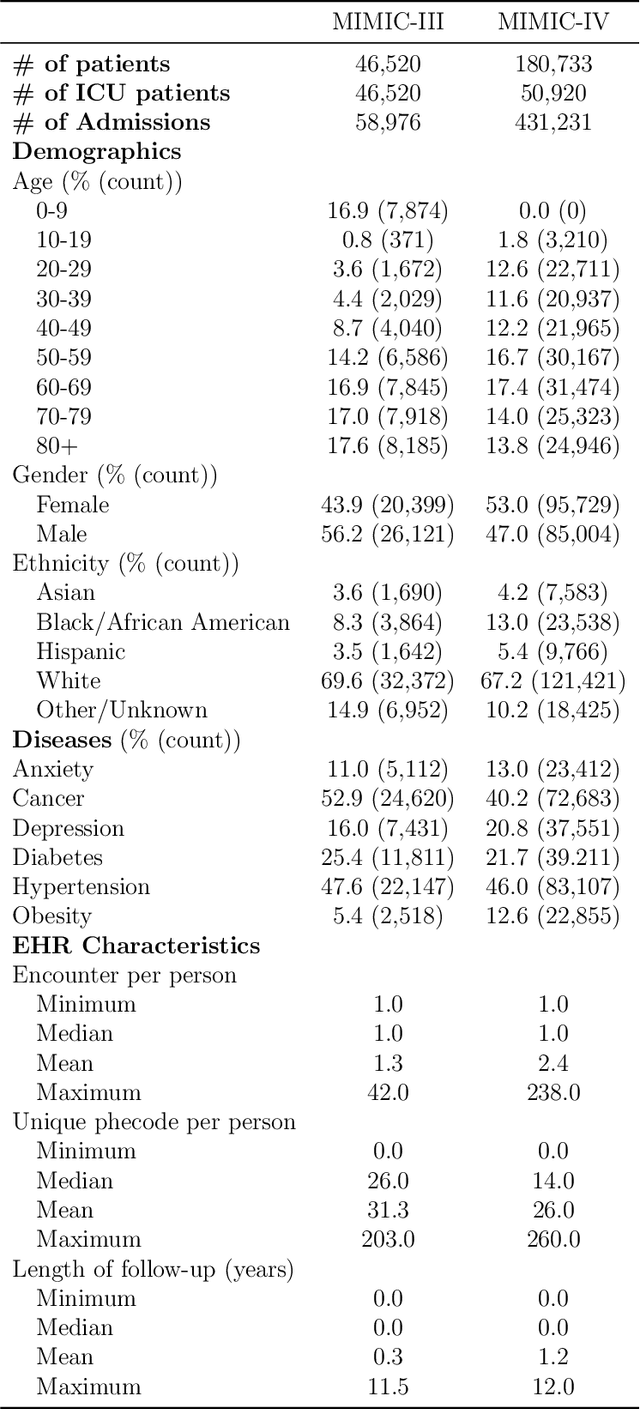
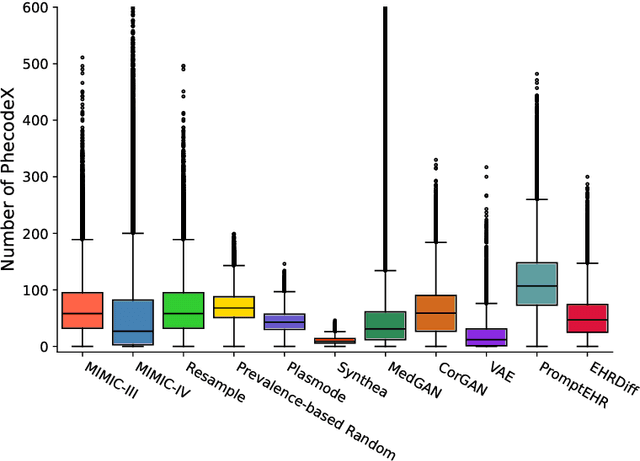
We conduct a scoping review of existing approaches for synthetic EHR data generation, and benchmark major methods with proposed open-source software to offer recommendations for practitioners. We search three academic databases for our scoping review. Methods are benchmarked on open-source EHR datasets, MIMIC-III/IV. Seven existing methods covering major categories and two baseline methods are implemented and compared. Evaluation metrics concern data fidelity, downstream utility, privacy protection, and computational cost. 42 studies are identified and classified into five categories. Seven open-source methods covering all categories are selected, trained on MIMIC-III, and evaluated on MIMIC-III or MIMIC-IV for transportability considerations. Among them, GAN-based methods demonstrate competitive performance in fidelity and utility on MIMIC-III; rule-based methods excel in privacy protection. Similar findings are observed on MIMIC-IV, except that GAN-based methods further outperform the baseline methods in preserving fidelity. A Python package, ``SynthEHRella'', is provided to integrate various choices of approaches and evaluation metrics, enabling more streamlined exploration and evaluation of multiple methods. We found that method choice is governed by the relative importance of the evaluation metrics in downstream use cases. We provide a decision tree to guide the choice among the benchmarked methods. Based on the decision tree, GAN-based methods excel when distributional shifts exist between the training and testing populations. Otherwise, CorGAN and MedGAN are most suitable for association modeling and predictive modeling, respectively. Future research should prioritize enhancing fidelity of the synthetic data while controlling privacy exposure, and comprehensive benchmarking of longitudinal or conditional generation methods.
A Reinforcement Learning Framework for Dynamic Mediation Analysis
Jan 31, 2023Mediation analysis learns the causal effect transmitted via mediator variables between treatments and outcomes and receives increasing attention in various scientific domains to elucidate causal relations. Most existing works focus on point-exposure studies where each subject only receives one treatment at a single time point. However, there are a number of applications (e.g., mobile health) where the treatments are sequentially assigned over time and the dynamic mediation effects are of primary interest. Proposing a reinforcement learning (RL) framework, we are the first to evaluate dynamic mediation effects in settings with infinite horizons. We decompose the average treatment effect into an immediate direct effect, an immediate mediation effect, a delayed direct effect, and a delayed mediation effect. Upon the identification of each effect component, we further develop robust and semi-parametrically efficient estimators under the RL framework to infer these causal effects. The superior performance of the proposed method is demonstrated through extensive numerical studies, theoretical results, and an analysis of a mobile health dataset.
Doubly Inhomogeneous Reinforcement Learning
Nov 12, 2022



This paper studies reinforcement learning (RL) in doubly inhomogeneous environments under temporal non-stationarity and subject heterogeneity. In a number of applications, it is commonplace to encounter datasets generated by system dynamics that may change over time and population, challenging high-quality sequential decision making. Nonetheless, most existing RL solutions require either temporal stationarity or subject homogeneity, which would result in sub-optimal policies if both assumptions were violated. To address both challenges simultaneously, we propose an original algorithm to determine the ``best data chunks" that display similar dynamics over time and across individuals for policy learning, which alternates between most recent change point detection and cluster identification. Our method is general, and works with a wide range of clustering and change point detection algorithms. It is multiply robust in the sense that it takes multiple initial estimators as input and only requires one of them to be consistent. Moreover, by borrowing information over time and population, it allows us to detect weaker signals and has better convergence properties when compared to applying the clustering algorithm per time or the change point detection algorithm per subject. Empirically, we demonstrate the usefulness of our method through extensive simulations and a real data application.
Dynamic Survival Transformers for Causal Inference with Electronic Health Records
Oct 25, 2022



In medicine, researchers often seek to infer the effects of a given treatment on patients' outcomes. However, the standard methods for causal survival analysis make simplistic assumptions about the data-generating process and cannot capture complex interactions among patient covariates. We introduce the Dynamic Survival Transformer (DynST), a deep survival model that trains on electronic health records (EHRs). Unlike previous transformers used in survival analysis, DynST can make use of time-varying information to predict evolving survival probabilities. We derive a semi-synthetic EHR dataset from MIMIC-III to show that DynST can accurately estimate the causal effect of a treatment intervention on restricted mean survival time (RMST). We demonstrate that DynST achieves better predictive and causal estimation than two alternative models.
Reinforcement Learning in Possibly Nonstationary Environments
Mar 03, 2022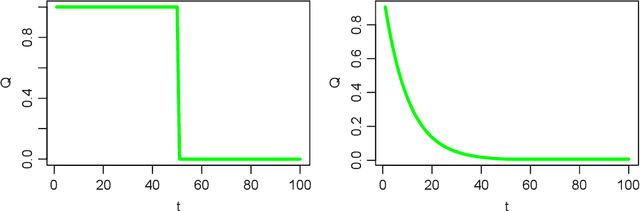

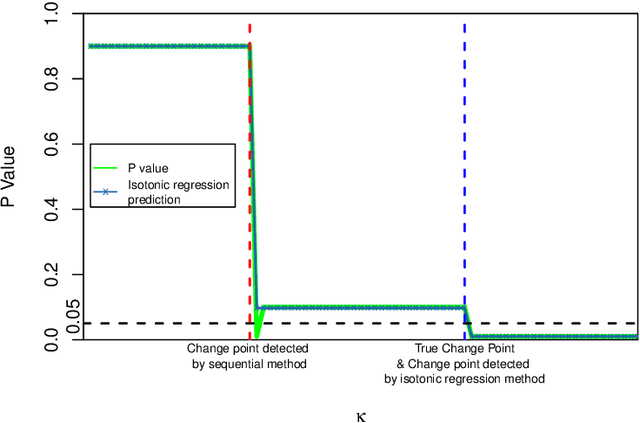

We consider reinforcement learning (RL) methods in offline nonstationary environments. Many existing RL algorithms in the literature rely on the stationarity assumption that requires the system transition and the reward function to be constant over time. However, the stationarity assumption is restrictive in practice and is likely to be violated in a number of applications, including traffic signal control, robotics and mobile health. In this paper, we develop a consistent procedure to test the nonstationarity of the optimal policy based on pre-collected historical data, without additional online data collection. Based on the proposed test, we further develop a sequential change point detection method that can be naturally coupled with existing state-of-the-art RL methods for policy optimisation in nonstationary environments. The usefulness of our method is illustrated by theoretical results, simulation studies, and a real data example from the 2018 Intern Health Study. A Python implementation of the proposed procedure is available at https://github.com/limengbinggz/CUSUM-RL
Kernel Deformed Exponential Families for Sparse Continuous Attention
Nov 12, 2021
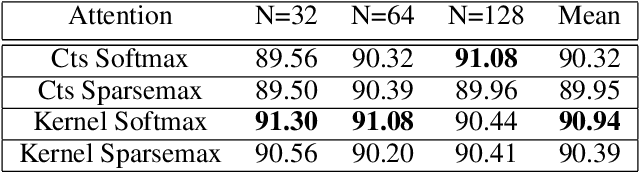
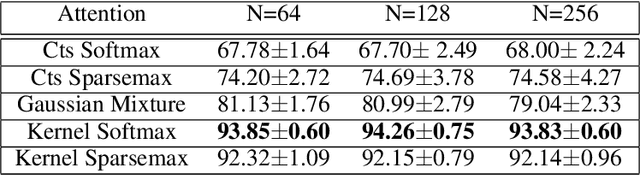
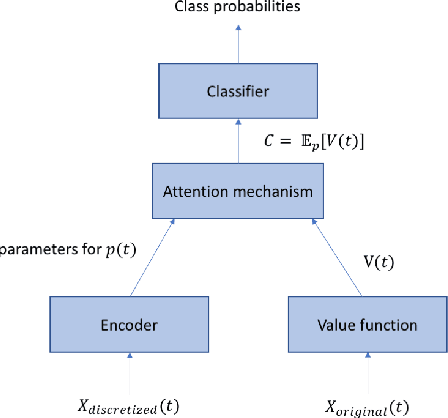
Attention mechanisms take an expectation of a data representation with respect to probability weights. This creates summary statistics that focus on important features. Recently, (Martins et al. 2020, 2021) proposed continuous attention mechanisms, focusing on unimodal attention densities from the exponential and deformed exponential families: the latter has sparse support. (Farinhas et al. 2021) extended this to use Gaussian mixture attention densities, which are a flexible class with dense support. In this paper, we extend this to two general flexible classes: kernel exponential families and our new sparse counterpart kernel deformed exponential families. Theoretically, we show new existence results for both kernel exponential and deformed exponential families, and that the deformed case has similar approximation capabilities to kernel exponential families. Experiments show that kernel deformed exponential families can attend to multiple compact regions of the data domain.
A Functional EM Algorithm for Panel Count Data with Missing Counts
Mar 28, 2020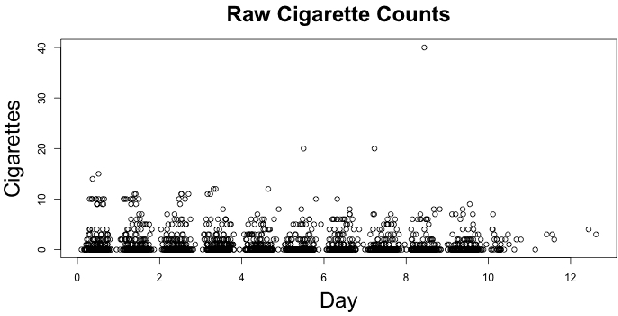
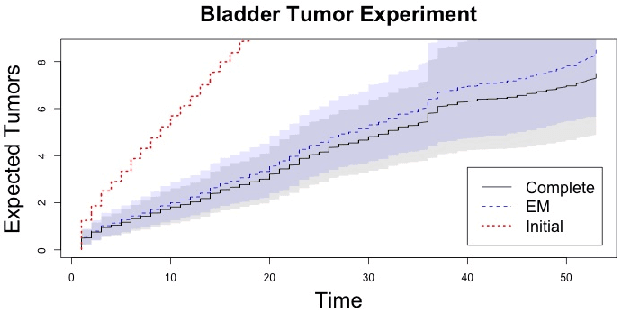
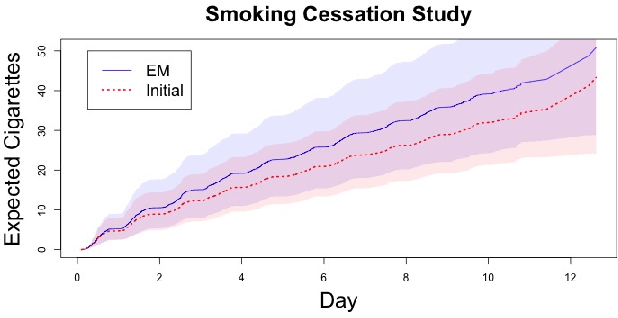
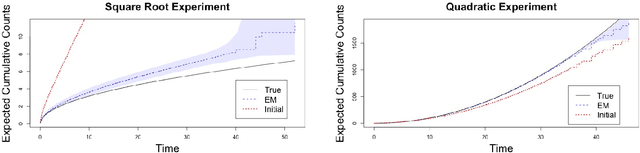
Panel count data is recurrent events data where counts of events are observed at discrete time points. Panel counts naturally describe self-reported behavioral data, and the occurrence of missing or unreliable reports is common. Unfortunately, no prior work has tackled the problem of missingness in this setting. We address this gap in the literature by developing a novel functional EM algorithm that can be used as a wrapper around several popular panel count mean function inference methods when some counts are missing. We provide a novel theoretical analysis of our method showing strong consistency. Extending the methods in (Balakrishnan et al., 2017, Wu et al. 2016), we show that the functional EM algorithm recovers the true mean function of the counting process. We accomplish this by developing alternative regularity conditions for our objective function in order to show convergence of the population EM algorithm. We prove strong consistency of the M-step, thus giving strong consistency guarantees for the finite sample EM algorithm. We present experimental results for synthetic data, synthetic missingness on real data, and a smoking cessation study, where we find that participants may underestimate cigarettes smoked by approximately 18.6% over a 12 day period.