 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForward and Backward State Abstractions for Off-policy Evaluation
Jun 27, 2024Off-policy evaluation (OPE) is crucial for evaluating a target policy's impact offline before its deployment. However, achieving accurate OPE in large state spaces remains challenging.This paper studies state abstractions-originally designed for policy learning-in the context of OPE. Our contributions are three-fold: (i) We define a set of irrelevance conditions central to learning state abstractions for OPE. (ii) We derive sufficient conditions for achieving irrelevance in Q-functions and marginalized importance sampling ratios, the latter obtained by constructing a time-reversed Markov decision process (MDP) based on the observed MDP. (iii) We propose a novel two-step procedure that sequentially projects the original state space into a smaller space, which substantially simplify the sample complexity of OPE arising from high cardinality.
Doubly Inhomogeneous Reinforcement Learning
Nov 12, 2022



This paper studies reinforcement learning (RL) in doubly inhomogeneous environments under temporal non-stationarity and subject heterogeneity. In a number of applications, it is commonplace to encounter datasets generated by system dynamics that may change over time and population, challenging high-quality sequential decision making. Nonetheless, most existing RL solutions require either temporal stationarity or subject homogeneity, which would result in sub-optimal policies if both assumptions were violated. To address both challenges simultaneously, we propose an original algorithm to determine the ``best data chunks" that display similar dynamics over time and across individuals for policy learning, which alternates between most recent change point detection and cluster identification. Our method is general, and works with a wide range of clustering and change point detection algorithms. It is multiply robust in the sense that it takes multiple initial estimators as input and only requires one of them to be consistent. Moreover, by borrowing information over time and population, it allows us to detect weaker signals and has better convergence properties when compared to applying the clustering algorithm per time or the change point detection algorithm per subject. Empirically, we demonstrate the usefulness of our method through extensive simulations and a real data application.
abess: A Fast Best Subset Selection Library in Python and R
Oct 19, 2021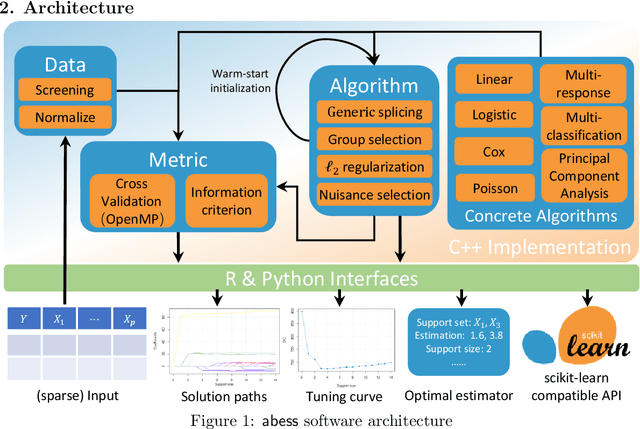


We introduce a new library named abess that implements a unified framework of best-subset selection for solving diverse machine learning problems, e.g., linear regression, classification, and principal component analysis. Particularly, the abess certifiably gets the optimal solution within polynomial times under the linear model. Our efficient implementation allows abess to attain the solution of best-subset selection problems as fast as or even 100x faster than existing competing variable (model) selection toolboxes. Furthermore, it supports common variants like best group subset selection and $\ell_2$ regularized best-subset selection. The core of the library is programmed in C++. For ease of use, a Python library is designed for conveniently integrating with scikit-learn, and it can be installed from the Python library Index. In addition, a user-friendly R library is available at the Comprehensive R Archive Network. The source code is available at: https://github.com/abess-team/abess.