 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-Doc : Visual questions answers with Documents
May 31, 2022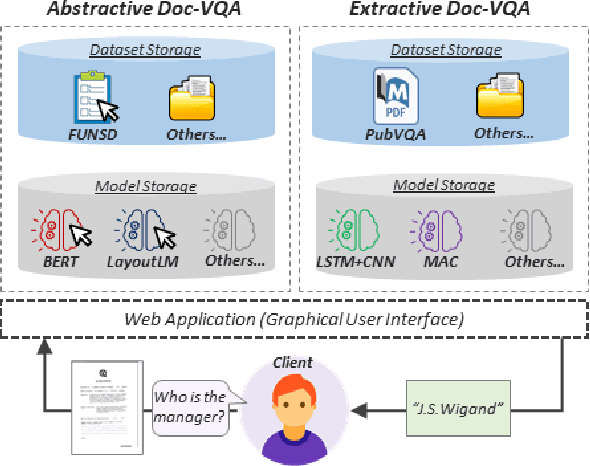


We propose V-Doc, a question-answering tool using document images and PDF, mainly for researchers and general non-deep learning experts looking to generate, process, and understand the document visual question answering tasks. The V-Doc supports generating and using both extractive and abstractive question-answer pairs using documents images. The extractive QA selects a subset of tokens or phrases from the document contents to predict the answers, while the abstractive QA recognises the language in the content and generates the answer based on the trained model. Both aspects are crucial to understanding the documents, especially in an image format. We include a detailed scenario of question generation for the abstractive QA task. V-Doc supports a wide range of datasets and models, and is highly extensible through a declarative, framework-agnostic platform.
abess: A Fast Best Subset Selection Library in Python and R
Oct 19, 2021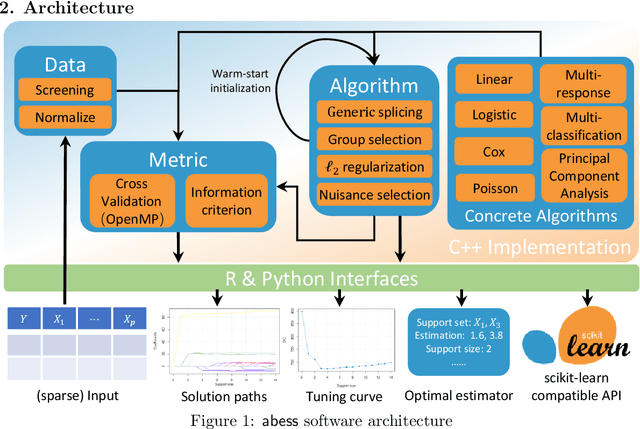


We introduce a new library named abess that implements a unified framework of best-subset selection for solving diverse machine learning problems, e.g., linear regression, classification, and principal component analysis. Particularly, the abess certifiably gets the optimal solution within polynomial times under the linear model. Our efficient implementation allows abess to attain the solution of best-subset selection problems as fast as or even 100x faster than existing competing variable (model) selection toolboxes. Furthermore, it supports common variants like best group subset selection and $\ell_2$ regularized best-subset selection. The core of the library is programmed in C++. For ease of use, a Python library is designed for conveniently integrating with scikit-learn, and it can be installed from the Python library Index. In addition, a user-friendly R library is available at the Comprehensive R Archive Network. The source code is available at: https://github.com/abess-team/abess.
Certifiably Polynomial Algorithm for Best Group Subset Selection
Apr 23, 2021

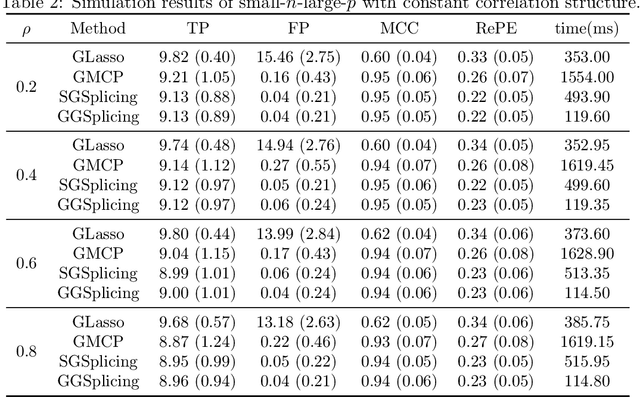

Best group subset selection aims to choose a small part of non-overlapping groups to achieve the best interpretability on the response variable. It is practically attractive for group variable selection; however, due to the computational intractability in high dimensionality setting, it doesn't catch enough attention. To fill the blank of efficient algorithms for best group subset selection, in this paper, we propose a group-splicing algorithm that iteratively detects effective groups and excludes the helpless ones. Moreover, coupled with a novel Bayesian group information criterion, an adaptive algorithm is developed to determine the true group subset size. It is certifiable that our algorithms enable identifying the optimal group subset in polynomial time under mild conditions. We demonstrate the efficiency and accuracy of our proposal by comparing state-of-the-art algorithms on both synthetic and real-world datasets.