 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-based phenomenological characterization of cross-modal bias in multimodal models
Feb 24, 2026The term 'algorithmic fairness' is used to evaluate whether AI models operate fairly in both comparative (where fairness is understood as formal equality, such as "treat like cases as like") and non-comparative (where unfairness arises from the model's inaccuracy, arbitrariness, or inscrutability) contexts. Recent advances in multimodal large language models (MLLMs) are breaking new ground in multimodal understanding, reasoning, and generation; however, we argue that inconspicuous distortions arising from complex multimodal interaction dynamics can lead to systematic bias. The purpose of this position paper is twofold: first, it is intended to acquaint AI researchers with phenomenological explainable approaches that rely on the physical entities that the machine experiences during training/inference, as opposed to the traditional cognitivist symbolic account or metaphysical approaches; second, it is to state that this phenomenological doctrine will be practically useful for tackling algorithmic fairness issues in MLLMs. We develop a surrogate physics-based model that describes transformer dynamics (i.e., semantic network structure and self-/cross-attention) to analyze the dynamics of cross-modal bias in MLLM, which are not fully captured by conventional embedding- or representation-level analyses. We support this position through multi-input diagnostic experiments: 1) perturbation-based analyses of emotion classification using Qwen2.5-Omni and Gemma 3n, and 2) dynamical analysis of Lorenz chaotic time-series prediction through the physical surrogate. Across two architecturally distinct MLLMs, we show that multimodal inputs can reinforce modality dominance rather than mitigate it, as revealed by structured error-attractor patterns under systematic label perturbation, complemented by dynamical analysis.
FiLoRA: Focus-and-Ignore LoRA for Controllable Feature Reliance
Feb 02, 2026Multimodal foundation models integrate heterogeneous signals across modalities, yet it remains poorly understood how their predictions depend on specific internal feature groups and whether such reliance can be deliberately controlled. Existing studies of shortcut and spurious behavior largely rely on post hoc analyses or feature removal, offering limited insight into whether reliance can be modulated without altering task semantics. We introduce FiLoRA (Focus-and-Ignore LoRA), an instruction-conditioned, parameter-efficient adaptation framework that enables explicit control over internal feature reliance while keeping the predictive objective fixed. FiLoRA decomposes adaptation into feature group-aligned LoRA modules and applies instruction-conditioned gating, allowing natural language instructions to act as computation-level control signals rather than task redefinitions. Across text--image and audio--visual benchmarks, we show that instruction-conditioned gating induces consistent and causal shifts in internal computation, selectively amplifying or suppressing core and spurious feature groups without modifying the label space or training objective. Further analyses demonstrate that FiLoRA yields improved robustness under spurious feature interventions, revealing a principled mechanism to regulate reliance beyond correlation-driven learning.
DAViD: Domain Adaptive Visually-Rich Document Understanding with Synthetic Insights
Oct 02, 2024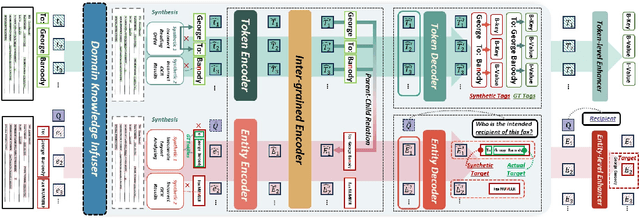
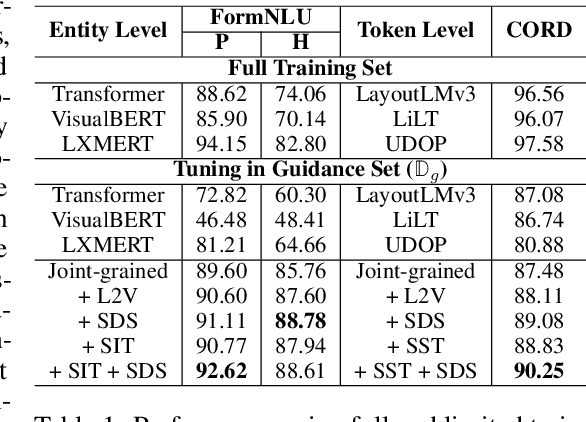
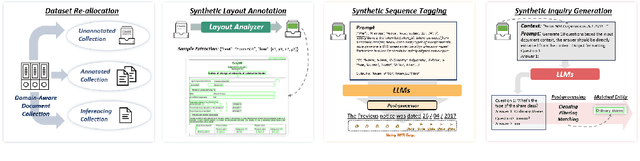
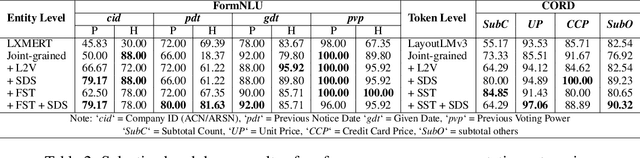
Visually-Rich Documents (VRDs), encompassing elements like charts, tables, and references, convey complex information across various fields. However, extracting information from these rich documents is labor-intensive, especially given their inconsistent formats and domain-specific requirements. While pretrained models for VRD Understanding have progressed, their reliance on large, annotated datasets limits scalability. This paper introduces the Domain Adaptive Visually-rich Document Understanding (DAViD) framework, which utilises machine-generated synthetic data for domain adaptation. DAViD integrates fine-grained and coarse-grained document representation learning and employs synthetic annotations to reduce the need for costly manual labelling. By leveraging pretrained models and synthetic data, DAViD achieves competitive performance with minimal annotated datasets. Extensive experiments validate DAViD's effectiveness, demonstrating its ability to efficiently adapt to domain-specific VRDU tasks.
PEACH: Pretrained-embedding Explanation Across Contextual and Hierarchical Structure
Apr 21, 2024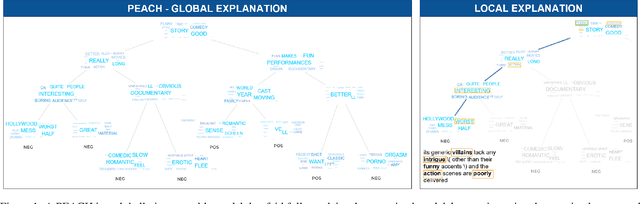
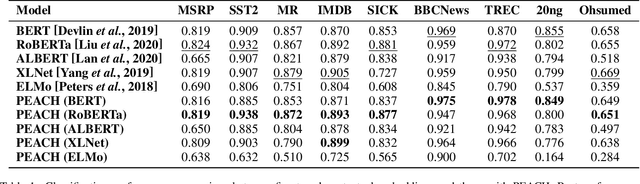
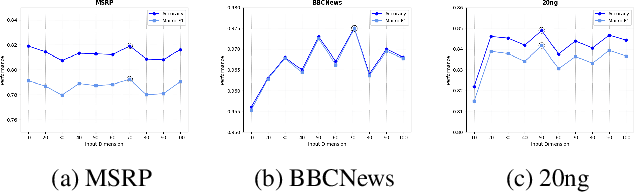

In this work, we propose a novel tree-based explanation technique, PEACH (Pretrained-embedding Explanation Across Contextual and Hierarchical Structure), that can explain how text-based documents are classified by using any pretrained contextual embeddings in a tree-based human-interpretable manner. Note that PEACH can adopt any contextual embeddings of the PLMs as a training input for the decision tree. Using the proposed PEACH, we perform a comprehensive analysis of several contextual embeddings on nine different NLP text classification benchmarks. This analysis demonstrates the flexibility of the model by applying several PLM contextual embeddings, its attribute selections, scaling, and clustering methods. Furthermore, we show the utility of explanations by visualising the feature selection and important trend of text classification via human-interpretable word-cloud-based trees, which clearly identify model mistakes and assist in dataset debugging. Besides interpretability, PEACH outperforms or is similar to those from pretrained models.
PDFVQA: A New Dataset for Real-World VQA on Documents
Apr 24, 2023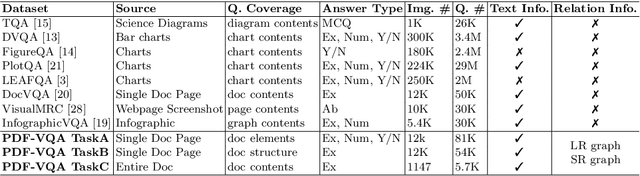
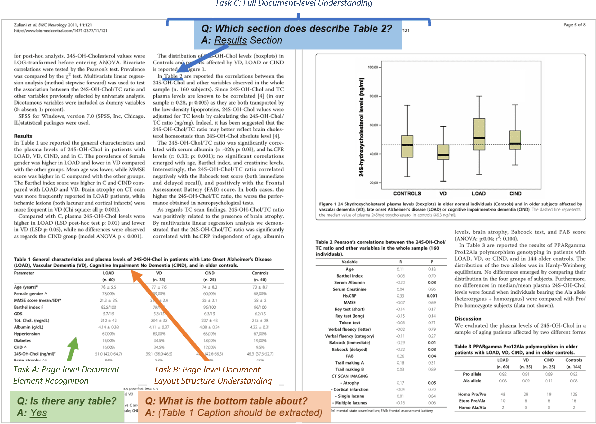
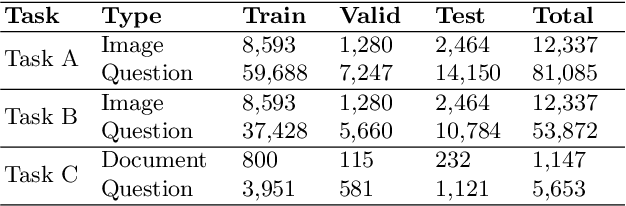
Document-based Visual Question Answering examines the document understanding of document images in conditions of natural language questions. We proposed a new document-based VQA dataset, PDF-VQA, to comprehensively examine the document understanding from various aspects, including document element recognition, document layout structural understanding as well as contextual understanding and key information extraction. Our PDF-VQA dataset extends the current scale of document understanding that limits on the single document page to the new scale that asks questions over the full document of multiple pages. We also propose a new graph-based VQA model that explicitly integrates the spatial and hierarchically structural relationships between different document elements to boost the document structural understanding. The performances are compared with several baselines over different question types and tasks\footnote{The full dataset will be released after paper acceptance.
Form-NLU: Dataset for the Form Language Understanding
Apr 05, 2023Compared to general document analysis tasks, form document structure understanding and retrieval are challenging. Form documents are typically made by two types of authors; A form designer, who develops the form structure and keys, and a form user, who fills out form values based on the provided keys. Hence, the form values may not be aligned with the form designer's intention (structure and keys) if a form user gets confused. In this paper, we introduce Form-NLU, the first novel dataset for form structure understanding and its key and value information extraction, interpreting the form designer's intent and the alignment of user-written value on it. It consists of 857 form images, 6k form keys and values, and 4k table keys and values. Our dataset also includes three form types: digital, printed, and handwritten, which cover diverse form appearances and layouts. We propose a robust positional and logical relation-based form key-value information extraction framework. Using this dataset, Form-NLU, we first examine strong object detection models for the form layout understanding, then evaluate the key information extraction task on the dataset, providing fine-grained results for different types of forms and keys. Furthermore, we examine it with the off-the-shelf pdf layout extraction tool and prove its feasibility in real-world cases.
PiggyBack: Pretrained Visual Question Answering Environment for Backing up Non-deep Learning Professionals
Dec 01, 2022


We propose a PiggyBack, a Visual Question Answering platform that allows users to apply the state-of-the-art visual-language pretrained models easily. The PiggyBack supports the full stack of visual question answering tasks, specifically data processing, model fine-tuning, and result visualisation. We integrate visual-language models, pretrained by HuggingFace, an open-source API platform of deep learning technologies; however, it cannot be runnable without programming skills or deep learning understanding. Hence, our PiggyBack supports an easy-to-use browser-based user interface with several deep learning visual language pretrained models for general users and domain experts. The PiggyBack includes the following benefits: Free availability under the MIT License, Portability due to web-based and thus runs on almost any platform, A comprehensive data creation and processing technique, and ease of use on deep learning-based visual language pretrained models. The demo video is available on YouTube and can be found at https://youtu.be/iz44RZ1lF4s.
V-Doc : Visual questions answers with Documents
May 31, 2022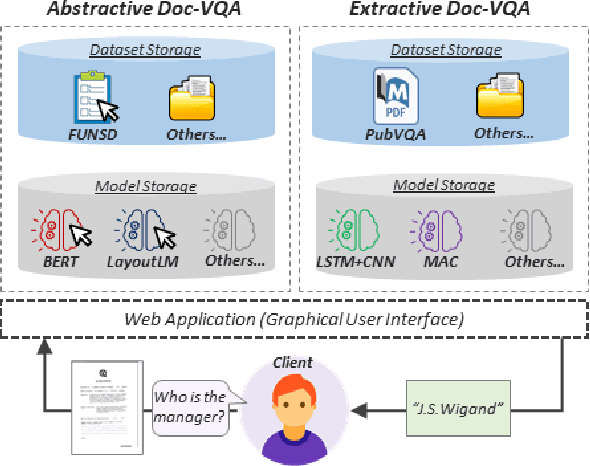


We propose V-Doc, a question-answering tool using document images and PDF, mainly for researchers and general non-deep learning experts looking to generate, process, and understand the document visual question answering tasks. The V-Doc supports generating and using both extractive and abstractive question-answer pairs using documents images. The extractive QA selects a subset of tokens or phrases from the document contents to predict the answers, while the abstractive QA recognises the language in the content and generates the answer based on the trained model. Both aspects are crucial to understanding the documents, especially in an image format. We include a detailed scenario of question generation for the abstractive QA task. V-Doc supports a wide range of datasets and models, and is highly extensible through a declarative, framework-agnostic platform.