 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuan-Game: Industrial-grade Intelligent Game Creation Model
May 20, 2025Intelligent game creation represents a transformative advancement in game development, utilizing generative artificial intelligence to dynamically generate and enhance game content. Despite notable progress in generative models, the comprehensive synthesis of high-quality game assets, including both images and videos, remains a challenging frontier. To create high-fidelity game content that simultaneously aligns with player preferences and significantly boosts designer efficiency, we present Hunyuan-Game, an innovative project designed to revolutionize intelligent game production. Hunyuan-Game encompasses two primary branches: image generation and video generation. The image generation component is built upon a vast dataset comprising billions of game images, leading to the development of a group of customized image generation models tailored for game scenarios: (1) General Text-to-Image Generation. (2) Game Visual Effects Generation, involving text-to-effect and reference image-based game visual effect generation. (3) Transparent Image Generation for characters, scenes, and game visual effects. (4) Game Character Generation based on sketches, black-and-white images, and white models. The video generation component is built upon a comprehensive dataset of millions of game and anime videos, leading to the development of five core algorithmic models, each targeting critical pain points in game development and having robust adaptation to diverse game video scenarios: (1) Image-to-Video Generation. (2) 360 A/T Pose Avatar Video Synthesis. (3) Dynamic Illustration Generation. (4) Generative Video Super-Resolution. (5) Interactive Game Video Generation. These image and video generation models not only exhibit high-level aesthetic expression but also deeply integrate domain-specific knowledge, establishing a systematic understanding of diverse game and anime art styles.
Hunyuan-DiT: A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding
May 14, 2024



We present Hunyuan-DiT, a text-to-image diffusion transformer with fine-grained understanding of both English and Chinese. To construct Hunyuan-DiT, we carefully design the transformer structure, text encoder, and positional encoding. We also build from scratch a whole data pipeline to update and evaluate data for iterative model optimization. For fine-grained language understanding, we train a Multimodal Large Language Model to refine the captions of the images. Finally, Hunyuan-DiT can perform multi-turn multimodal dialogue with users, generating and refining images according to the context. Through our holistic human evaluation protocol with more than 50 professional human evaluators, Hunyuan-DiT sets a new state-of-the-art in Chinese-to-image generation compared with other open-source models. Code and pretrained models are publicly available at github.com/Tencent/HunyuanDiT
PDF-MVQA: A Dataset for Multimodal Information Retrieval in-based Visual Question Answering
Apr 19, 2024



Document Question Answering (QA) presents a challenge in understanding visually-rich documents (VRD), particularly those dominated by lengthy textual content like research journal articles. Existing studies primarily focus on real-world documents with sparse text, while challenges persist in comprehending the hierarchical semantic relations among multiple pages to locate multimodal components. To address this gap, we propose PDF-MVQA, which is tailored for research journal articles, encompassing multiple pages and multimodal information retrieval. Unlike traditional machine reading comprehension (MRC) tasks, our approach aims to retrieve entire paragraphs containing answers or visually rich document entities like tables and figures. Our contributions include the introduction of a comprehensive PDF Document VQA dataset, allowing the examination of semantically hierarchical layout structures in text-dominant documents. We also present new VRD-QA frameworks designed to grasp textual contents and relations among document layouts simultaneously, extending page-level understanding to the entire multi-page document. Through this work, we aim to enhance the capabilities of existing vision-and-language models in handling challenges posed by text-dominant documents in VRD-QA.
Form-NLU: Dataset for the Form Language Understanding
Apr 05, 2023Compared to general document analysis tasks, form document structure understanding and retrieval are challenging. Form documents are typically made by two types of authors; A form designer, who develops the form structure and keys, and a form user, who fills out form values based on the provided keys. Hence, the form values may not be aligned with the form designer's intention (structure and keys) if a form user gets confused. In this paper, we introduce Form-NLU, the first novel dataset for form structure understanding and its key and value information extraction, interpreting the form designer's intent and the alignment of user-written value on it. It consists of 857 form images, 6k form keys and values, and 4k table keys and values. Our dataset also includes three form types: digital, printed, and handwritten, which cover diverse form appearances and layouts. We propose a robust positional and logical relation-based form key-value information extraction framework. Using this dataset, Form-NLU, we first examine strong object detection models for the form layout understanding, then evaluate the key information extraction task on the dataset, providing fine-grained results for different types of forms and keys. Furthermore, we examine it with the off-the-shelf pdf layout extraction tool and prove its feasibility in real-world cases.
MEnet: A Metric Expression Network for Salient Object Segmentation
May 15, 2018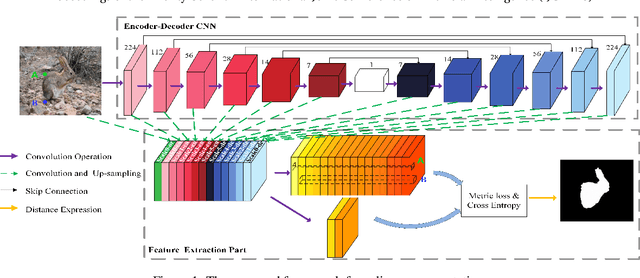



Recent CNN-based saliency models have achieved great performance on public datasets, however, most of them are sensitive to distortion (e.g., noise, compression). In this paper, an end-to-end generic salient object segmentation model called Metric Expression Network (MEnet) is proposed to overcome this drawback. Within this architecture, we construct a new topological metric space, with the implicit metric being determined by the deep network. In this way, we succeed in grouping all the pixels within the observed image semantically within this latent space into two regions: a salient region and a non-salient region. With this method, all feature extractions are carried out at the pixel level, which makes the output boundaries of salient object fine-grained. Experimental results show that the proposed metric can generate robust salient maps that allow for object segmentation. By testing the method on several public benchmarks, we show that the performance of MEnet has achieved good results. Furthermore, the proposed method outperforms previous CNN-based methods on distorted images.
Clearing the Skies: A deep network architecture for single-image rain removal
Feb 06, 2017



We introduce a deep network architecture called DerainNet for removing rain streaks from an image. Based on the deep convolutional neural network (CNN), we directly learn the mapping relationship between rainy and clean image detail layers from data. Because we do not possess the ground truth corresponding to real-world rainy images, we synthesize images with rain for training. In contrast to other common strategies that increase depth or breadth of the network, we use image processing domain knowledge to modify the objective function and improve deraining with a modestly-sized CNN. Specifically, we train our DerainNet on the detail (high-pass) layer rather than in the image domain. Though DerainNet is trained on synthetic data, we find that the learned network translates very effectively to real-world images for testing. Moreover, we augment the CNN framework with image enhancement to improve the visual results. Compared with state-of-the-art single image de-raining methods, our method has improved rain removal and much faster computation time after network training.